Sabitlenmiş Tweet

We have a new ICML paper! Adaptive Horizon Actor Critic (AHAC). Joint work with @krishpopdesu @xujie7979 @eric_heiden @animesh_garg
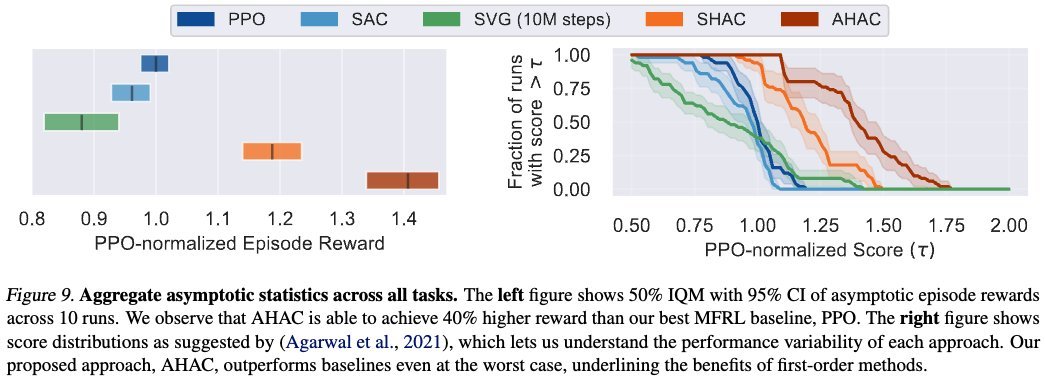
AHAC is a first-order model-based RL algorithm that learns high-dimensional tasks in minutes and outperforms PPO by 40%.
🧵(1/4)
English