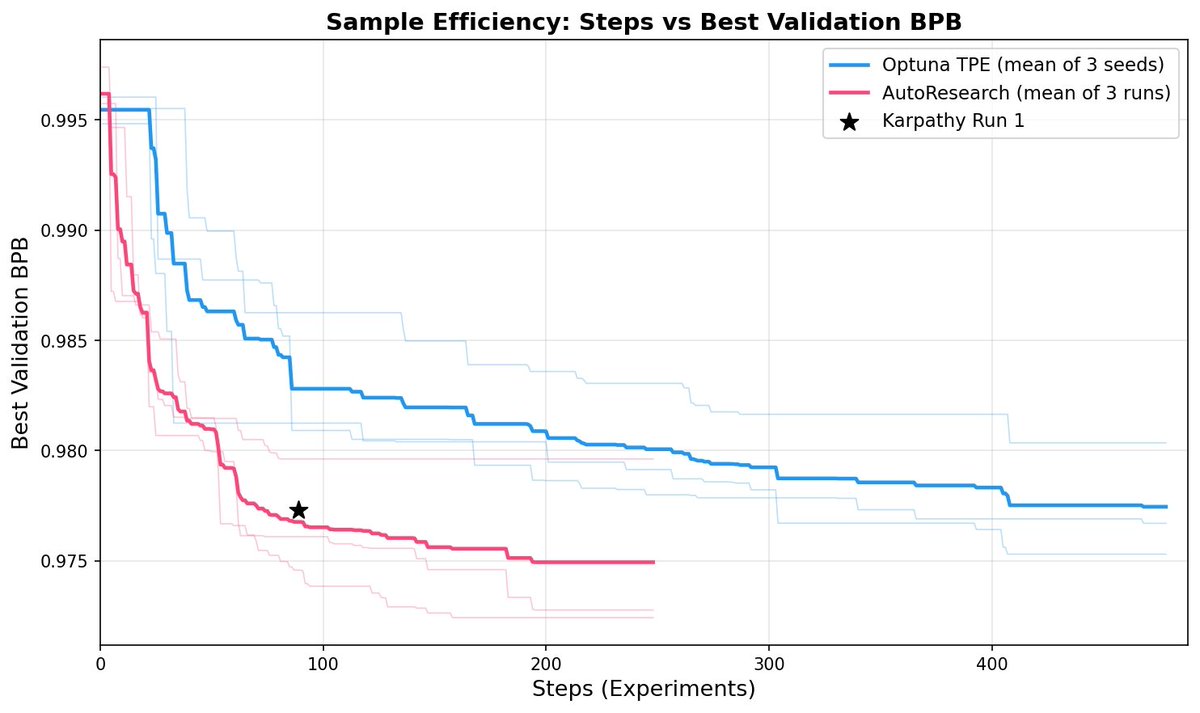
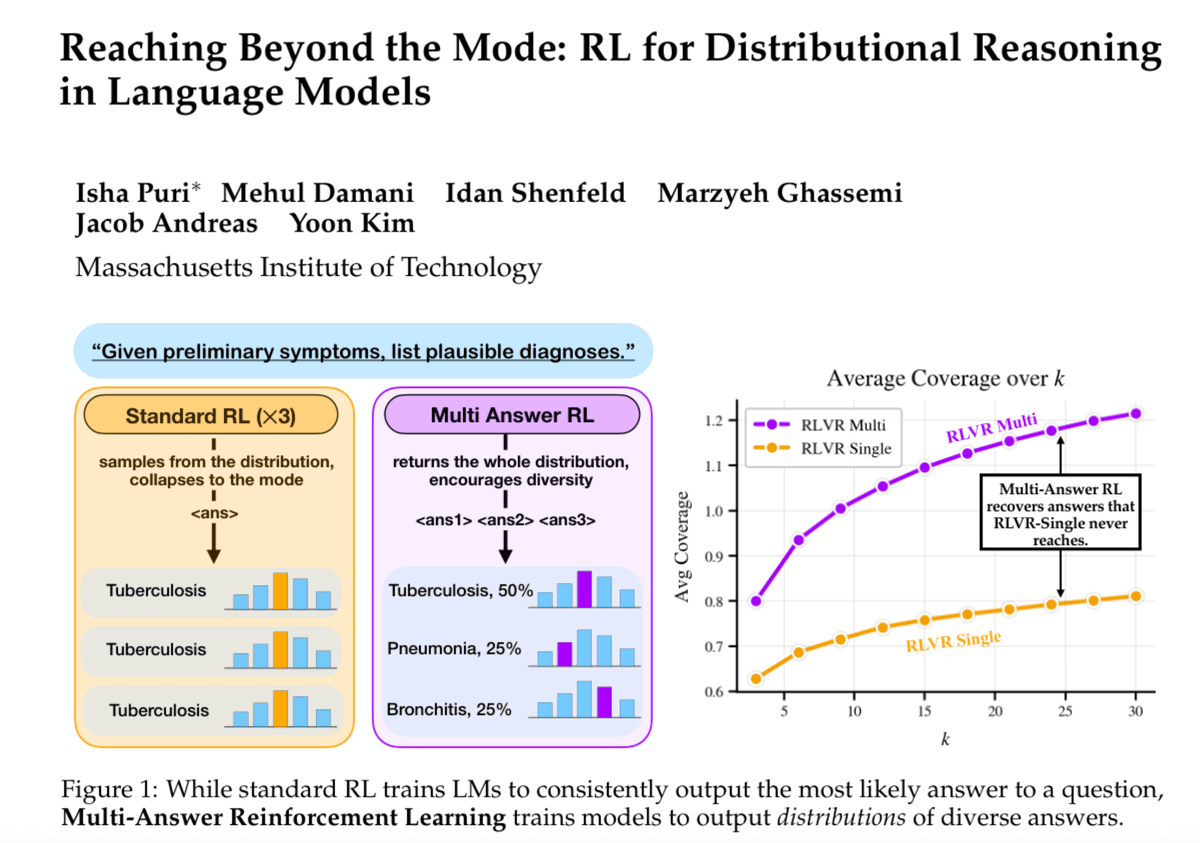
Sabitlenmiş Tweet

Our paper CTRL-D is accepted to ACL Findings and will be presented at ACL 2025!
🗓️Poster session: 18:00–19:30 (Level 0 Exhibit Halls X4/X5)
I’m sad I can’t be there, but Jordan (@boydgraber) will! You’ll enjoy learning about CTRL-D from him.
Now… what is CTRL-D? 🔍

English