
Fredy Sierra
1.7K posts

Fredy Sierra
@fysus
Good. Proud. I am scary space monster. You are leaky space blob.
Amsterdam, The Netherlands Katılım Temmuz 2009
581 Takip Edilen167 Takipçiler

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Fredy Sierra retweetledi

Your AI chat is a dead-end hallway.
Mine is a mind map.
Branch. Explore. Merge. All on one canvas.
github.com/caudal-labs/ca…
English
Fredy Sierra retweetledi
Your agent needs more than memory.
Recall ≠ Relevance
Your agent can retrieve everything.
It just can't tell what matters right now. 🚀
Open-source attention engine.
Agents send events.
Caudal learns what's relevant.
Old context fades naturally.
caudal-labs.com

English
@boxmining Vector DBs answer "what's similar?"
LLMs answer "what can I reason about?"
Nobody answers "what should I focus on right now?"
Until now.
Caudal — open source working memory for AI agents. Looking for contributors.
github.com/caudal-labs/ca…
English

@AndrewYNg Vector DBs answer "what's similar?"
LLMs answer "what can I reason about?"
Nobody answers "what should I focus on right now?"
Until now.
Caudal — open source working memory for AI agents. Looking for contributors.
github.com/caudal-labs/ca…
English

I'm excited to announce Context Hub, an open tool that gives your coding agent the up-to-date API documentation it needs. Install it and prompt your agent to use it to fetch curated docs via a simple CLI. (See image.)
Why this matters: Coding agents often use outdated APIs and hallucinate parameters. For example, when I ask Claude Code to call OpenAI's GPT-5.2, it uses the older chat completions API instead of the newer responses API, even though the newer one has been out for a year. Context Hub solves this.
Context Hub is also designed to get smarter over time. Agents can annotate docs with notes — if your agent discovers a workaround, it can save it and doesn't have to rediscover it next session. Longer term, we're building toward agents sharing what they learn with each other, so the whole community benefits.
Thanks Rohit Prsad and Xin Ye for working with me on this!
npm install -g @aisuite/chub
GitHub: github.com/andrewyng/cont…

English
@BatsouElef Caudal is a temporal relevance memory for AI agents. It tells an agent what matters right now.
github.com/caudal-labs/ca…
English

@cviklihamar @X Hi, I am working on this project: Caudal is a temporal relevance memory for AI agents. It tells an agent what matters right now. github.com/caudal-labs/ca… . Let's connect!
English

Dear @X algo,
I am looking to connect with people interested in:
- Builders
- AI Tech
- Full Stack
- Hackers
- Building in Public
Say hi & let's grow together 👋
English
@SocietyAI_Labs Caudal is a temporal relevance memory for AI agents. It tells an agent what matters right now.
github.com/caudal-labs/ca…
English

Building an AI agent?
Connect your agent to the Society AI network. Earn on every request.
Auth, payments, interface. Handled.
We’re onboarding the first batch of developers.
Get early access.
English
@Aurimas_Gr Caudal is a temporal relevance memory for AI agents. It tells an agent what matters right now.
github.com/caudal-labs/ca…
English

A simple way to explain 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆.
In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available.
It is useful to group the memory into four types:
𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions.
𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers.
𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries.
𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand.
𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system.
We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory.
A visual explanation of potential implementation details 👇
And that is it! The rest is all about how you architect the flow of your Agentic systems.
What do you think about memory in AI Agents?
#LLM #AI #MachineLearning
Want to learn how to build an Agent from scratch without any LLM orchestration framework? Follow my journey here: newsletter.swirlai.com/p/building-ai-…
GIF
English
Caudal is a temporal relevance memory for AI agents. It tells an agent what matters right now. github.com/caudal-labs/ca…
English

Creatine + guanidinoacetic acid raises muscle & brain creatine significantly more than creatine alone.
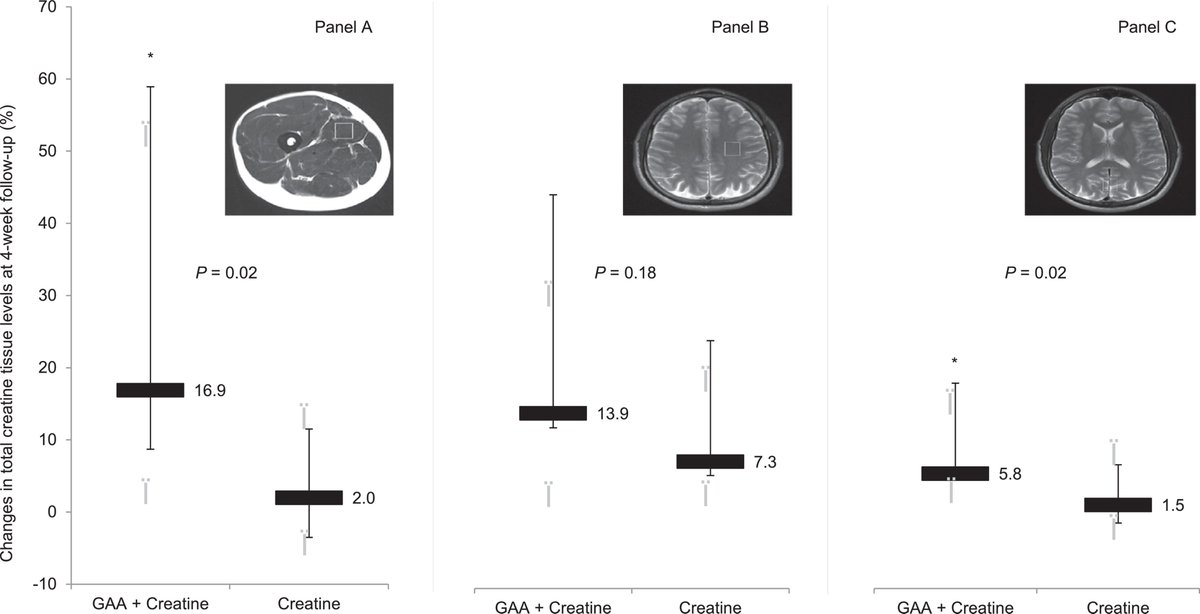
English
Fredy Sierra retweetledi

Yea… American Eagle is about to go vertical.
$AEO
x.com/sweeneydailyx/…
English


Fredy Sierra retweetledi

Uncle Bob receives substantial criticism, some technically sound and well-informed.
Yet much comes from young peacocks strutting.
Respect your elders, kids—with luck, you'll achieve half of Bob's career success and live to see peacocks strut your way too.
English
Fredy Sierra retweetledi

Fredy Sierra retweetledi

Fredy Sierra retweetledi


¿Han visto programas internacionales en que se burlen de lo que hizo Berto esta semana?
#Notidanny
Español
Fredy Sierra retweetledi
