Roberto Garcia retweetledi
Roberto Garcia
29 posts


Roberto Garcia
@garctrob
Computational Math @HazyResearch @ Stanford | Prev @ HRT, Jane Street
Katılım Ocak 2024
82 Takip Edilen37 Takipçiler

Roberto Garcia retweetledi

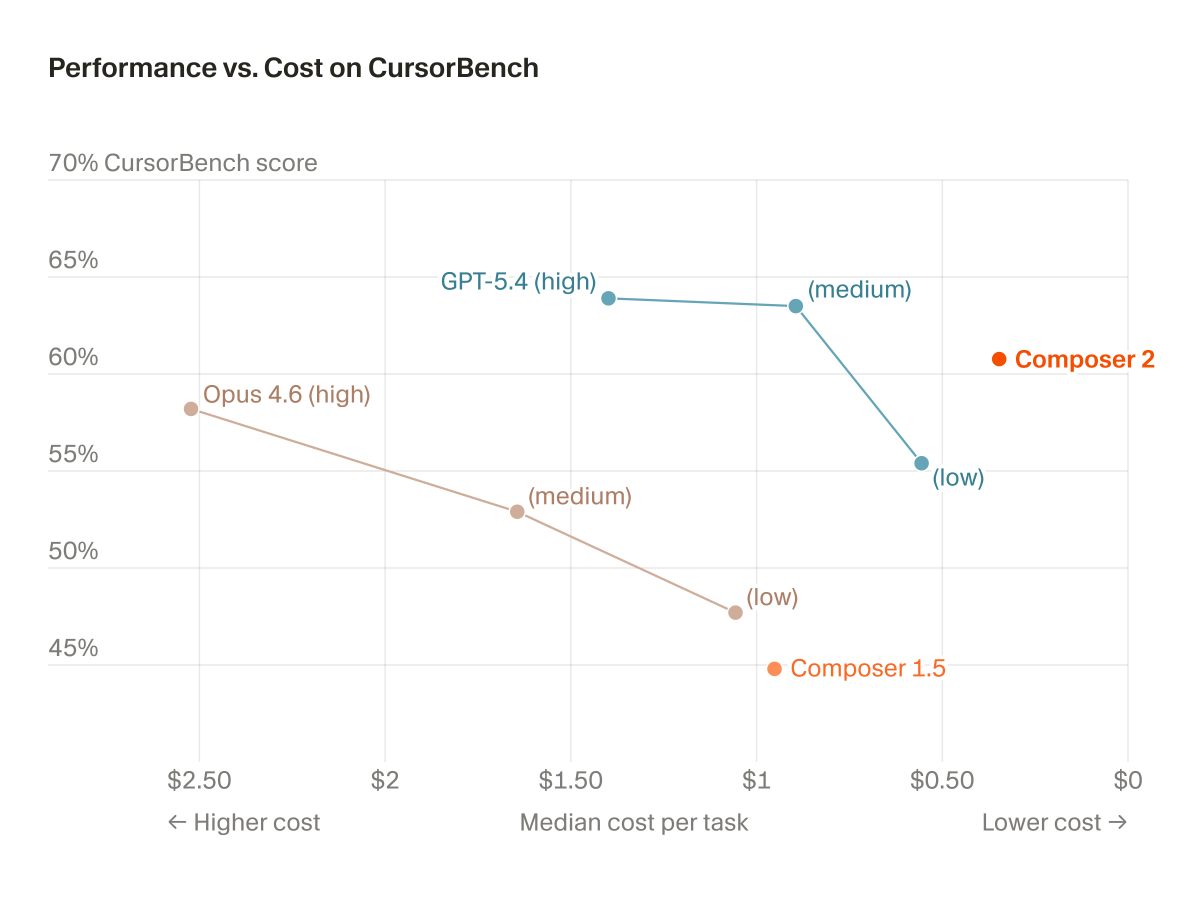
Congrats @cursor_ai on launching Composer 2 today! Really gratifying working with them to make it ready for launch today and to power the Composer 2 Fast endpoint on @togethercompute.
A couple things make this one really cool for me:
It's really really good. Seriously, try it!
It's a really gratifying validation of kernel research we've been doing for years - training kernels written in ThunderKittens (by my old lab mate @stuart_sul), and inference kernels in our stack to make it so blazing fast.
Looking forward to what comes next!
Cursor@cursor_ai
Composer 2 is now available in Cursor.
English
Roberto Garcia retweetledi

