Sabitlenmiş Tweet

i like this because i can deeply apply research in alignment with edifying incentives even as an entrepreneur
Soren Larson@hypersoren
English
M
21.5K posts

@init_malachi
continually learning in a state of delight | ex sr member of technical staff | interested in ai epistemology



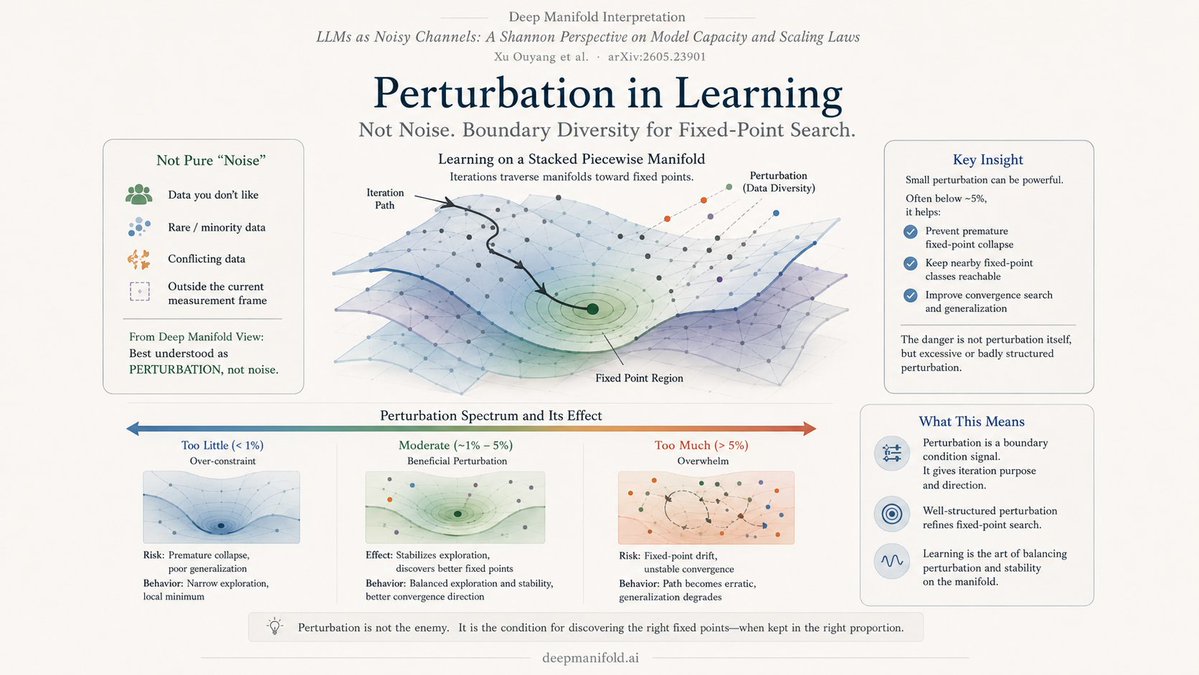
Updated our paper on the foundations of memory in sequence models (with fresh insights, clearer writing and ablations). Our paper contrasts two distinct ways in which language models memorize and formulates the questions that arise from this. Will be presented at #ICML.

I'm reading the Pope's encyclical, and it's banger after banger. New insults for AI chuds: Architects of Babel Lords of towers destined for ruin



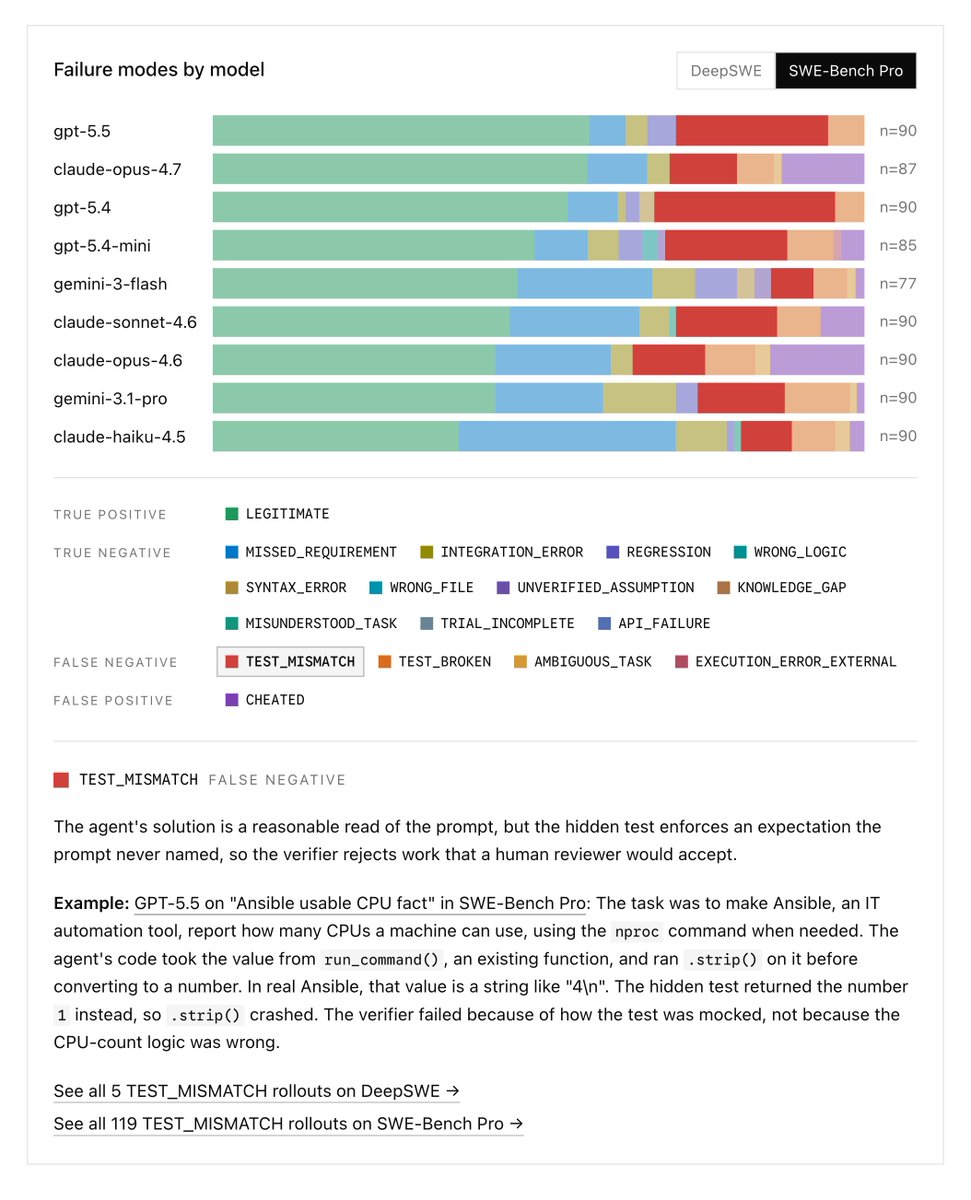

if you are interested in learning about the infra behind auto-research this 1h30min interview with the paradigma folks is for you in it we look at: - why dag are great research substrate - how to let agents run that dag - ways to make big public dag - how to avoid bad bad dag