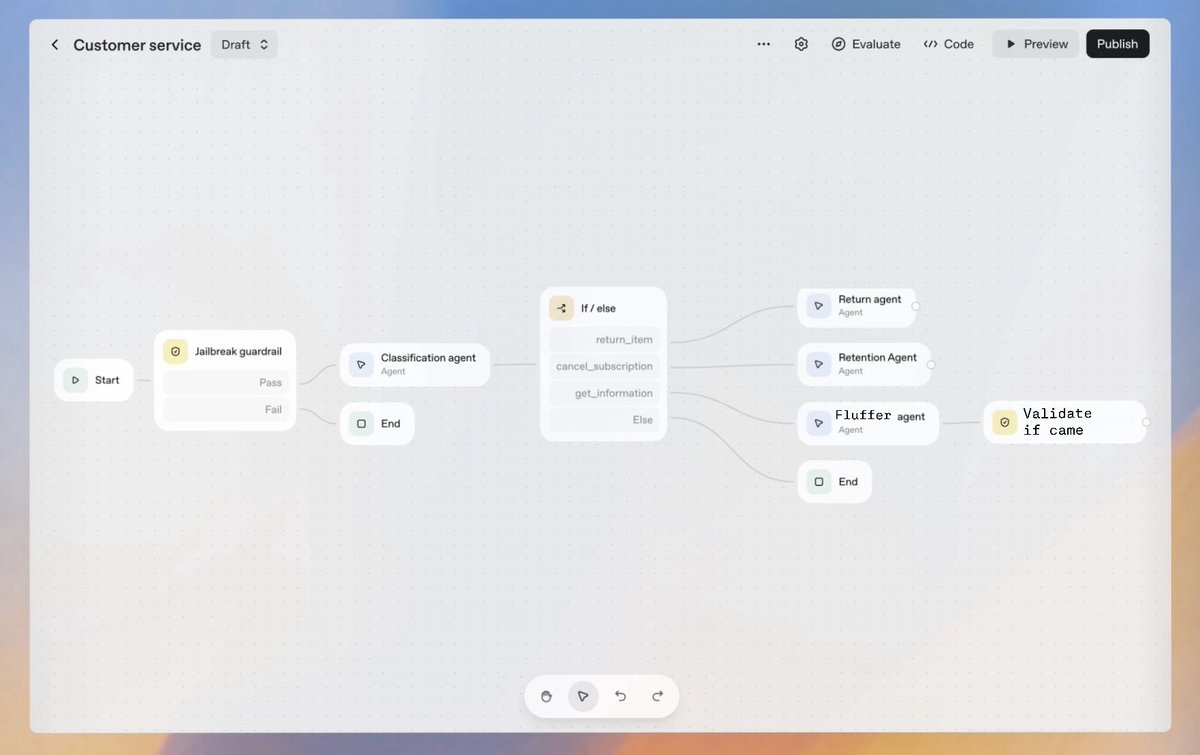
@evilmathkid You can now try bi-directional attention in the input since the model doesn’t have to predict it. That should help.
