Sabitlenmiş Tweet

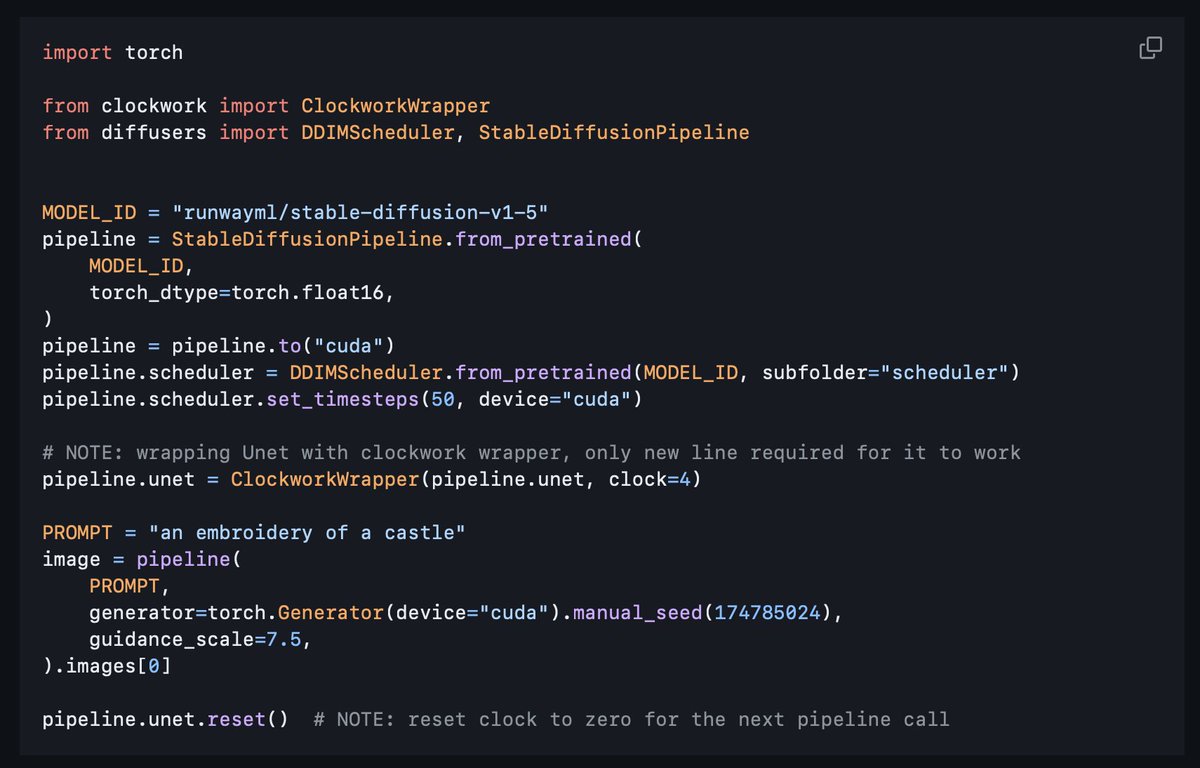
The code for clockwork is now open-source!
It allows up to 40% time savings with close to no loss in percept. quality w/o any finetuning required. Add a single line to your pipeline synthesis code and see for yourself!
github.com/Qualcomm-AI-re…

Amir Habibian@amir_habibian
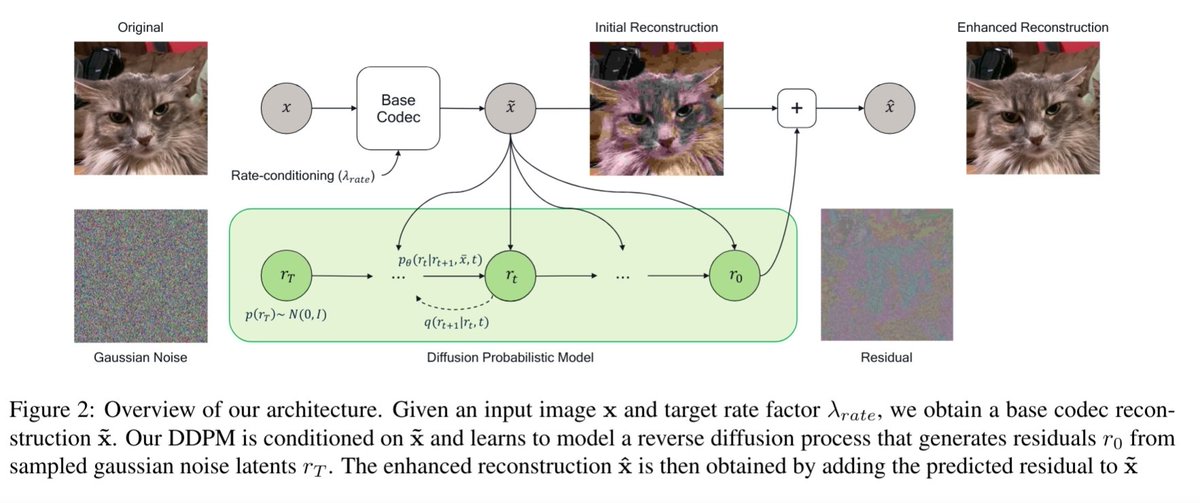
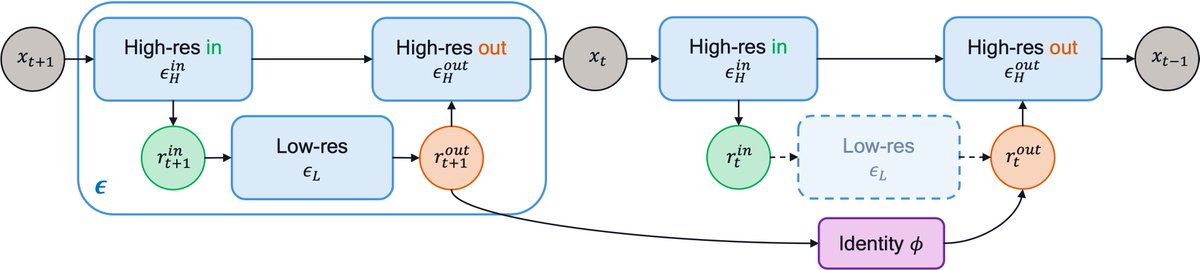
Do we need to run the whole UNet for all the diffusion steps? No! Accelerating your Diffusion Model with a simple trick, even without retraining ?! w/ Amir Ghodrati, @noor_fathima_ , @gsautiere, Fatih Porikli and @peterjensen_ arxiv.org/abs/2312.08128 Code: Stay tuned
English