
Muratti
1.2K posts

Muratti
@judoproca
Software Engineer / ML Engineer. Fitness competitor 🏋🏻♂️💪🏻
Katılım Ekim 2013
344 Takip Edilen287 Takipçiler
Agreed, @rrhoover. I started working on this gap awhile ago because the current state of strength tracking is frustrating. Today, I have an Apple Watch app (Autobody) that automatically detects and analyzes 80+ weightlifting exercises, delivering the proper tracking and analysis the category is missing. Would love to hear your feedback on it
x.com/judoproca/stat…
English

The wearable category is sleeping on strength training. I’ll be customer #1.
Miranda Nover@mirandanover
What we’ve been working on
English
@levelsio That was exactly my frustration with strength training apps, which is why I built Autobody. I spent months collecting data in the gym and training models to automatically track form and reps for 80+ exercises using just the Apple Watch—even for leg movements.
It counts your reps in real-time (with haptic feedback) as you lift, and provides detailed form analysis immediately after the set is finished. No more manual logging. Would genuinely love your feedback. (Link in reply!)
English

Either @WHOOP starts tracking strength training properly or all of us lifters will just move to whatever wearable does
@willahmed
Ryan Hoover@rrhoover
The wearable category is sleeping on strength training. I’ll be customer #1.
English

If you have plans to time travel soon, make sure you use the Ethiopian Calendar.
English
@WealthCoachMak Hi, I wanted to ask 2 questions. How often you take trades (daily, weekly?) and how much do you need to monitor the intraday market? or you just check the beginning and at the end of the day? How much time do you spend in all of that?
English

When you SELL a weekly option you don’t have to keep monitoring the option on a constant basis
If you BUY a weekly option then you better keep monitoring it on a constant basis
As an Option Seller I own the time
Just pick strike prices you are comfortable with 🔥🔥
💰💰💰
English

Night owl → Early bird
Last 2 weeks I have been sleeping early and waking up around 4am or 5am. I sleeping well and my productivity has gone up all time high.
By noon I'm done with most of the trivial work. Never though I could actually wake up so early, but I can clearly see the difference. I used to be tired, grumpy and swollen eye lids. Now I feel energized and productive!
English

The most valuable company in our lifetime will be a humanoid robot company
Close to half of GDP is human labor, its many factors larger than the entire transportation market
English

phone addiction might be one of the biggest unsolved problems right now
everyone knows it's destroying us. everyone wants it fixed. current solutions fail.
whoever figures this out becomes a billionaire and a hero to millions
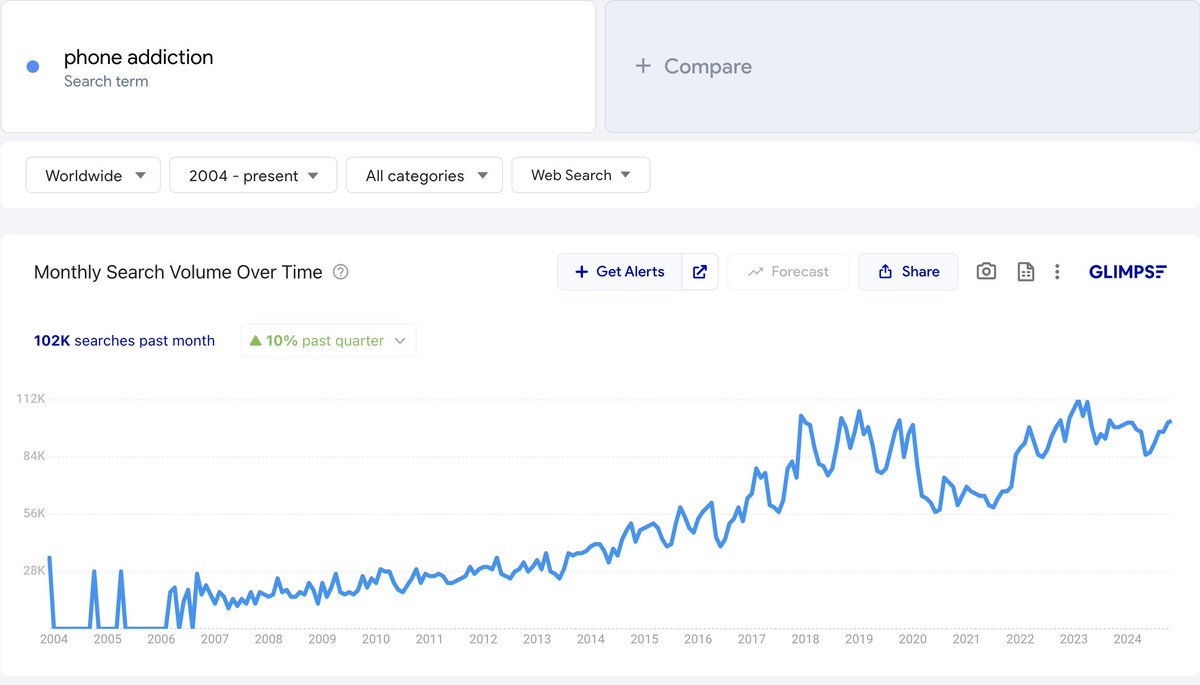
English
Exciting news - today, Figure officially became a revenue-generating company!
This week, we delivered F.02 humanoid robots to our commercial client, & they're currently hard at work
It marks 31 months from filing our C-Corp to getting to humanoid robot revenue

