Sabitlenmiş Tweet
Jeffrey
1.3K posts


Jeffrey
@jefcodes
cs @uwaterloo
waterloo (i was born here) Katılım Mart 2024
719 Takip Edilen758 Takipçiler


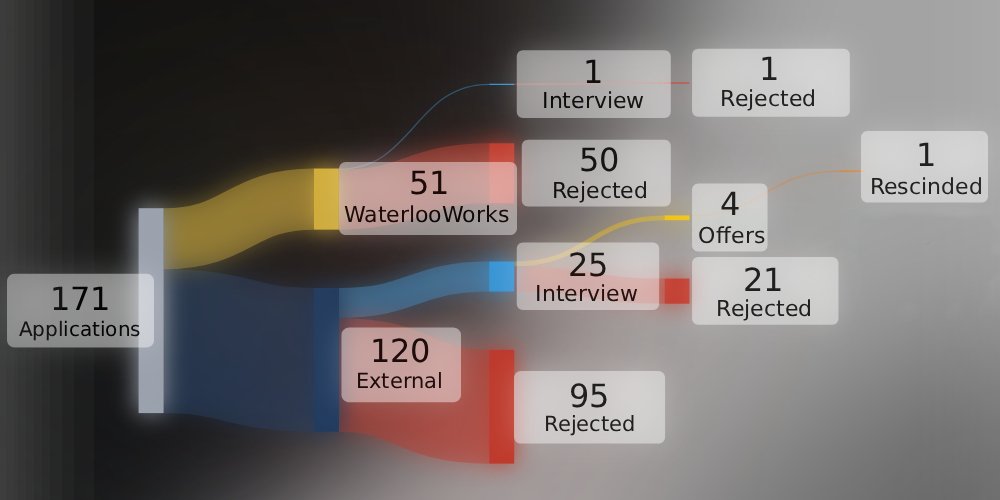
life update: I just wrapped up recruiting around a week ago (it's never too late)
Excited to join @getaleph as the first ever software engineering intern!
First co-op search has been one of the most stressful yet rewarding stretches of my life
Can't wait to do actual work instead of grinding technical prep
English



Robert Chang reveals the only reason Luel AI raised $31.2M is because the founder’s father is incredibly powerful
“They obviously forked Kled. I don’t think Luel AI is worth that much. Because the founder’s dad is some incredibly powerful person in the United States. That’s why they were able to raise money. The idea itself is basically just a shell”
“I think Luel AI is a complete setup. I don’t think the founders actually went into YC intending to build something meaningful and raise money for this kind of product”
“Just search the kid’s name, then look up his father online, and look at the investors that invested”
English
Jeffrey retweetledi

Medicine only works if it reaches people
That's why we're building agents that navigate the intricacies of healthcare end to end, accelerating medicine for those who need it, prescribe it, and create it
Proud to share Forus and $160M raised!
English





GPT-5.5 is going to have a party for itself. it chose 5/5 at 5:55 pm for the date and time.
if you'd like to come, let us know here: luma.com/5.5
codex will help the team pick people from the replies. 5.5 had some good ideas/requests for the party, which we'll do.
English

we're subleasing the place
dm me if you need a place to stay in SF starting May
Connor Loi@connortbot
every YC founder lives in the landing when they could be living with this roof instead you can watch an entire baseball game at oracle man 😭
English
Jeffrey retweetledi

I added KV caching and INT8 KV quantization to our transformer inference, improving throughput by 35x.
All of this was done from scratch in Rust + CUDA, on top of a homemade ML framework.
On a 4-token prompt with 252 generated tokens:
- Original: 0.76 tok/s
- KV cache fp32: 27.21 tok/s
- KV cache int8 (quantized): 27.29 tok/s
Try it out yourself here: mni-ml.github.io/demos/kv-cache/
In practice:
- KV caching gave us about a 35x end-to-end speedup
- INT8 KV cache kept roughly the same speed as fp32 but cut KV cache memory by 3.78x
FP32 cache used 4.5 MB in this run while the INT8 cache used only 1.19 MB
This simple change to inference created a huge impact on performance. To learn more about the KV cache and other optimizations like this, check out the blog at mni.ml!
English
Jeffrey retweetledi

