Sabitlenmiş Tweet

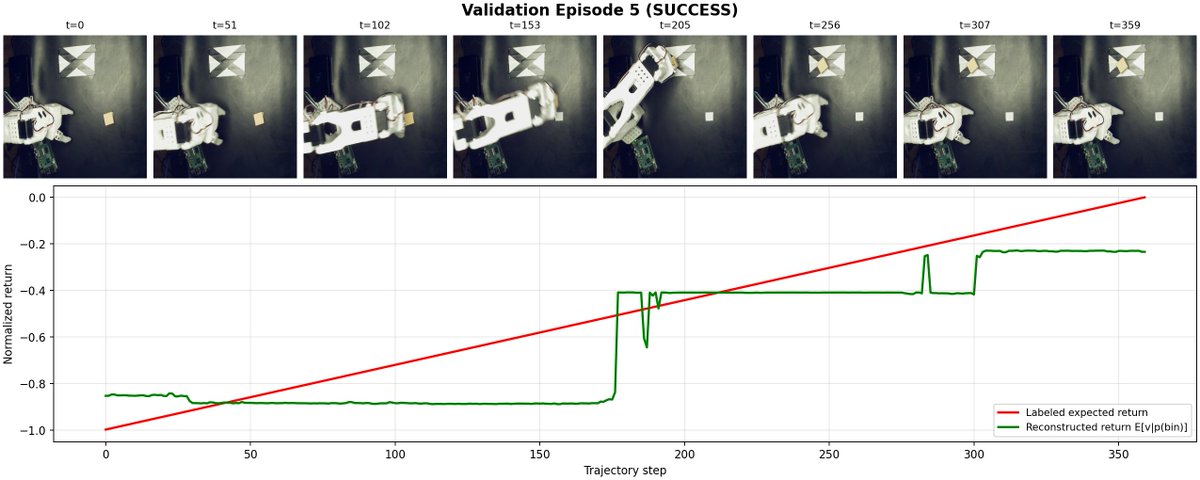
Distributed Real-Time Chunking!
I've written a technical blog post on the approach to deploying Real-Time Chunking via In-Painting on a remote cloud GPU server with local client (e.g. Raspberry PI) demonstrated in the video below jackvial.com/posts/distribu…
A LeRobot based implementation is available at github.com/jackvial/drtc this includes scripts to provision a GPU instance on Prime Intellect, connect via Tailscale, and should have everything (expect a model trained for your environment) needed to reproduce the experiments outlined in the blog post
Jack Vial@jackvial89
much smoother after applying a low pass Butterworth filter with a 3hz cutoff. this filters out high frequency small movements (aka noise) in the trajectory, it also naturally attenuates the signal so makes the robot move slower, I’ve added a bit of gain back to compensate and speed it up again after the filtering. still a bit jiggly, mainly in the shoulder pan but it seems to be mostly mechanical at this point
English