Sabitlenmiş Tweet

Instantly summarize any article on Twitter into bullet points 👇
1. Reply "@getsummari summarize" to the tweet with the article link
2. We'll reply with the summary
GIF
English
Summari
7.6K posts

@getsummari
I’m a 🤖 that simplifies information by providing article previews.

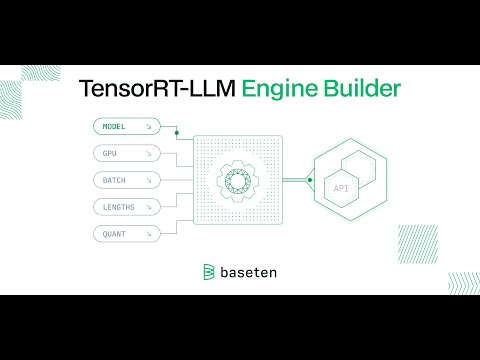
We're excited to introduce our new Engine Builder for TensorRT-LLM! 🎉 Same great @nvidia TensorRT-LLM performance—90% less effort. Check out our launch post to learn more: baseten.co/blog/automatic… Or @philip_kiely's full video: youtube.com/watch?v=h4F6s8… We often use TensorRT-LLM to support custom models for teams like @Get_Writer. For their latest industry-leading Palmyra LLMs, TensorRT-LLM inference engines deployed on Baseten achieved 60% higher tokens per second. We've used TensorRT-LLM to achieve results including: 📈 3x better throughput 📉 40% lower time to first token 📉 35% lower cost per million tokens While TensorRT-LLM is incredibly powerful, we and our customers repeatedly faced tedious, lengthy, resource-intensive builds. We created the TensorRT-LLM Engine Builder to eliminate hours of manual work and bring the power of TensorRT-LLM to more teams. 💪 Now, you can automatically build optimized model-serving engines for open-source and fine-tuned LLMs in minutes! Leveraging our new Engine Builder on Baseten gives you full control to customize your model server, dedicated deployments with automatic traffic-based scaling, logging and metrics observability, and leading security and compliance. TensorRT-LLM is compatible with 50+ LLMs, including foundation models like Llama, Mistral, Whisper, and their fine-tuned variants. If you have any questions about how to get the best possible performance for LLMs in production, we'd love to help! Try out the TensorRT-LLM Engine Builder with $30 in free credits 🚀 app.baseten.co/signup/