
Shigui Li
19 posts
Shigui Li
@iiiShiguiLi
PhD student at SCUT, specializing in diffusion models and investigating their underlying generative mechanisms.
Katılım Aralık 2023
40 Takip Edilen6 Takipçiler

🎉 Our paper about Preference Optimization has been accepted to ICML 2026!
We unify entangled & disentangled objectives via incentive–score decomposition, derive the Disentanglement Band for ideal training dynamics: suppress loser while preserving winner.
#ICML2026
English
Shigui Li retweetledi

in diffusion models, we typically think of the reverse process as a random walk that slowly builds an image from noise. This is described by an SDE:
d𝐱 = [ 𝐟(𝐱, t) - g(t)² ∇ log pₜ(𝐱) ] dt + g(t) d𝐰
(notice the full g(t)² weight on the score function and the random noise term d𝐰.)
but it's kinda cool that you can silence the noise entirely. i.e., there exists a deterministic ODE that generates the exact same probability distributions at every moment in time
d𝐱 = [ 𝐟(𝐱, t) - ½ g(t)² ∇ log pₜ(𝐱) ] dt
this is cool because the only difference in the steering (drift) between the random path and the smooth path is exactly halving the score term (½ g² vs g²). this precise adjustment perfectly compensates for the lack of random diffusion.
AND
if you simulated a billion particles using the random SDE and a billion using the smooth ODE, the resulting cloud of points would look identical at every time step t, even though the individual paths are completely different.
because the ODE is deterministic, you can run it backwards! you can take a real photo, run the ODE in reverse to find its exact "noise code," and then run it forward to recover the original image perfectly.
this is impossible with the SDE because the random noise scrambles the specific path. thank you mr Fokker-Planck equation
English
Shigui Li retweetledi

1. Schrödinger Equation
2. Dirac Equation
3. Einstein Field Equations
4. Navier--Stokes Equations
5. Planck's Law of Blackbody Radiation
Deutsch
Shigui Li retweetledi

ALERT, NEW YEAR GIFT FROM DEEPSEEK
mHC: Manifold-Constrained Hyper-Connections
it's a pretty crazy fundamental result! They show stable hyper-connection training. This leth them *scale residual stream width*, with minor compute&memory overhead
This is a *huge model smell* recipe.

Zhipeng Huang@nopainkiller
@teortaxesTex And Liang wenfeng cooked a paper for us at the end of year 2025 arxiv.org/abs/2512.24880 ... Jesus what're those quant gods smoking
English
Shigui Li retweetledi

