Sabitlenmiş Tweet
ME|META|
2.1K posts


ME|META|
@interMemetica
Weaving a tighter fabric of universal self-discovery. || M-Mbresia Strategy || NomisMeta || InterMemetica
Everywhere at once Katılım Temmuz 2015
384 Takip Edilen109 Takipçiler
ME|META| retweetledi

Algorithm Visualizer devrait être dans la boîte à outils de tout·e développeur·se qui apprend ou enseigne des algos — la visualisation en direct à partir du code rend les mécanismes abstraits vraiment lisibles.
algorithm-visualizer.org
Français
@nakadai_mon @HowToAI_ Each sub-agent can still be prompted to consider its interactions into a recursive pre-output stage.
English

@HowToAI_ If you want a team of experts you let the agent summon sub-agents with different roles, let them argue with eachother and let the best solution rise to the top.
English

🚨 MIT just dropped a technique that makes ChatGPT reason like a team of experts instead of one overconfident intern.
It’s called “Recursive Meta-Cognition” and it outperforms standard prompts by 110%.
Right now, if you want an AI to solve a problem, you ask one question. The AI gives you one answer.
If it’s wrong, you never know.
It’s like asking a random person on the street for medical advice and just trusting them..
MIT researchers realized this is a massive structural flaw.
They asked a simple question. What if AI could check its own work from multiple angles before giving you the final answer?
Not just "think step by step."
Actually verify. Score confidence. Flag uncertainty.
They built a framework called Recursive Meta-Cognition.
And the results rewrite the rules of prompt engineering.
Instead of a single, blind output, the technique forces the AI to break a complex problem into smaller pieces and interrogate its own logic from multiple perspectives.
But here is the secret sauce.
It assigns a strict confidence score to every single reasoning path it takes, from 0.0 to 1.0.
Paths below 0.4 are instantly rejected. Paths above 0.8 are trusted. Anything in between? The AI stops and tells you: "I am not sure, and here is why."
No more hallucinations. No more fake confidence.
If you are running a business and relying on AI to outline a SaaS marketing strategy, analyze data, or drive operational efficiency, a hallucination isn't just an error. It is a loss of profit.
With a standard prompt, the AI gives you ONE answer. It sounds confident. It might be completely wrong for your specific situation.
With Recursive Meta-Cognition, the AI spots its own hidden assumptions. It tests its logic. It catches its own errors before they ever reach your screen.
We've been treating AI like a vending machine. Put a prompt in, get a result out.
But true intelligence doesn't just answer questions.
It questions its own answers.

English
@whowouldathunk2 @bswrpray @JustinEchterna9 Biology is already present in the universe by having the requisite chemistry and physical laws, regardless of "if/when" abiogenesis occurs.
English

@bswrpray @JustinEchterna9 You are of course free to believe whatever you think explains reality. I can't logically see how consciousness came first. Physical reality existed before biology showed up. Consciousness is a property of biology, not of rocks.
English

Orch OR specifies a physical substrate (microtubules), a physical process (quantum coherence in aromatic networks), a physical trigger (objective reduction at a specific threshold), and physical perturbations that should disrupt it (anesthetics at specific binding sites). Whether it's correct is an empirical question. But it's more mechanistically specific than any competing theory of consciousness ...
English
ME|META| retweetledi

I am almost halfway through the semester, and this term I am teaching two heavy courses (60 hours each). One is about cryptanalysis: all the way from classical cryptology of substitution ciphers, through block ciphers, up to post-quantum cryptography.
The second course is a tutorial: a "zero to hero" introduction to neural networks, starting from the classic topics of the 1940s up to the transformer revolution.
I have decided to rely heavily on agentic tools to help me write lecture notes, slides, and interactive applets. It's a very systematic process where I give lectures, do exercises with students, and fine-tune the materials. I have noticed that the boost is incredible. Now we can really dive deep into the topics, adding a lot of custom-made help and examples (full Enigma breaking or high-level implementations in JAX). I see that the students enjoy having such complete notes.
I put a lot of effort into the structure and scaffolding of those notes. Many texts are generated from good sources, but I read every single page and apply corrections. I think I have saved a lot of hours on the tedious fine-tuning of pictures and examples. I also had the courage to test and cover much more experimental content that I had never explored before.
We spend three active hours each week with the students, and the work is very intense. But at the same time, the courses feel very rewarding, and I should admit that I have learned a ton (especially about the classic papers on AI). I will definitely keep building complete lecture notes for future courses, but I already see that the main issue is proper internalization of the knowledge, both by the students and by me. Overall, the process is much smoother because we can always ask an LLM to provide a more accurate answer.