English
Alex Speicher
25 posts

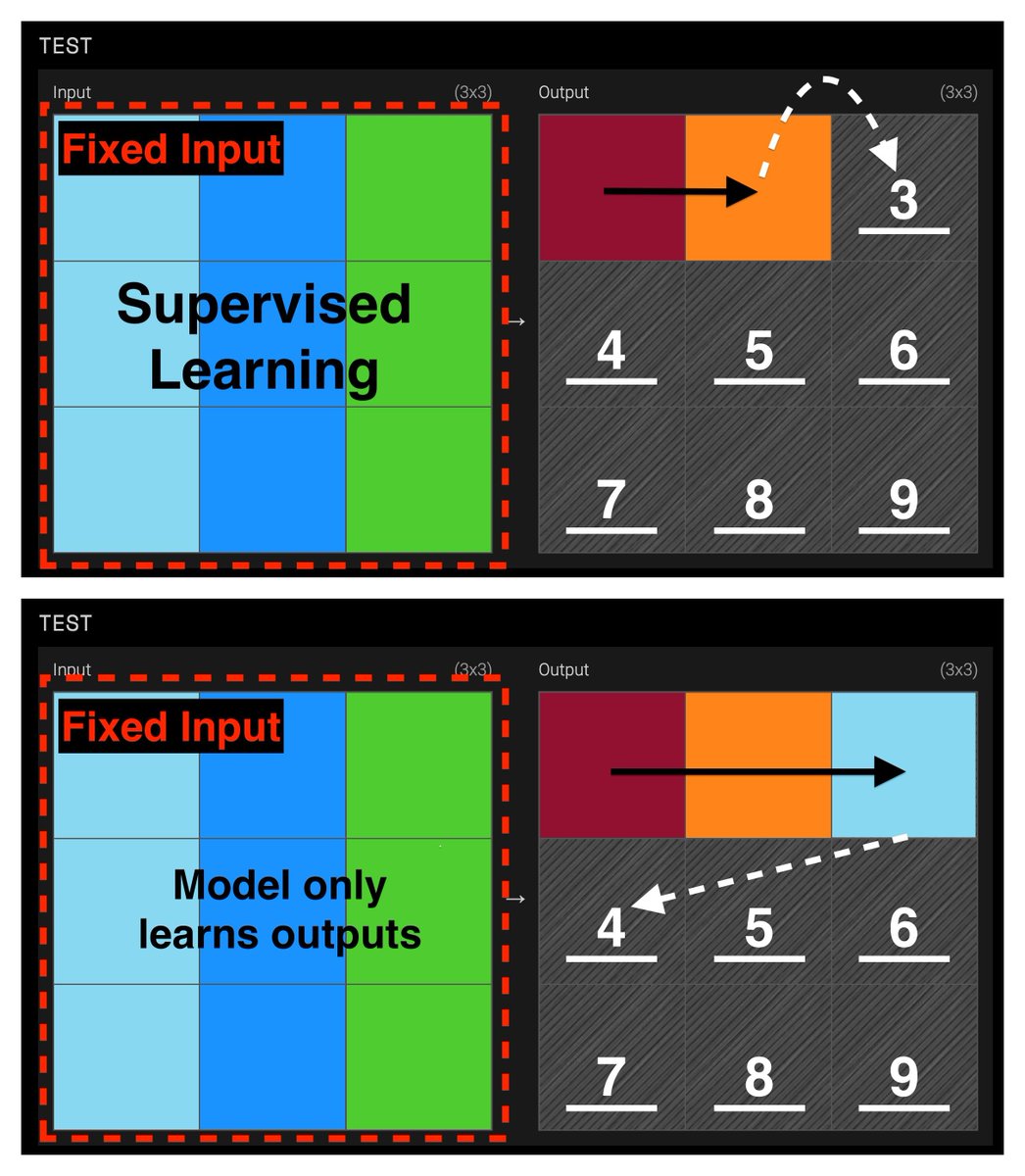
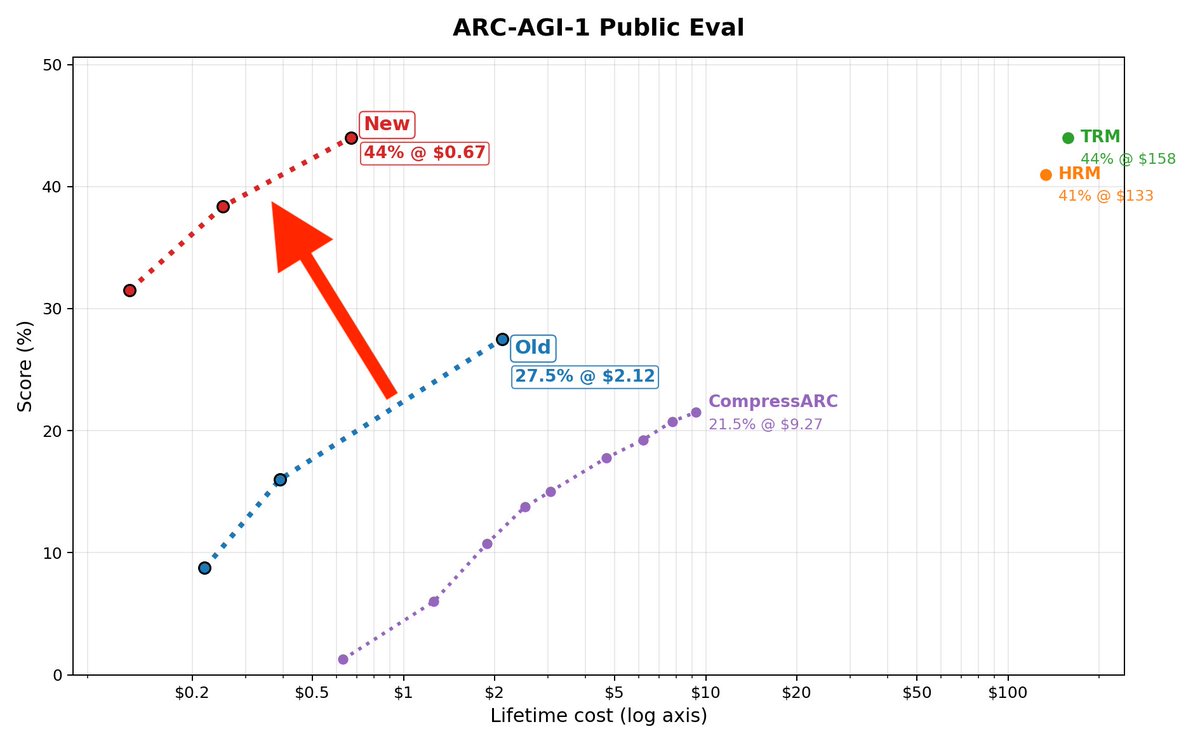



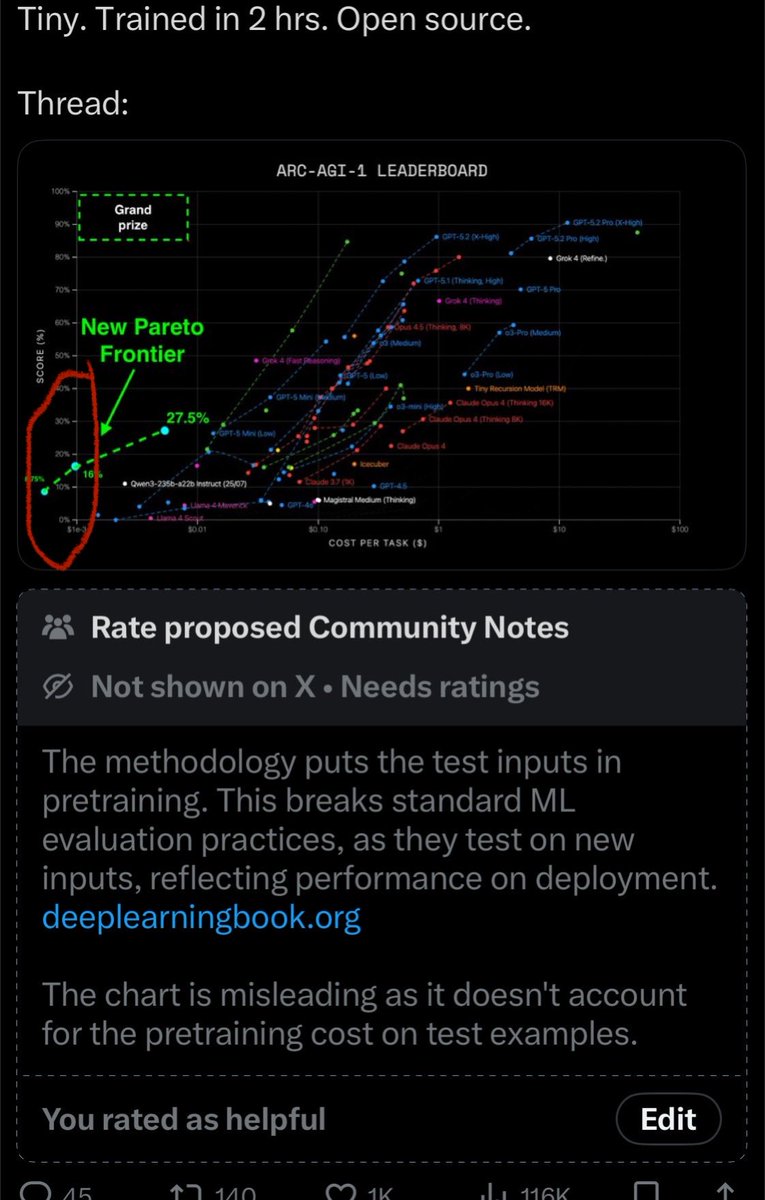
Announcing New Pareto Frontier on ARC-AGI 27.5% for just $2 333x cheaper than TRM! Beats every non-thinking LLM in existence Cost so low, its literally off the chart Vanilla transformer. No special architectures. Tiny. Trained in 2 hrs. Open source. Thread:

Announcing New Pareto Frontier on ARC-AGI 27.5% for just $2 333x cheaper than TRM! Beats every non-thinking LLM in existence Cost so low, its literally off the chart Vanilla transformer. No special architectures. Tiny. Trained in 2 hrs. Open source. Thread:



🚀Introducing Hierarchical Reasoning Model🧠🤖 Inspired by brain's hierarchical processing, HRM delivers unprecedented reasoning power on complex