Shigui Li retweetledi

强烈推荐读一下这篇文章 我自己做了些整理
作者是北大 Linian Wang。文章讲的是把 Kimi K2 适配到 vLLM 的过程中,遇到一个很反直觉的现象:同一个模型,在官方 API 上 tool calling 几乎不出错,但换到 vLLM 上就一塌糊涂。然后作者一步步定位原因、推动修复。
我觉得它最值得看的点,其实不是“Kimi/K2/vLLM”上,而是通过这个过程可以把大模型 API 的底层逻辑理解清楚:
大模型 API 的本质:把请求“展开成 Prompt(Token 序列)”,然后做补全(completion)。
所谓 chatbot、tool calling / function calling,本质都是在这个过程上做工程封装。
一切都可以拆回成:Render → Completion → Parse
现在 Chat Completions(以及 function call / tool calling)看起来是这种“结构化请求”:
- messages:system/user/assistant 多轮(也包含 tool_calls 与 tool 的返回)
- tools / functions:工具定义
- tool calling 的模式/约束:tool_choice、parallel tool calls 等
- 采样/停止参数:temperature、stop、max_tokens…
但在模型真正开始预测下一个 token 之前,这些东西都会被系统按照下面的过程处理:
(A) 展开(render)→ 得到最终 Prompt(文本/Token 序列)
(B) 补全(completion)→ 模型续写下一段 Token
(C) 解析(parse)→ 把续写还原成 assistant 文本 / tool_calls 等结构化结果
所以其实可以这么理解:
- Chat Completions ≈ Completions +(A:自动把 messages 渲染成 prompt)+(C:把输出再解释回消息结构)
- Chat + tool calling ≈ Chat +(C:把“特定格式的补全”解析成 tool_calls,并做 schema 校验/护栏)
重点:Chat / Function Call 不是模型多了一种全新能力,而是服务端把 prompt 构造与输出解析自动化了;模型层面依旧是在做下一段 token 的补全。
文章里出现的 bug 基本都发生在 A(render)或 C(parse),而不是“模型本身能力不行”。
文章里一个非常实用的排障方法:
- 不直接用 /v1/chat/completions
- 而是在外部手动 apply_chat_template 得到最终 prompt
- 再把这个 prompt 丢给更底层的 /v1/completions
这么做的好处是:你能“看到真相”:
- 你能检查最终 Prompt 到底长什么样(当然也可以用 echo 回显出来)
- 你还能看到模型最原始的补全文本(协议 token 没被上层 parser 二次加工/丢弃)
后面很多结论,都靠这一步才定位出来:问题不在“模型不会调工具”,而在 prompt 展开和输出解析存在不兼容或边界问题。
三个问题,用更直白的话讲清楚就是展开和解析上出了问题
1) Prompt 末尾少了“现在轮到 assistant 开始输出”的自动补全后缀
本来应该用户问一句 → 模型应该立刻按 tool call 的格式进行补全。
但因为一个参数没有传递到位,导致实际喂给模型的 prompt 末尾缺了关键的 assistant 回合起始标记 / generation prompt(可以理解为少了一个重要的协议尾巴,相当于没明确告诉模型“轮到你回答了”)。
结果就是模型仍然会补全 token,但完全不知道“接下来该干嘛”
- 有时像在续写历史对话(没进入回答态)
- 有时输出自然语言闲聊
- 有时输出半截结构化但不成形
1) 空内容被错误渲染成,直接把 prompt 污染成噪声
某条历史消息 content: '' 就是“空”,本来在 Prompt 也应该就是🈚️啥也不出现。
结果实际渲染链路,框架内部为了统一数据结构,把 '' 标准化成类似 [{type: "text", text: ""}] 这样的 list(多模态/富文本体系里很常见)塞到 Prompt 里面。
结果就是模型是在对“被污染的上下文”做补全。导致 tool calling 的效果劣化。
3) 模型其实已经“写出了工具调用”,但解析器太严格,把它当异常丢掉了
模型已经生成了“看起来就是工具调用”的片段,但是解析器太严格了,当做异常处理掉了。
(这里面还有上下文污染导致模型生成格式不对的原因)
读完这篇文章最大的收获
1) 一切要还原到“Prompt 补全”这个本质上来理解。
虽然这篇文章,是围绕 tool calling 展开的,但它的结论其实适用于所有大模型 API 场景(chat、completion、structured generation……)。
不管你是用 chat 还是 function call,本质上都是在做“Prompt 补全”。
所以当遇到问题,第一步都要还原到“最终 prompt 是什么样子?”要拿到实际喂给模型的 prompt,甚至不用像文章中这样,拿到协议层的,只用看到你的 API 请求就能判断对不对。
另外很多 API 的报错,也可以从“Prompt 补全”这个角度去分析。
2) Tool calling 本质是“强约束 Schema 输出”(甚至可以当 JSON 限定器/结构化生成器用)。
从工程角度看,tool calling 更像:
让模型按一个强约束的输出协议(schema)去生成结构化片段,然后由服务端解析并执行。
一旦你把它理解其本质是“强 schema 生成”,你会发现 tool calling 还能干一件很实用的事:
- 你不一定真的要“调用工具”,也可以把它当作 JSON/DSL 的限定器,让模型稳定地产出符合 schema 的结构化结果,再交给下游系统处理。
对“强约束生成 / constrained decoding”这个方向感兴趣的话,也推荐顺手看:
- XGrammar:偏“把语法/约束编译成高效的 token 级约束”,让解码阶段就不可能走出非法分支
- LLGuidance:偏“用 guidance/约束驱动生成”,把结构化正确性前置到解码过程,而不是生成完再靠 parser 猜测。
九原客@9hills
中文
Shigui Li retweetledi