English
ME|META| retweetledi

We’ve just released another paper solving five further Erdős problems with an internal model at OpenAI: arxiv.org/abs/2604.06609.
Several of the proofs were especially enjoyable to digest while writing the paper. My personal favorite was the solution to Erdős Problem 1091. The question asks: if a graph G has chromatic number 4, while every small subgraph has chromatic number at most 3, must it contain an odd cycle with many diagonals? The internal model gives a very enlightening counterexample to this conjecture, and the proof was a pleasure to understand.
For those so inclined, a really fun exercise is to try to reconstruct the proof from Figure 5 of the paper, which was of course produced by Codex.

English
ME|META| retweetledi

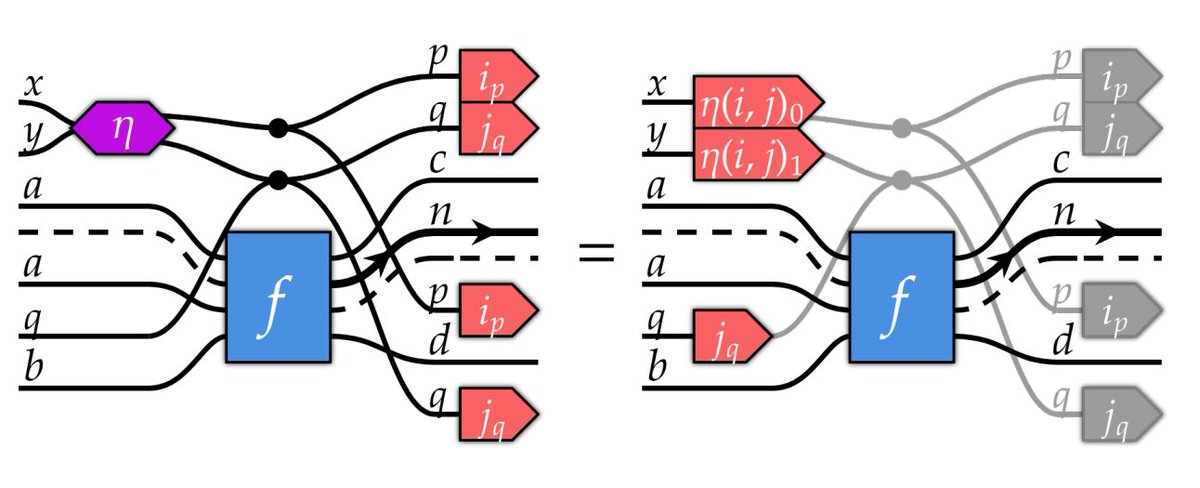
The lack of formalism wrt broadcasting in deep learning models annoyed me so much I learned category theory. Weaves, Wires, and Morphisms is now out on arXiv! First step to using the Yoneda lemma to automatically derive fused kernels.
arxiv.org/abs/2604.07242
English
ME|META| retweetledi

This is Algebrica. A mathematical knowledge base I’ve been building for 2.5 years.
215+ entries, carefully written and structured.
400k+ views over this time. Not much in absolute terms, but meaningful to me.
No ads.
No courses to sell.
No gamification.
No distractions.
Just essential pages, aiming to explain mathematics as clearly as possible, for a university-level audience.
Built simply for the pleasure of sharing knowledge.
Content licensed under Creative Commons (BY-NC).
Best experienced on desktop.
If it helps even a few people understand something better, it’s worth it.

