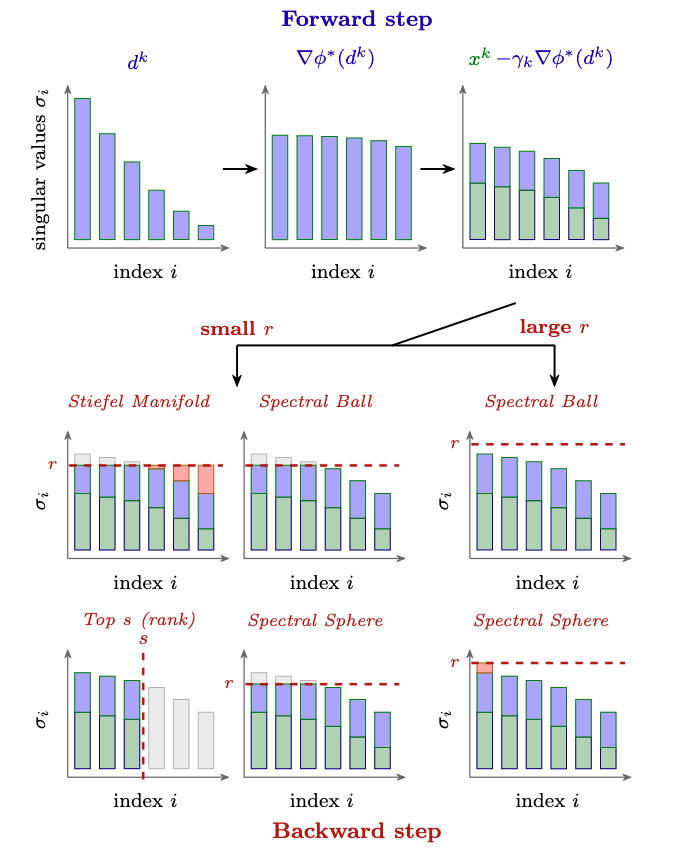
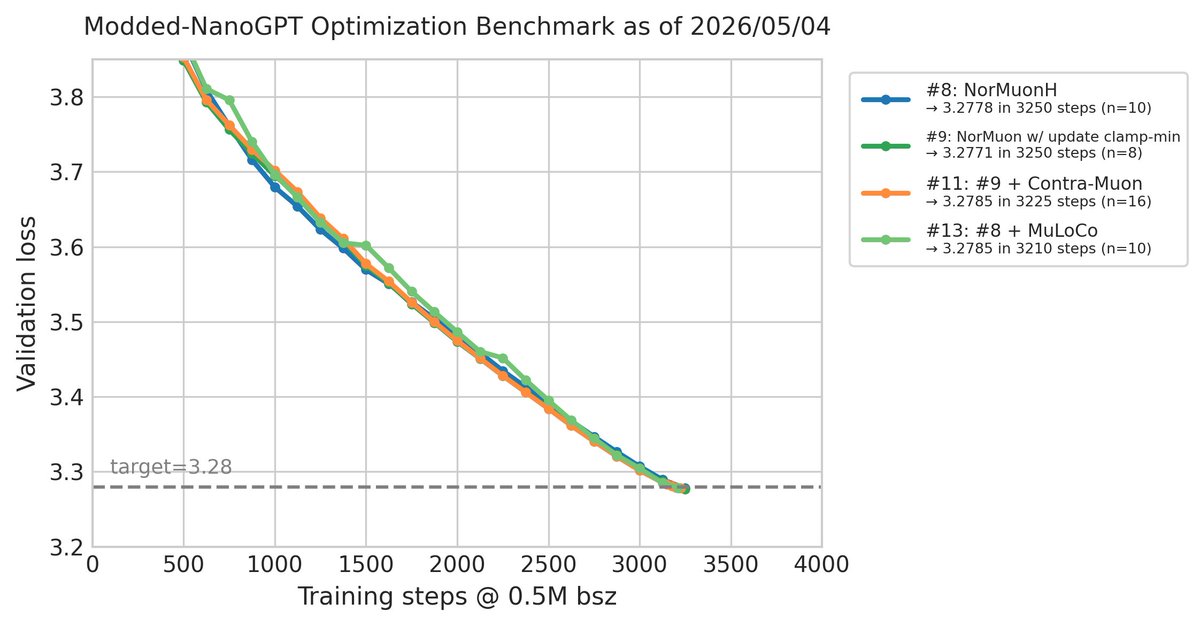
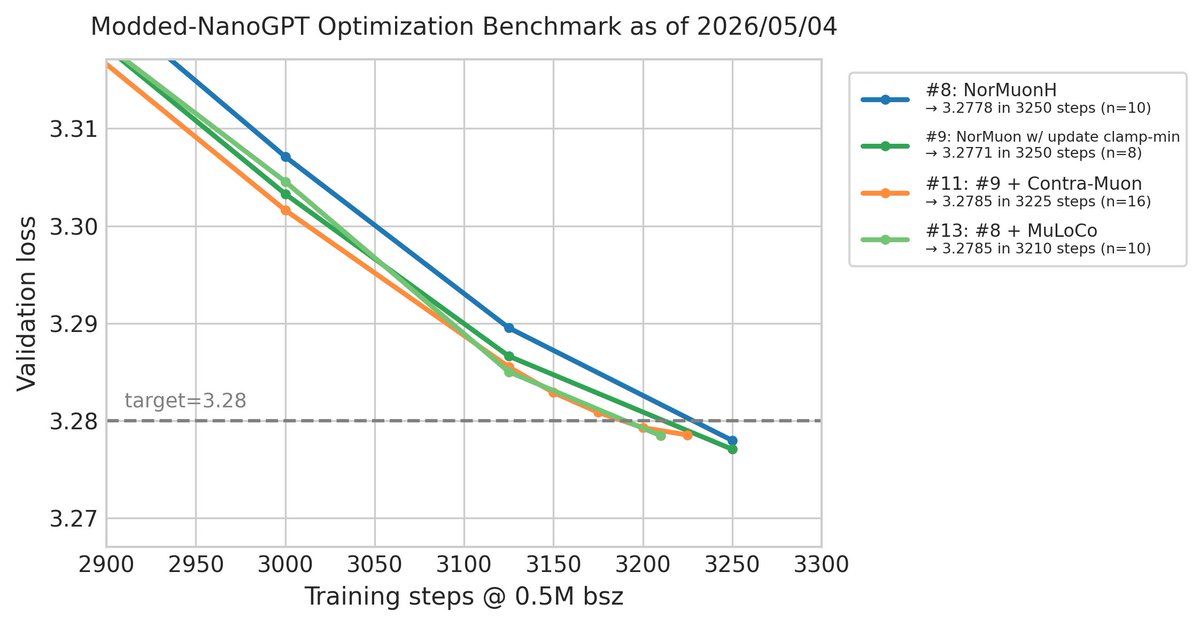
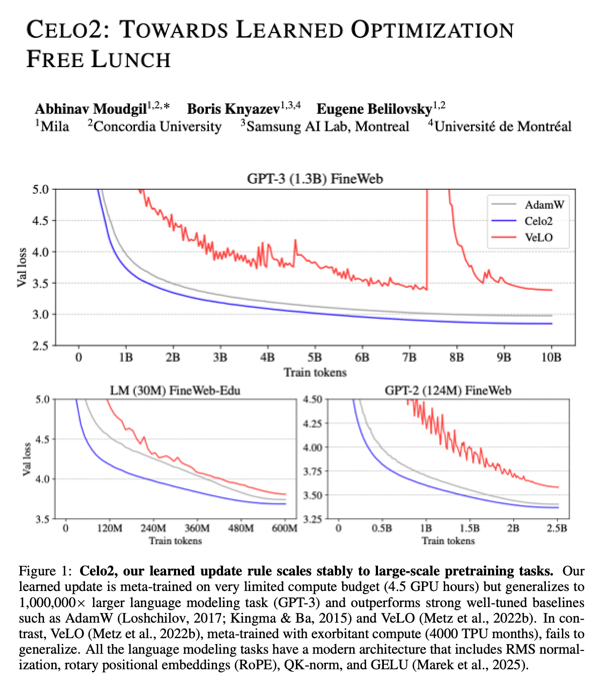
Sabitlenmiş Tweet

PyLO is accepted to MLSys 2026! 🎉🚀
A PyTorch-native library bringing SOTA learned optimizers to the codebases most of us actually use — with fast CUDA kernels and real speedups on large-scale training. Drop-in ready, no more JAX-only barriers.
Library: github.com/Belilovsky-Lab…
Paul Janson@janson002
Have you ever trained a neural network using a learned optimizer instead of AdamW? Doubt it: you're probably coding in Pytorch! Excited to introduce PyLO: Towards Accessible Learned Optimizers in Pytorch! . Accepted at @icmlconf ICML 2025 CODEML workshop 🧵1/N
English