English

I’m going to start hosting dinners at my apartment in San Francisco for 8-10 people twice per month.
If you are a founder, and especially if you are NOT a founder, and you would like to come for an evening of good food and conversation, send me a DM!
First dinner is Dec 5!
English
I was a competitor in fitness/bodybuilding even then I wasnt eating more than 250gr protein a day. there are pry a handful of people in bodybuilding that eats that much and those are the absolute beasts (think of 300lbs ones) and you would need additional supplements to digest it all. the rule of thumb is 1-1.2gr protein per lb of bodyweight if you are exercising is enough
English

I ate 500g protein / day for 2 weeks. I don't know how carnivores do it.
I was constantly sluggish, tired and sweaty. Belly full of meat from breakfast until bed. Even woke up feeling full half the time.
You guys just live like this?
How many g protein are carnivores eating?
English
@Petertaughtme what was their marketing like? Curious how they approached it and caught great traction in a crowded market.
English

How a dieting iPhone app made $1M last month with 80k downloads on the iOS app store

English
genuine question, why not use the same structure as a human hand (as in number of fingers, number of joints, degree of movement etc) rather than evey robot company trying to invent something new (6 fingers, clap fingers...) if eventually the are gonna be doing what humans do, isnt that a solved problem? i understand actual mechanics might be different (motors, actuators, software etc ) but im wondering about the general design?
English
It's now clear that truly capable hardware has been the key obstacle to advancing general-purpose robotics
To build the best AI company in the long run, there is no substitute for good hardware...it's a critical dependency
From day one, Figure went all-in on owning our hardware. And it wasn't cheap. When the company was just 6 months old, I was already funding $1M/month. If you want to build a robotics company, you must confront the complexity head-on
To achieve these hardware capabilities, Figure assembled a world class team of over 100 hardcore engineers to design the entire robot from scratch
This team designs systems from the ground up to meet high performance requirements, including motors, actuators, thermal systems, electronics, structures, sensors, firmware, embedded software, and even hands
And remember, every piece of hardware needs software - even our lights have custom firmware 🫠
There is still a lot more to go on the hardware maturity front but what's exciting is the AI progress we are making today on top of this hardware platform. If you are somebody interested in designing AI systems for robots that can learn and reason like humans come join our team
Figure will continue to build in public and share our process. Exciting updates are coming :)
English
@orrdavid @lebron_ex how does the concierge health works if you need to get a surgery? or do you negotiate the surgery costs too when paying cash?
English

