Ivan
12 posts

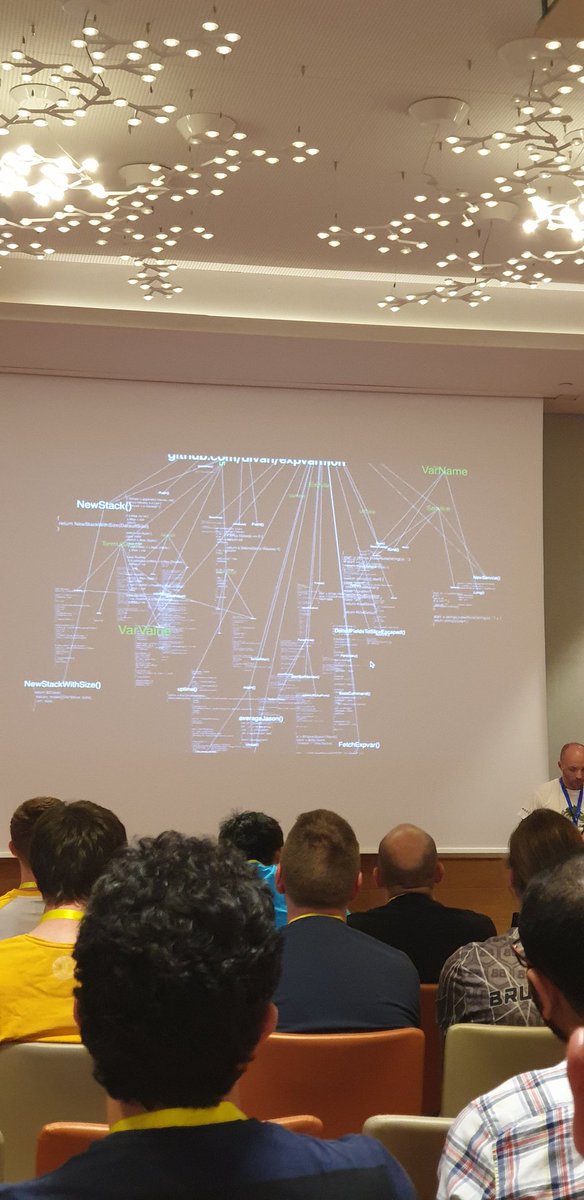
NLRL, or Natural Language Reinforcement Learning, is about adapting RL methods to work in the natural language field. Traditional RL aims to learn a policy (strategy) guiding the agent to the best action in each state. Instead of this, NLRL integrates a Chain-of-Thought process. So language policy in NLRL includes: • Strategic reasoning, logical steps, and planning, written in natural language. • Generation of the reasoning process and of the action. To measure how good a language policy is, standard RL methods are redefined into: - Language Monte Carlo (MC) Estimate - Language Temporal Difference (TD) Estimate What is a better measurement and what else is special about NLRL? Read here -> turingpost.com/p/nlrl


Hi Barcelona! I’ll be in your beautiful city today. If anyone is interested in getting together let me know! #golang