Personal AI should run on your personal devices. So, we built OpenJarvis: a personal AI that lives, learns, and works on-device.
Try it today and top the OpenJarvis Leaderboard for a chance to win a Mac Mini!
Collab w/ @Avanika15, John Hennessy, @HazyResearch, and @Azaliamirh. Details in thread.

English
Roberto Garcia retweetledi

(1/7) We're releasing ThunderKittens 2.0! Faster kernels, cleaner code, industry contributions, and new state-of-the-art BF16 / MXFP8 / NVFP4 GEMMs that match or surpass cuBLAS!
Alongside this release, we’re equally excited to share some insights we learned while squeezing every last TFLOP out of Blackwell:
(with @hazyresearch & generously supported by @cursor_ai)

English
Roberto Garcia retweetledi

Announcing Flapping Airplanes!
We’ve raised $180M from GV, Sequoia, and Index to assemble a new guard in AI: one that imagines a world where models can think at human level without ingesting half the internet.
GIF
English
Roberto Garcia retweetledi

Holiday read from @HazyResearch 🎄:
How should you mix and match LLMs in an agentic system? How many bits of information about the context does an agent carry?
We use information theory to understand how to choose and scale these models.

English
Roberto Garcia retweetledi

Really enjoyed our conversation with @alex_damian_ , check it out! Lots of interesting thoughts about the role of theory in modern ML and what questions to explore next.
Yasa Baig@BaigYasa
🎙️ First time doing this 🙂 — I filled in for François on a one-off podcast episode with @alex_damian_ and @jerrywliu! We had a really fun, wide-ranging conversation about AI, theory, and how research actually gets done. Watch here 👇 youtu.be/6eQiKI9Q-Sk
English
Roberto Garcia retweetledi

🎙️ First time doing this 🙂 — I filled in for François on a one-off podcast episode with @alex_damian_ and @jerrywliu!
We had a really fun, wide-ranging conversation about AI, theory, and how research actually gets done.
Watch here 👇
youtu.be/6eQiKI9Q-Sk