@lebron_ex No you just don't have health insurance at all, and plug into concierge health care and pay cash.
High deductible liability insurance is different,
English
To have near the quality of life as Bezos the real number is $15 million. Or $20 million with many kids
At that number you have total freedom to do most anything within some reason. You still can't constantly get VIP tickets at concerts. But you can travel as much as you want and stay at very nice hotels. And the money still should grow gradually, especially if the first few years you don't slam the gas.
If you want to fly private sometimes you probably want another $10 million. Or fly private often then another $25 million.
Anything more than this is really just a score card. If you enjoy it, great. But if not you're letting the money own you.
Harrison Schenck@FractionalList
This is the whole secret
English
@AshandyTemi I'd do 56+30 then minus 1, I saw couple other people replied the same way, i dont remember anyone teaching me that so its interesting how different people arrive this methodology on their own 🤔
English

I have been seeing a lot of Vodaphone eSim ads for travel to Europe, I'd say check em out. I also used Tmobile with int'l data that works too but you have to change your current carrier, vodaphone is an easier option where you keep existing carrier, just use vodaphone in Europe via the esim
English

We are NOT big international travelers:
Son is going to Italy to ride his bike
We have Verizon Wireless
Do we get the international calling plan?
Extra $100 for the month or $10 a day
Do we need this?
English


Muratti@judoproca
It sounds great but then I was thinking why does it sound familiar? Then i remembered reading a paper with a similar architecture which was published before - called 1-bit LLMs, basically you can represent 3 states (-1,0,1) with 1.58 bits hence the name. Not sure how this paper is different. arxiv.org/html/2402.1776…
QME

If this is accurate, then NVIDIA's grip on the tech industry has just vanished.
Matrix matrix multiplication (MatMul) is notoriously computationally difficult, which is why it's offloaded to GPUs.
If MatMul can be avoided, then it's not just leveling the playing field. It's creating new playing fields.
Rohan Paul@rohanpaul_ai
This is really a 'WOW' paper. 🤯 Claims that MatMul operations can be completely eliminated from LLMs while maintaining strong performance at billion-parameter scales and by utilizing an optimized kernel during inference, their model’s memory consumption can be reduced by more than 10× compared to unoptimized models. 🤯 'Scalable MatMul-free Language Modeling' Concludes that it is possible to create the first scalable MatMul-free LLM that achieves performance on par with state-of-the-art Transformers at billion-parameter scales. 📌 The proposed MatMul-free LLM replaces MatMul operations in dense layers with ternary accumulations using weights constrained to {-1, 0, +1}. This reduces computational cost and memory utilization while preserving network expressiveness. 📌 To remove MatMul from self-attention, the Gated Recurrent Unit (GRU) is optimized to rely solely on element-wise products, creating the MatMul-free Linear GRU (MLGRU) token mixer. The MLGRU simplifies the GRU by removing hidden-state related weights, enabling parallel computation, and replacing remaining weights with ternary matrices. 📌 For MatMul-free channel mixing, the Gated Linear Unit (GLU) is adapted to use BitLinear layers with ternary weights, eliminating expensive MatMuls while maintaining effectiveness in mixing information across channels. 📌 The paper introduces a hardware-efficient fused BitLinear layer that optimizes RMSNorm and BitLinear operations. By fusing these operations and utilizing shared memory, training speed improves by 25.6% and memory consumption reduces by 61% over an unoptimized baseline. 📌 Experimental results show that the MatMul-free LLM achieves competitive performance compared to Transformer++ baselines on downstream tasks, with the performance gap narrowing as model size increases. The scaling law projections suggest MatMul-free LLM can outperform Transformer++ in efficiency and potentially in loss when scaled up. 📌 A custom FPGA accelerator is built to exploit the lightweight operations of the MatMul-free LLM. The accelerator processes billion-parameter scale models at 13W beyond human-readable throughput, demonstrating the potential for brain-like efficiency in future lightweight LLMs.
English