English
ME|META| retweetledi





ME|META| retweetledi

We are now the 6th largest ai app in the world on Open Router and growing!

English
ME|META| retweetledi

I don't know what it mean anymore that I can just spin up something like this in 15 minutes by asking @claudeai to integrate Semiotic and Pretext using the wikipedia streaming API. This would have been such an extraordinary thing but now it's just... Tuesday.
GIF
English
ME|META| retweetledi


ME|META| retweetledi

🏗️ Your textbook operates at the ground floor. The building has five stories.
🔸Level 0: Scalar wave equation — the seed
🔸Level 1: Hertz potential — Lorenz gauge is AUTOMATIC here
🔸Level 2: Whittaker scalars — two functions generate ALL of EM
🔸Level 3: Four-potential — where textbooks start
🔸Level 4: Fields (E, B) — where textbooks end
Each level generates the next by differentiation. Each derivative is lossy.
The Lorenz gauge, which at Level 3 is an imposed constraint physicists argue about, is at Level 1 an algebraic tautology. Not a law. A tautology of deeper structure.
Standard EM operates at Levels 3-4. Two out of five.
My paper "The Deleted Degrees of Freedom" maps the full hierarchy in Section 4.7. Pinned on my profile.

English
ME|META| retweetledi

IFS Fractals with Memory and a Little Bit of Non-Linearity.
Made with #Python #NumPy #Matplotlib and
@marimo_io

English
ME|META| retweetledi

En Nature Communications, "Revealing the topological nature of entangled orbital angular momentum states of light", nature.com/articles/s4146… Cf. sciencedaily.com/releases/2026/…
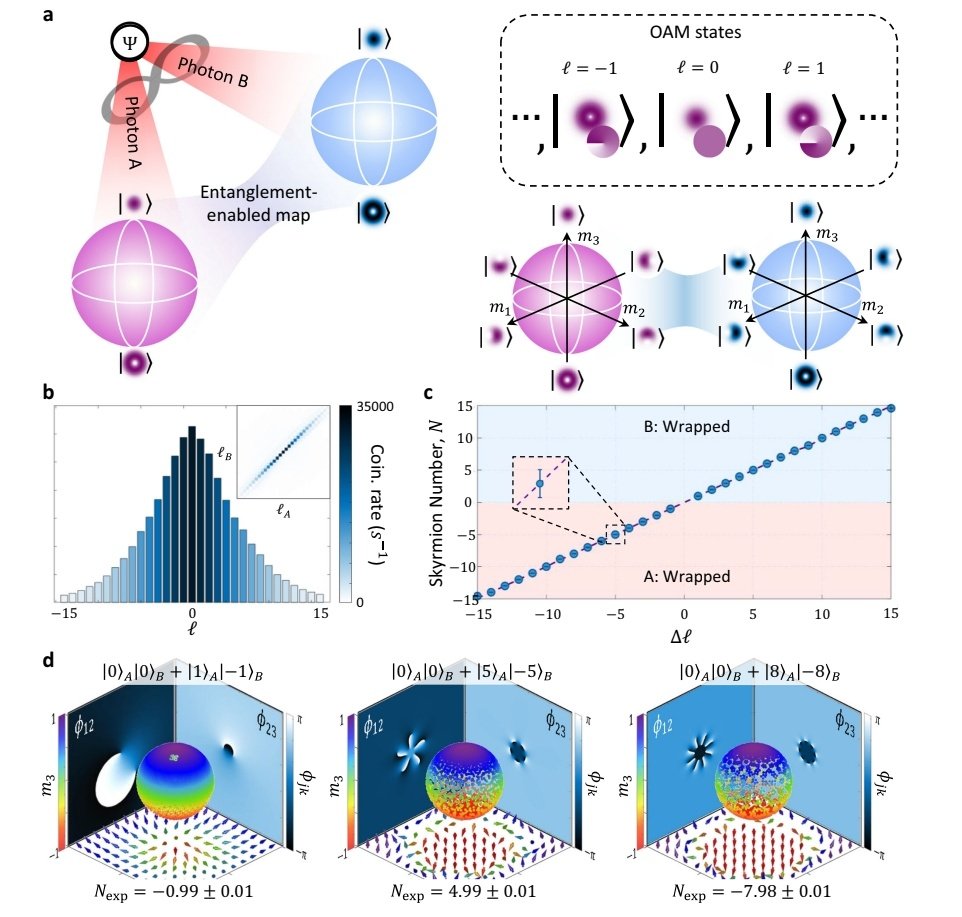
English

