Joe Wu retweetledi

Joe Wu
1.2K posts



🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×. 📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens. 🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale. 🔗 github.com/deepseek-ai/De… #vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning

















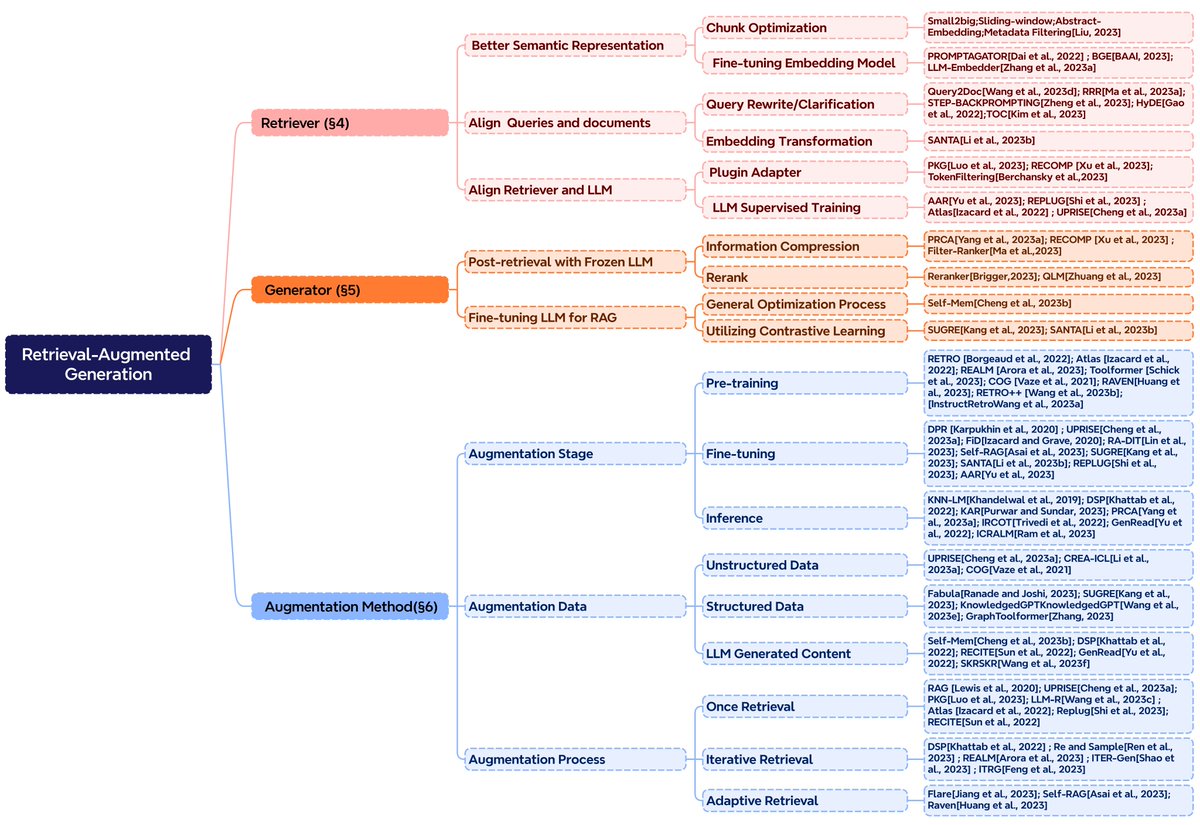
RAG 综述,建议每个做大模型应用的都读下。 非常不错的总结。 arxiv.org/abs/2312.10997