Sabitlenmiş Tweet
maksim
393 posts


maksim
@ivanovm_
maksim @ agentic labs
fightertown us-east-1 Katılım Mart 2024
633 Takip Edilen168 Takipçiler


my situational awareness had to be liquidated after heavy losses
Will Manidis@WillManidis
staggeringly few of you have situational awareness at this point
English



New York City is incredibly, insanely overstimulating. does anyone have recs for places in Manhattan that will make me feel calm instead of evil and insane
English
@YangFanYun which harness? kimi models have been really bad at comp use in my testing
English

Kimi-K3 is no fluke: it clears GPT-5.6 Sol Max and takes second on NPP, the task we designed to be impossible to solve optimally, behind only Fable 5.

English
Today we're releasing Composite-Bench: a long-horizon computer-use benchmark with certified-optimal answers and verified compute.
The strongest open-weights model isn't Kimi K3. GLM-5.2 beats it by 32 points and clears every closed model we tested except Claude.

English

excited to have our contributions included in frontier-bench
Ryan Marten@ryan_marten
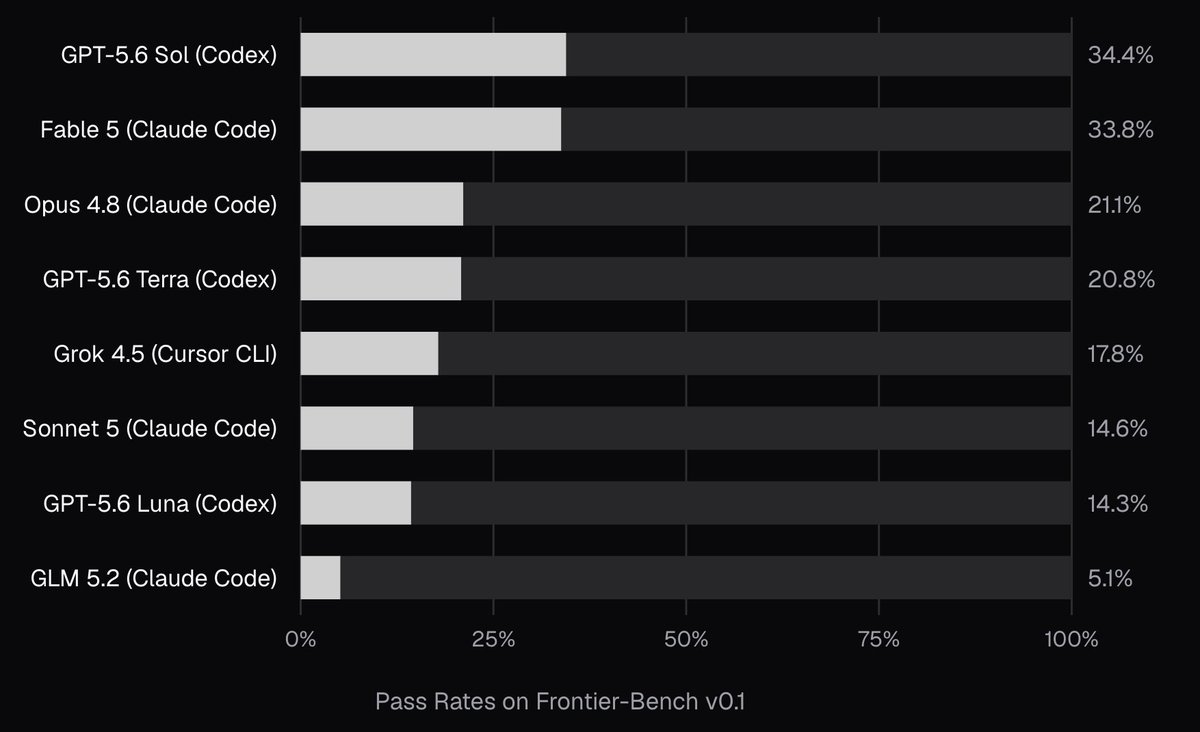
We’re releasing Frontier-Bench: a benchmark that measures and evolves with the frontier of agent work. Built by the team behind Terminal-Bench and Harbor, Frontier-Bench is an on-going community effort. Frontier-Bench v0.1 contains 74 tasks on which the best agents score ~34%
English
maksim retweetledi

We’re releasing Frontier-Bench: a benchmark that measures and evolves with the frontier of agent work.
Built by the team behind Terminal-Bench and Harbor, Frontier-Bench is an on-going community effort.
Frontier-Bench v0.1 contains 74 tasks on which the best agents score ~34%
English
@paulg @PatrickHeizer flying used to be much more expensive, and airport is full of people who can afford flying and thus must have money to spend.
English

@PatrickHeizer For many people shopping is a leisure activity, and passengers have a lot of enforced leisure at airports.
English

I will never understand the amount of commerce that occurs in airports.
Not against it, and I understand duty-free, forgot something, etc., but I'm a 'water bottle for the flight and maybe a small snack' type of fellow.
English
@growing_daniel hey @grok what % of s&p500 gains have been driven by ai in the last 3 years?
English

@RealRichomie most of these steps would not require building anything new
the infra built and scaled for distilling opus could easily be used to distill fable on day 0
English

I'm just trying to understand the timeline:
Jun 9: Fable 5 launches
Jun 12: Fable 5 access suspended
Jul 16: Kimi K3 launches
So in one month with Fable 5 having an interrupted and very limited testing window, kimi:
• built a large-scale distillation pipeline
• generated massive teacher traces
• cleaned the data
• trained a frontier MoE
• post-trained
• aligned
• benchmarked
• productionized
• launched
Either this is the fastest frontier AI execution ever recorded or someone really wants to get Kimi banned🤫
Director Michael Kratsios@mkratsios47
We have information that Moonshot AI distilled Anthropic’s Fable for the development of its K3 model. To do this they developed a sophisticated internal platform to conduct large scale distillation against U.S. models, allowing them to quickly switch between multiple methods of access to avoid detection. Moonshot AI has also acquired GB300-equipped servers and has accessed GB300s in Thailand, likely to train its AI models. The United States strongly supports the free and fair development of AI, including a thriving competitive ecosystem that spans frontier models, specialized systems, open-source frameworks, and open-weight models. Legitimate AI distillation used to create smaller, more efficient models plays a vital role in this open innovation ecosystem. However, large-scale, covert industrial distillation aimed at stealing proprietary U.S. technology and undermining American research is unacceptable.
English

@skeptrune your merge rules should randomly squash history and delete the codebase to prevent tech debt
English

i personally think code review is dead. the team does not agree. directionally found this surprising.

English