YouTube

English
Roberto Garcia retweetledi
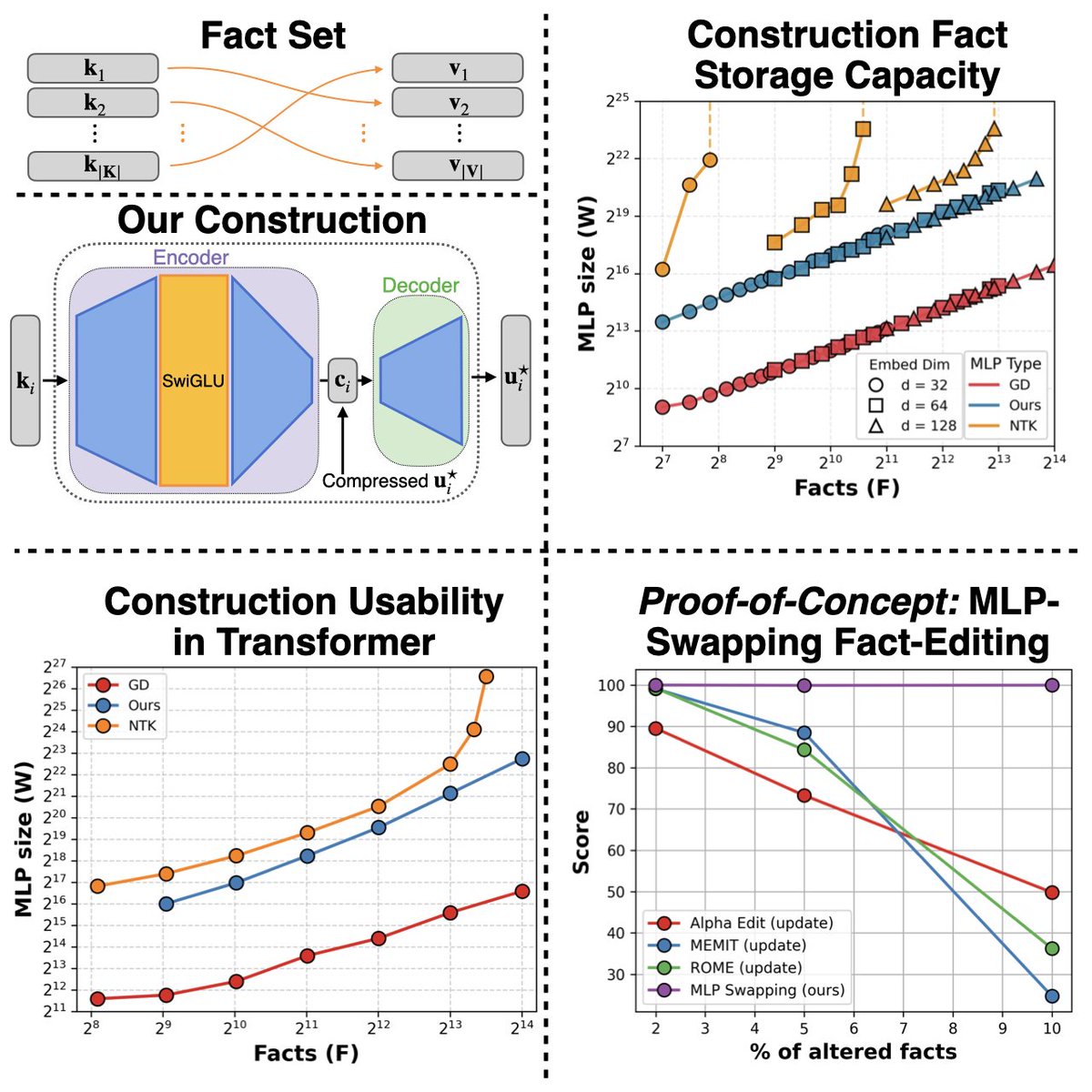
We explicitly construct MLPs that implement key–value fact mappings and, as a proof-of-concept, demonstrate modular fact editing inside a 1-layer transformer. (Joint work with @OwenDugan, @garctrob, @ronnygjunkins and team!)
x.com/OwenDugan/stat…
Owen Dugan@OwenDugan
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔 Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩 New work with @garctrob @ronnygjunkins @jerrywliu @dylan_zinsley @EyubogluSabri Atri Rudra @HazyResearch! 🧵👇
English
Roberto Garcia retweetledi
Curious how to cook up your own fact-storing MLPs? We wrote up a simple recipe… just in time for the holiday season 🎁👨🍳✨🧠 Check it out!
I’ll be at NeurIPS this week — happy to talk about MLPs & more!
Owen Dugan@OwenDugan
Part 2 of our MLPs blog post is out! 👀 This time, we’re here to tell you the story 📖 of our quest for a construction that: ✅ Handles general embeddings 🌐 ✅ Asymptotically matches the information-theoretic limit 📊📈 ✅ Is usable within transformers 🤖✨
English
Roberto Garcia retweetledi

Part 2 of our MLPs blog post is out! 👀
This time, we’re here to tell you the story 📖 of our quest for a construction that:
✅ Handles general embeddings 🌐
✅ Asymptotically matches the information-theoretic limit 📊📈
✅ Is usable within transformers 🤖✨