Oh, and, wanna build Lipschitz transformers? How about Lipschitz 2-simplical attention models? n-simplical?
I've got you covered: leloykun.github.io/ponder/lipschi…
(3/n)

English
Shigui Li retweetledi
What I mean is this assumption here (see A2 in pic)
With the right choice of layers, parametrization, & bounds on the weights, you may be able to have an upper bound on L
But layernorms make this go to infinity 😅
Theory breaks; you're on your own; and you have to do those expensive hyperparameter searches whether you like it or not. We're lucky some hyperparameters still transfer at scale with the right parametrization (2/n)

English
Shigui Li retweetledi
Most optimization theory papers technically don't even describe 'real-world' LLM training cuz of the Lipschitzness assumption
But the models can't be lipschitz cuz of the layernorms, hence why we've been trying to replace it, or somehow fold it into the optimizer/weights themselves (1/n)
Yaroslav Bulatov@yaroslavvb
20 years of reading and implementing optimization papers, yet after this year's NeurIPS, I’m still questioning the utility of the field. The few methods that work seem to do so by accident.
English
Shigui Li retweetledi

PhD Students - Here is an example of a good discussion section.
A good discussion section should answer 6 questions.
1. What is different in your findings compared to previous research?
2. What is similar in your findings compared to previous research?
3. How different sections of your results section correlate?
4. What are the implications of your findings for practitioners?
5. What are the implications of your findings for researchers?
6. What are the limitations or threats to the validity of your findings?

English
Shigui Li retweetledi

This is the Outstanding Paper Award at ICLR 2025, and this is exactly the kind of research on LLMs we need, not those quasi-psychological studies of the form "we asked the same question to these 3 models and see which one is more racist!"
As you might already know, when finetuning language models, researchers first perform supervised learning on good examples, then apply preference optimization—training the model to distinguish preferred responses from rejected ones using algorithms like Direct Preference Optimization (DPO). This two-stage process improves model behavior, but prior work observed a curious phenomenon: during the preference stage, the model's predicted probability of generating responses (measured by log-likelihood) decreases for nearly all responses, including the preferred ones the training is supposed to encourage.
This paper provides a mathematical framework explaining why this happens by decomposing each gradient update into three components: how the model currently predicts, how training on one example affects similar examples, and the direction of the gradient signal.
The analysis reveals a "squeezing effect": when you apply negative gradients to push down the probability of bad responses, the probability mass doesn't get redistributed evenly—it concentrates on whichever token has the highest probability at each position. This makes the model's predictions increasingly peaked. The effect becomes severe when the negative gradient targets responses that already have very low probability, which commonly occurs when using pre-collected datasets where the rejected responses were generated by a different model.
The framework explains why methods that generate new response pairs from the current model at each training step outperform methods using fixed pre-collected pairs—they avoid applying large negative gradients to responses in low-probability regions.
The insight leads to a simple improvement: including both preferred and rejected responses during supervised fine-tuning before preference optimization demonstrably improves alignment by reducing the harmful squeezing effect.
Let the paper talk to you and answer your questions on ChapterPal: chapterpal.com/s/63899d29/lea…
Download the PDF: arxiv.org/pdf/2407.10490

English
Shigui Li retweetledi

Today, the NeurIPS Foundation is proud to announce a $500,000 donation to OpenReview supporting the infrastructure that makes modern ML research possible.
OpenReview has been our trusted partner for years, enabling rigorous peer review at the scale and pace our field demands. This donation helps ensure they have the resources to strengthen their systems and continue evolving to meet our community's needs.
The tools that enable rapid, rigorous scientific exchange aren't peripheral to our work—they're fundamental. This donation reflects our commitment to the infrastructure that makes ML research possible.
OpenReview operates on a shoestring. They shouldn't have to. #NoMoreShoestrings #NeurIPS blog.neurips.cc/2025/12/15/sup…
English

> Be AI PhD student
> Submit paper to conference
> LLM slop reviews
> Rejected
> Concurrent paper with same method accepted
> Resubmit to next conference
> Reviewer points to concurrent paper which was accepted by last conference
> Lack of novelty
> Rejected
English
Shigui Li retweetledi

