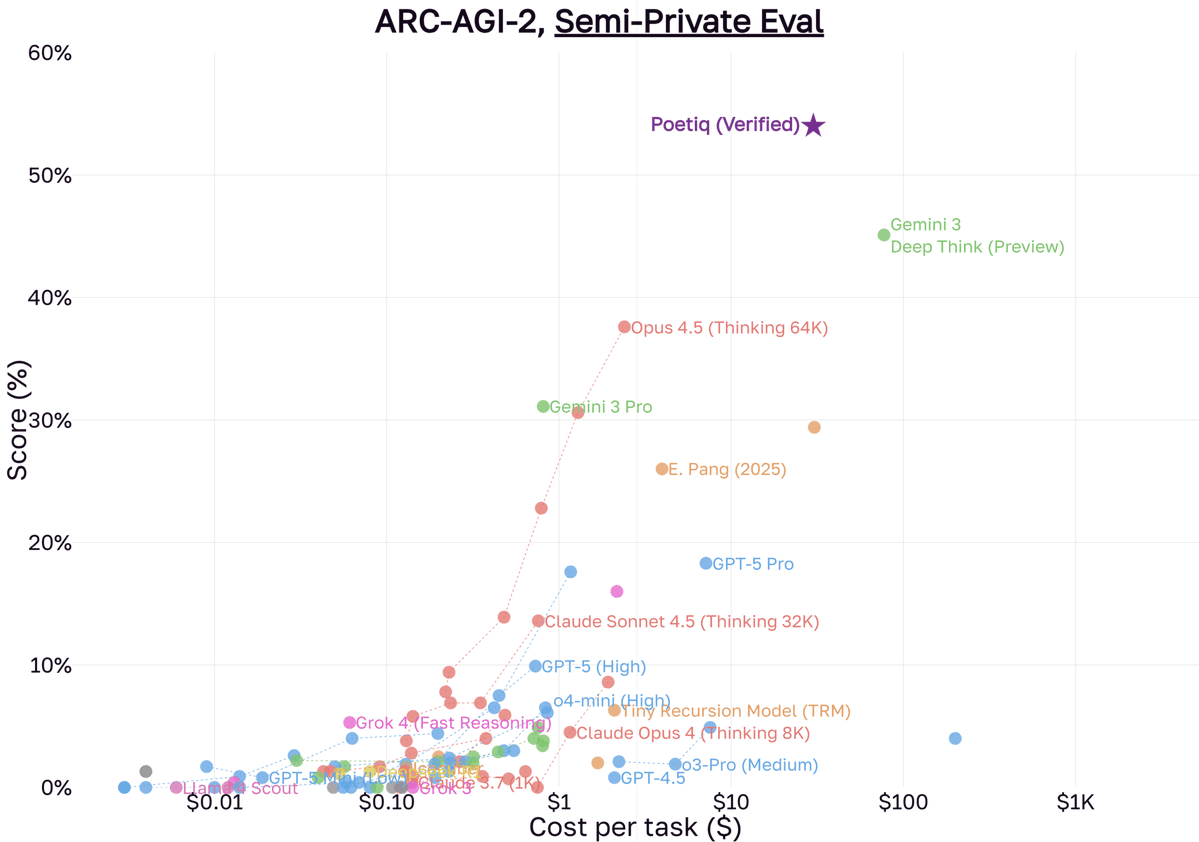
.@poetiq_ai is a new startup that recently achieved a major jump on the ARC-AGI benchmark by layering a recursive self-improvement system on top of existing models. In this episode of the @LightconePod, Poetiq's Founder & CEO @itfische joined us to discuss how small teams can build “reasoning harnesses” that outperform base models, what that means for startups and why automating prompt engineering may be one of the most powerful levers in AI today. 00:00 – Intro 00:40 – What Is Poetiq? 01:07 – Recursive Self-Improvement Explained 02:07 – The Fine-Tuning Trap 02:59 – “Stilts” for LLMs 03:14 – Recursive Self-Improvement vs. Fine-Tuning 05:05 – Taking the Top Spot on ARC-AGI 06:37 – Beating Claude on Humanity’s Last Exam 08:40 – How the Meta-System Works 10:26 – Beyond RL: A New S-Curve 11:32 – Automating Prompt Engineering 13:37 – From 5% to 95% Performance 14:50 – Early Access & Putting Your Agent on Stilts 16:17 – From YC Founder to DeepMind Researcher 18:29 – Advice for Engineers in the AI Era