Owen Dugan@OwenDugan
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔 Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩 New work with @garctrob @ronnygjunkins @jerrywliu @dylan_zinsley @EyubogluSabri Atri Rudra @HazyResearch! 🧵👇
English
Very excited to introduce our fact-storing MLP construction and the insights we learned from it and from plugging it into a Transformer block! Really fun work with an amazing team 🙌.
Can’t wait to see the new directions this could unlock: can MLP constructions help us pack more knowledge into smaller models or speed up pre-training and inference in LLMs?
Owen Dugan@OwenDugan
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔 Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩 New work with @garctrob @ronnygjunkins @jerrywliu @dylan_zinsley @EyubogluSabri Atri Rudra @HazyResearch! 🧵👇
English
Roberto Garcia retweetledi
Happy 🦃 Thanksgiving weekend! 🍂 This year, we cooked up a new recipe for juicy fact-storing MLPs. Instead of picking apart trained models, we asked: Can we construct fact-storing MLPs from scratch? 🤔
Spoiler: we can & we figured out how to slot these hand-crafted MLPs into Transformer blocks as modular fact stores! 🧩
New work with @garctrob @ronnygjunkins @jerrywliu @dylan_zinsley @EyubogluSabri Atri Rudra @HazyResearch!
🧵👇
English
Roberto Garcia retweetledi

The U.S.–China AI race won’t be decided by who builds the most datacenters, but by who deploys the most intelligence.
We call this Gross Domestic Intelligence (GDI): intelligence per watt × usable power.
If the U.S. activates its dense installed base of local AI accelerators in a hybrid local–cloud system, it could add ~30–40% inference capacity and ≈2-4× GDI for single-turn chat and reasoning queries without building any new datacenters or grid infrastructure.
Winning the GDI race means treating local compute as critical infrastructure and making hybrid inference the default.
(1/N)

English
Roberto Garcia retweetledi
This is a satirical image but I would actually love this feature.
Soren Iverson@soren_iverson
ChatGPT set agreeableness level
English
Roberto Garcia retweetledi

Thrilled to have contributed to Olmo 3! The best fully open 32B model (data, training recipes, checkpoints and more!)
As an intern at AI2 these last 8 months, I’ve grown to deeply appreciate the careful science, iteration, and collaboration that go into models like this and have learned so much from the team. I am more optimistic than ever about the future of open-source and data-centric research right now.
My particular contribution was working on the Dolma 3 data mix 👩🍳 I was able to apply ideas from some of my earlier mixing work, explore new problem settings, and see firsthand the data challenges that arise when building datasets intended for real models at scale. More on this coming soon!
Ai2@allen_ai
Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey. Best fully open 32B reasoning model & best 32B base model. 🧵
English
Roberto Garcia retweetledi
(1/6) GPU networking is the remaining AI efficiency bottleneck, and the underlying hardware is changing fast! We’re happy to release ParallelKittens, an update to ThunderKittens that lets you easily write fast computation-communication overlapped multi-GPU kernels, along with new kernels for data, tensor, sequence, and expert parallelism!
Here’s a photo of overlapped kittens, along with things you should care about when optimizing multi-GPU kernels.
(With @simran_s_arora, @bfspector, and @hazyresearch. Generously supported by @cursor_ai and @togethercompute)

English
Roberto Garcia retweetledi


Roberto Garcia retweetledi
Data centers dominate AI, but they're hitting physical limits. What if the future of AI isn't just bigger data centers, but local intelligence in our hands?
The viability of local AI depends on intelligence efficiency. To measure this, we propose intelligence per watt (IPW): intelligence delivered (capabilities) per unit of power consumed (efficiency).
Today’s Local LMs already handle 88.7% of single-turn chat and reasoning queries, with local IPW improving 5.3× in 2 years—driven by better models (3.2×) and better accelerators (1.7×).
As local IPW improves, a meaningful fraction of workloads can shift from centralized infrastructure to local compute, with IPW serving as the critical metric for tracking this transition.
(1/N)

English
Roberto Garcia retweetledi
AI has been built on one vendor’s stack for too long.
AMD’s GPUs now offer state-of-the-art peak compute and memory bandwidth — but the lack of mature software / the “CUDA moat” keeps that power locked away. Time to break it and ride into our multi-silicon future. 🌊
It's been a blast working with the amazing @_williamhu, @Drewwad and team; we present HipKittens!

English