Sabitlenmiş Tweet

After reading @Guardicore CVE-2020-3952 excellent article and PoC I rewrote it a bit to check without adding admin user here github.com/gelim/CVE-2020…
#vmware #vmdir #ldap #vcenter #vulnerability
English
gelim
564 posts



🎉 Congrats to @MiniMax_AI on this release. Day-0 support for MiniMax M2.7 in vLLM! 🤖 Agentic-first design. Multi-agent orchestration ("Agent Teams") and complex skill management 💻 Strong coding. Production debugging, log analysis, and code security 📄 Office automation. Proficient in document editing across Word, Excel, and PowerPoint Get started 👇 📖 docs.vllm.ai/projects/recip…



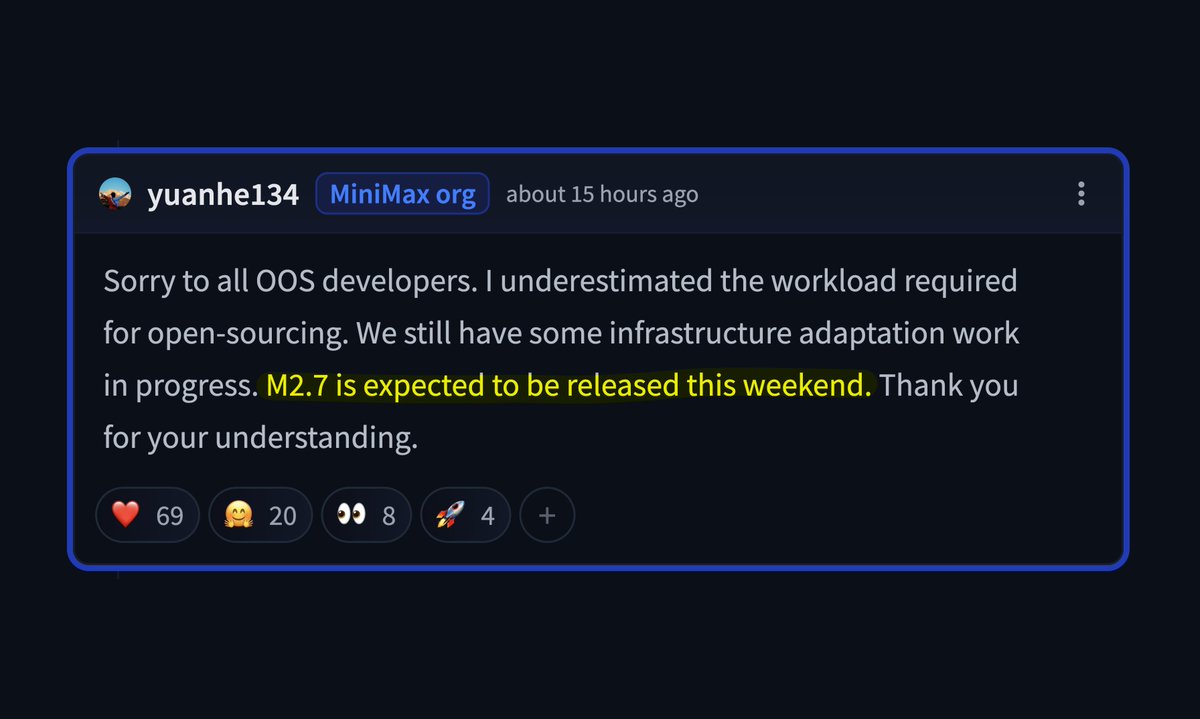
M2.7 open weights coming in ~2 weeks. still actively iterating just updated a new version on yesterday — noticeably better on OpenClaw.


Introducing MiniMax-M2.7, our first model which deeply participated in its own evolution, with an 88% win-rate vs M2.5 - Production-Ready SWE: With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%), M2.7 reduced intervention-to-recovery time for online incidents to 3-min on certain occasions. - Advanced Agentic Abilities: Trained for Agent Teams and tool search tool, with 97% skill adherence across 40+ complex skills. M2.7 is on par with Sonnet 4.6 in OpenClaw. - Professional Workspace: SOTA in professional knowledge, supports multi-turn, high-fidelity Office file editing. MiniMax Agent: agent.minimax.io API: platform.minimax.io Token Plan: platform.minimax.io/subscribe/toke…