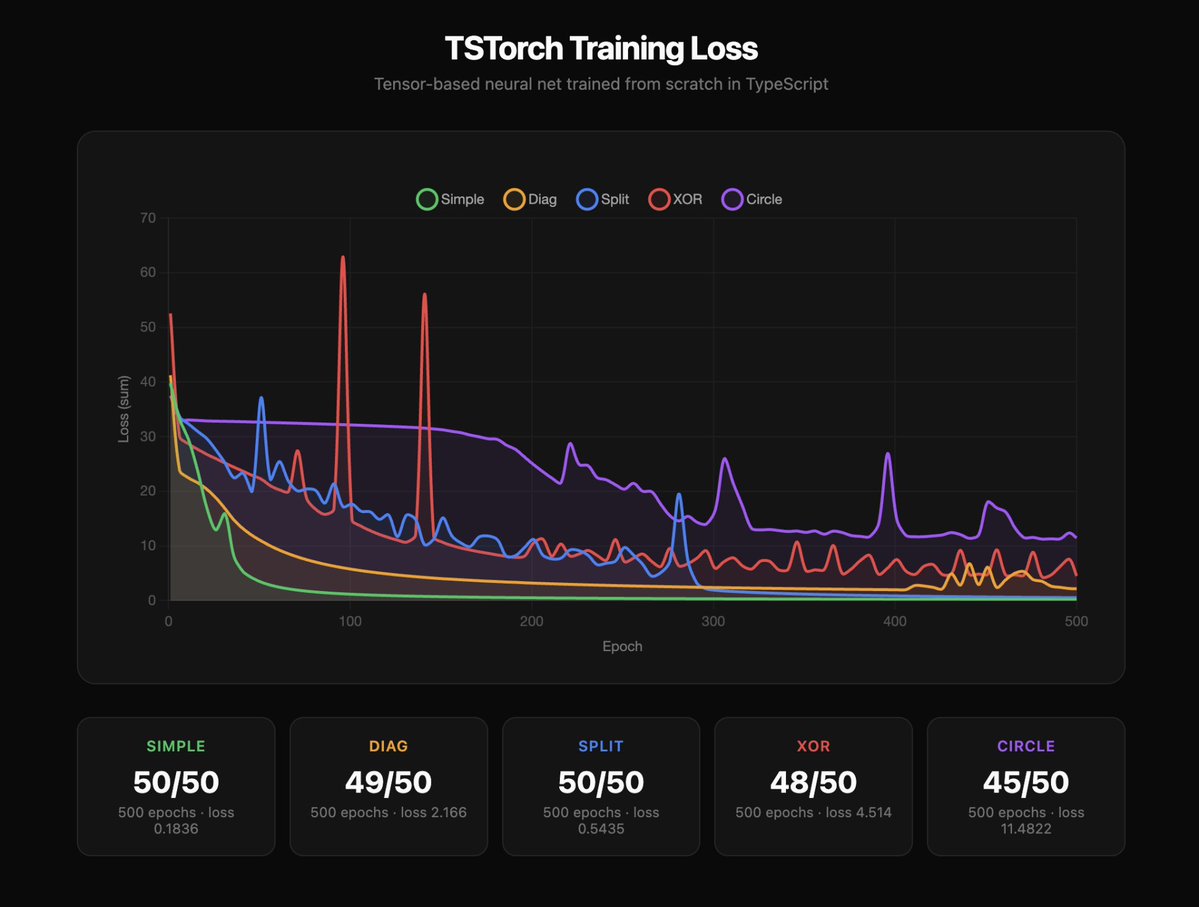
I built a neural network from scratch without using PyTorch, TensorFlow, or any libraries for that matter. Instead, I implemented the core math myself.
I'm working on making my own machine learning framework from scratch with my friend @_reesechong. He previously trained a similar neural network, but using just scalars.
The next step was to use tensors instead. The benefit of this is clear: when using scalars each data point is looped through separately creating its own node in a computation graph.
With tensors, these separate nodes are stored together, allowing one forward and backward pass for the whole batch, greatly improving the efficiency of training.
We often hear the saying "don't reinvent the wheel", but in my experience rebuilding technologies that abstract away a lot of complexity gives you a better and more thorough understanding of how the system works.
Results of the training are shown below. Feel free to checkout the repo and read through the code, linked in the replies.

English





Horizon is finally here. Connect claude or poke to give them access to your d2l and piazza.
Lock in now (horizon.hamzaammar.ca/onboard)
English

Jeffrey retweetledi
socratica symposium ’26 dinner
@lucashjin
@josh_soupy
@jefcodes
@moulikb_
@rohanthmarem
@virkvarjun
@casperdongg
@danielchingwq
@sofiiabodnar
@Tpypan
@zanebeeai
@anirudhbv_ce
@irenekoo9




English