tasks like ARC-AGI and expert-level Sudoku using just 1k examples, no pretraining or CoT! Unlock next AI breakthrough with neuroscience. 🌟 📄Paper: arxiv.org/abs/2506.21734 💻Code: github.com/sapientinc/HRM


Nous Research's RL Environments Hackathon recap thread! Starting with the stars of the show, the winners! Top 3 for the subjective track were: 1st - Pokemon Trainer - by @iyajainfinity & @AlexReibman 2nd - VR-CLImax by @JakeABoggs 3rd - DynastAI by David van Vliet and @SRacoon23 Top 3 for the objective track were: 1st - CyberMaxxing by @1999_karthik 2nd - HelpfulDoctors by @tsadpbb, Nilesh Shah, Max Phelps, and Alexander Speicher 3rd - Physical RL by @nullref0 and @venkatacrc Another special shout out to our partners, @xai, @MistralAI, @nvidia, @tensorstax, @akashnet, @nebiusai, @runpod, @daytonaio, @morph_labs, @LambdaAPI and @Tesla As well as our many judges from @arcee_ai, @axolotl_ai, @cursor_ai, @latentspacepod, @MIT, @togethercompute, @haizelabs, @SophontAI, @EdgeAGI, @Google, specifically: @AlpayAriyak, @winglian, Samuel Barry, @tmm1, @keirp1, @swyx, @teknium, @karan4d, Meghana Puvvadi, @arattml, @brianlechthaler, Josh May, Alex Gu, @gordic_aleksa, @AlpayAriyak, @eraqian, @LukePiette, Rohan Rao, @chargoddard, @LoganGrasby, @xennygrimmato_, @zhangir_azerbay, @rogershijin, @max_paperclips, @theemozilla, and Abhinav Balasubramanian



This is flying a bit under the radar. But in terms of damage to America’s innovation and knowledge supremacy, the chilling effect of these revocations on the country’s ability to attract and retain scientific talent likely dwarfs the impact of tariffs or other policies.