@michpokrass The journaling helps. Yet it's so lossy. And every astonishment, every achievement, every ... them-becoming-them moment is so big. So valuable.
I'd trade so much just to be able to slow down time even a little more.
English
James Peterson
146 posts
@hellofromjames
AI at @FathomDotVideo








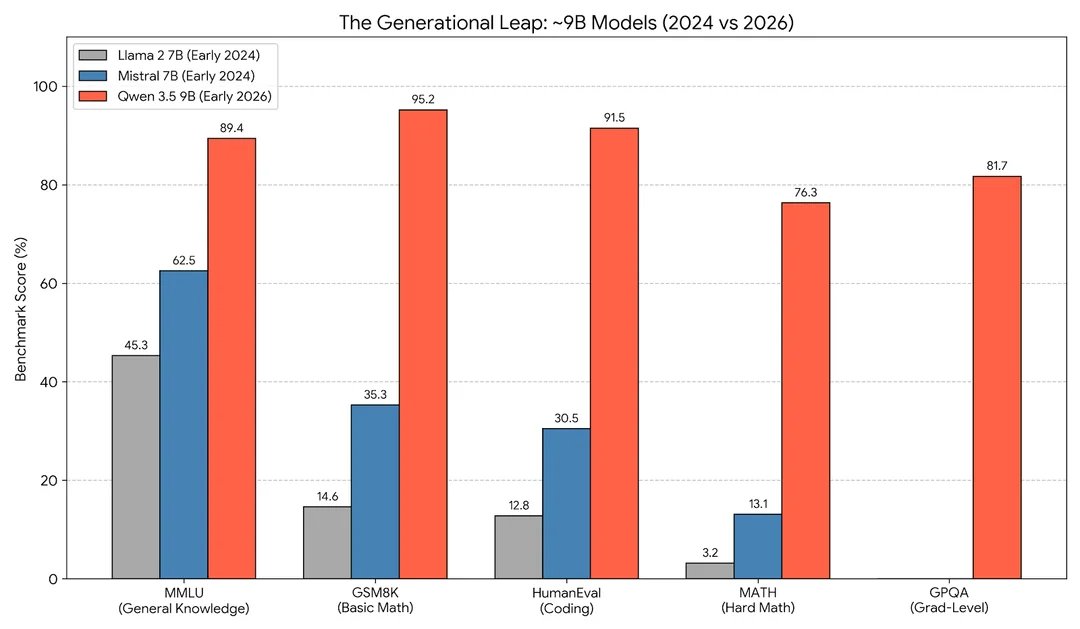
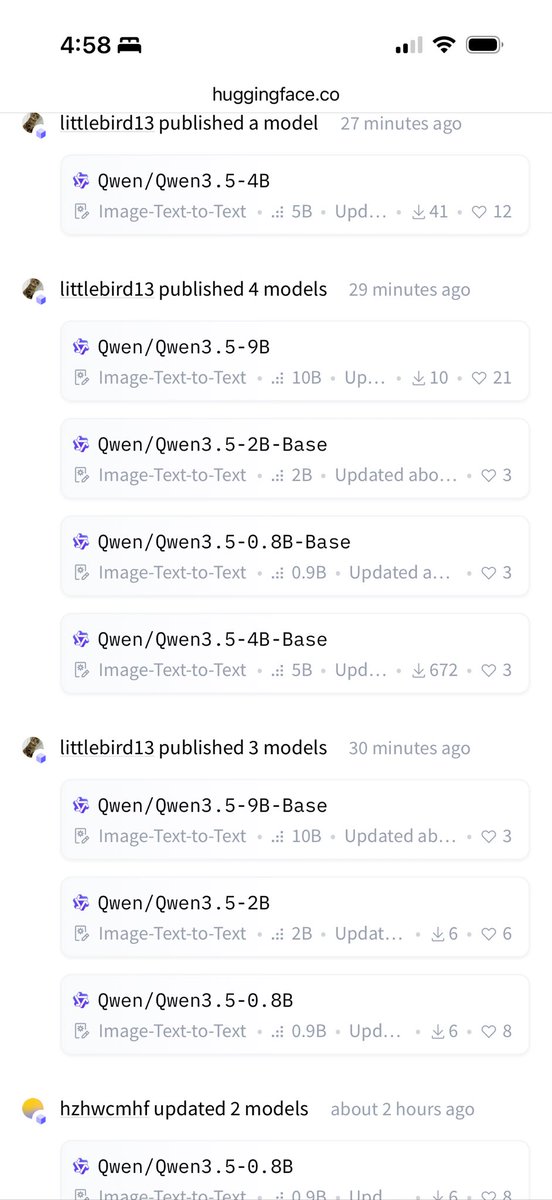
Qwen3.5 9B and 4B benchmarks

Four codegen predictions for 2026, models will: ace managing their own context (docs), ace prodding deployments to experiment and learn, become superhuman at compute efficiency, and exceed (as much as / only) 90% of SFBA-based designers.
Genuinely very impressed by the SVG of a pelican riding a bicycle I just got out of Google's new Gemini 3 Deep Think model