Proximal Policy Optimization (PPO) is one of the most common (and complicated) RL algorithms used for LLMs. Here’s how it works…
TRPO. PPO is inspired by TRPO, which uses a constrained objective that:
1. Normalizes action / token probabilities of current policy by those of an old policy from before training. This forms a policy ratio.
2. Constrains the average KL divergence between new and old policies to be less than δ.
The constrained objective in TRPO is guaranteed to improve monotonically, but it is is complicated to solve practically.
From TRPO to PPO. We want an algorithm with the benefits of TRPO—e.g., stability, data efficiency, and reliability—but without its complexity. PPO’s objective is inspired by the TRPO but replaces the hard KL constraint with a clipping mechanism to enforce a trust region in a simpler way.
PPO training process. PPO goes beyond a single policy update in each step, alternating between:
1. Sampling new data or trajectories from the policy.
2. Performing several (usually 2-4 for LLMs) policy updates over the sampled data.
Clipped objective. We start with the TRPO objective with no constraint (unclipped objective). We then introduce a clipped objective that is the same as the unclipped objective but clips the policy ratio to be in the range [1 - ε, 1 + ε]. PPO takes the minimum of clipped and unclipped objectives, making it a lower bound for the unclipped objective.
The behavior of clipping changes based on the sign of the advantage (i.e., clipping is only applied in one direction). We can arbitrarily decrease the objective via the policy ratio, but we are restricted from increasing it. This allows PPO to de-incentivize large policy ratios and enforce a trust region.
KL divergence. We incorporate a KL divergence between the current policy and a reference policy (e.g., the SFT model) when training LLMs with PPO to avoid the policy becoming too different from the reference. We compute KL divergence per token by comparing token probability distributions from the two LLMs for each token in the sequence. This can be added as a penalty to the PPO loss or directly subtracted from the reward.
The critic. The last step in PPO is computing the advantage, which is the difference between the state-action value function and the value function. We estimate the state-action value function (i.e., expected reward for a specific action in a given state) with the actual reward. The value function is estimated with a learned model called the critic or value model.
Unlike a reward model that predicts the outcome reward, the critic predicts expected reward per token. The value function is also on-policy, unlike reward models which are fixed at the beginning of RL training. In PPO, the critic is trained alongside the LLM in each policy update by using an MSE loss against actual / observed rewards. This is called an actor-critic setup.

English
Shigui Li retweetledi

ICLR season, and my timeline is flooded with paper threads that jump straight to we beat SOTA. But the solution only makes sense in the context of the problem, which is usually missing.
What most threads skip:
- What problem are you solving?
- Why does it matter?
- What did prior work miss?
Instead, we get a tour of the method and a leaderboard screenshot.
Remember that the audience for the problem is much larger than the audience for your particular solution.
English
Shigui Li retweetledi

deepseek在英文圈已经被吹上天了,发现中文圈还有很多非AI业内人士,对deepseek的能力没有一个清晰的认识,所以用中文发一条,先说结论,我认为行业贡献而言:GPT>deepseek>gemini>llama及其他
很多人的着眼点在于他用很少的卡也能训练出效果差不多的模型,但这是结果,更重要的他能做到这一点的技术:
deepseek这次最亮眼的是证明了纯粹的outcome reward RL能够直接把模型提到o1水平,在他出来之前,业内所有人(包括deepmind)都认为需要prm (process reward model)才能做到这点,这就已经是颠覆行业的发现了,现在所有除gpt外的llm大组,都在推倒重来,copying他们的训练方法
另外非常重要的是deepseek还发现了这种训练方式甚至能够让模型自己学会longer-chain reasoning以及reflection,他们所谓“aha moment”。相当于只训练llm得到更准确的结果,llm就能自己学会反思,思考到一半知道自己这样做下去会错,然后尝试自己纠错,这种模型“自我进化”的特性是业内仅次于GPT intelligence emergence的重大发现
就结果而言,“用更少的卡训练出效果差不多的模型”可能不仅仅是节约成本这么简单,更是一种improvement of scaling law,意味着这种方法往上堆更多的卡有可能把模型能力再往上提升一个数量级,甚至直接达到AGI/ASI
这就是为什么这次业内这么hyper,deepseek开源的价值远大于llama,llama基本是大家已知的方法堆卡训练,deepseek带来太多的惊喜
中文
Shigui Li retweetledi

A common question nowadays: Which is better, diffusion or flow matching? 🤔
Our answer: They’re two sides of the same coin. We wrote a blog post to show how diffusion models and Gaussian flow matching are equivalent. That’s great: It means you can use them interchangeably.