the difference between a biological neuron and an artificial neuron is massive.
they share the idea. not the reality.
what a biological neuron does:
• receives signals through dendrites → thousands of inputs, not just a few
• integrates over time → signals accumulate, decay, interact
• fires spikes → discrete events, not smooth numbers
• adapts continuously → plasticity rewires connections based on experience
• runs on chemistry + electricity → noisy, slow, but incredibly efficient
what an artificial neuron does:
• takes weighted inputs → simple numbers in, number out
• applies an activation function → relu, sigmoid, etc
• updates via backprop → global optimization, not local biology
• runs on silicon → fast, precise, but power-hungry
• no real “memory” → unless explicitly designed (rnn, transformers)
why it matters:
• ai today is inspired by the brain, not a replica of it.
• biological neurons are dynamic, adaptive, and energy-efficient.
• artificial neurons are simplified, scalable, and mathematically convenient.
we’re not building brains.
we’re building approximations that work well enough to be useful.

English
ME|META| retweetledi

Imagine a place where people could communicate around one shared idea and that only attracted people interested in that one specific topic thus cutting down on unnecessary noise and voices irrelevant to the topic being discussed.

English
ME|META| retweetledi

@mathemetica physical constants and dimensions are not "inputs" to the universe, but emergent "outputs" of a 12-state discrete phase lattice attempting to describe an analog process. The "cost" of this discretization—the mathematical overhead—is what we measure as the "Laws of Physics."
English
ME|META| retweetledi

ME|META| retweetledi


ME|META| retweetledi

Every time you get a cancer biopsy, the lab makes a tissue slide that costs about $5. It shows the shape of your cells under a microscope, and every cancer patient already has one on file.
There’s a much fancier version of that test called multiplex immunofluorescence (basically a protein-level map showing which immune cells are near your tumor and what they’re doing). It costs thousands of dollars per sample, takes specialized equipment most hospitals don’t have, and barely scales. But it’s the kind of data oncologists need to figure out whether immunotherapy will actually work for you. Right now, only about 20 to 40% of cancer patients respond to immunotherapy, and one of the biggest reasons is that doctors can’t easily tell whether a tumor is “hot” (immune cells actively fighting it) or “cold” (immune system ignoring it).
Microsoft, Providence Health, and the University of Washington trained an AI to analyze the $5 slide and predict what the expensive test would show across 21 different protein markers. They called it GigaTIME, trained it on 40 million cells in which both the cheap slide and the expensive test coexisted, and then turned it loose on 14,256 real cancer patients across 51 hospitals in 7 US states.
The results landed in Cell, one of the most selective journals in biology. The model generated about 300,000 virtual protein maps covering 24 cancer types and 306 subtypes. It found 1,234 real, verified connections between immune cell behavior, genetic mutations, tumor staging, and patient survival that were previously invisible at this scale. When they tested it against a completely separate database of 10,200 cancer patients, the results matched up almost perfectly (0.88 out of 1.0 agreement).
Nature Methods named spatial proteomics (mapping where specific proteins sit inside your tissue) its Method of the Year in 2024, and specifically cited GigaTIME in a March 2026 update as a model that “democratizes” this kind of analysis. The full model is open-source on Hugging Face. Any cancer research lab with archived biopsy slides, and most of them have thousands, can now run virtual immune profiling without buying a single piece of new equipment.
Satya Nadella@satyanadella
We’ve trained a multimodal AI model to turn routine pathology slides into spatial proteomics, with the potential to reduce time and cost while expanding access to cancer care.
English