English

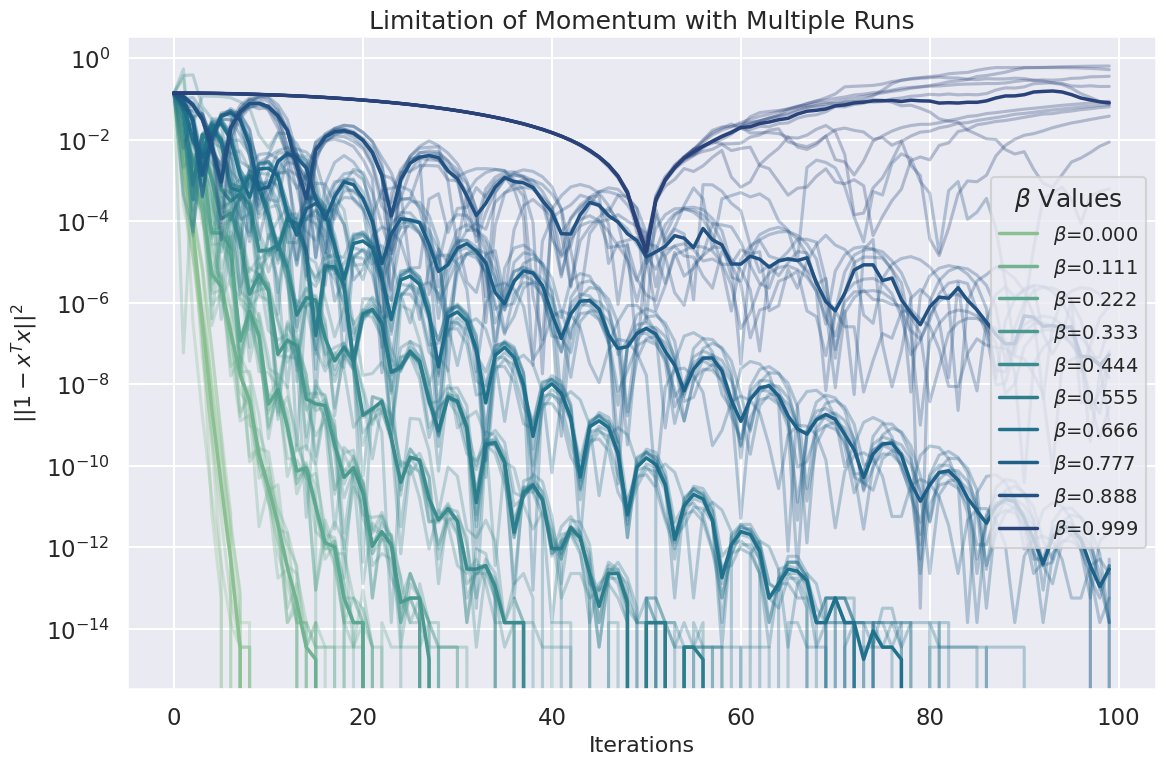
Momentum in optimization isn't always your best friend. In dynamic systems, even tiny momentum can be catastrophically destructive. 🐾
Here we're using PSGD's Dense Newton method as the base optimizer—an 'old school' method that's reliable, like a wise old dog. 🐕🦺
For static systems, momentum shines. But beware when dynamics come into play. 📉 #DeepLearning #Optimization1/3

English
Shigui Li retweetledi

Want to learn continuous & discrete Flow Matching? We've just released:
📙 A guide covering Flow Matching basics & advanced methods arxiv.org/abs/2412.06264.
💻 An open source codebase with image & text examples github.com/facebookresear….
🗣️ A Flow Matching tutorial #NeurIPS2024.

English