
z
19 posts





@julzebadua I simply asked an LLM to generate an HTML animation based on my description and some basic style recommendations.
English
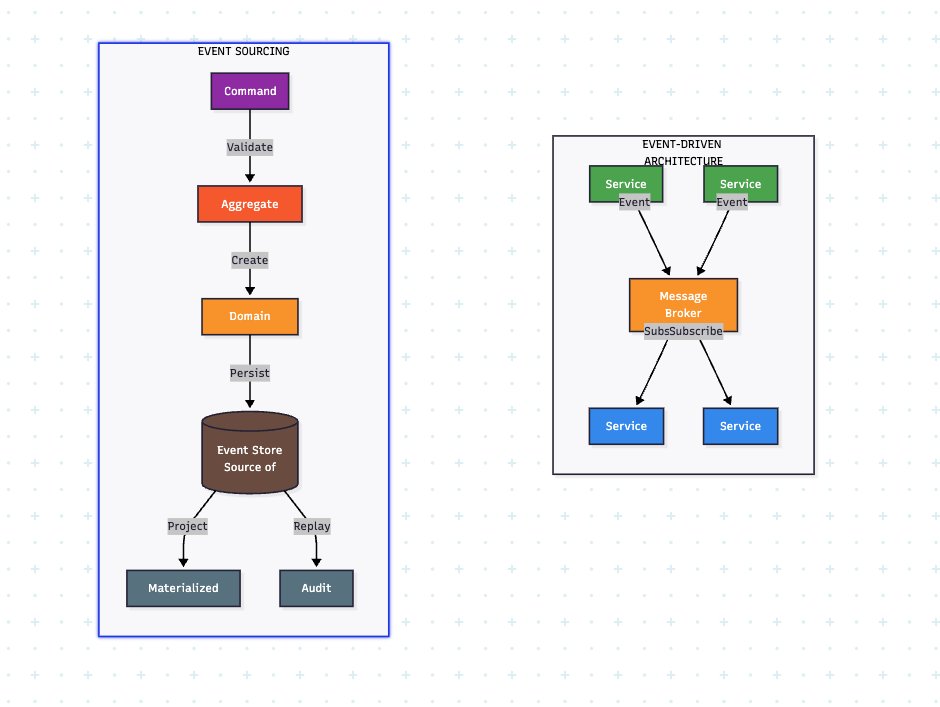
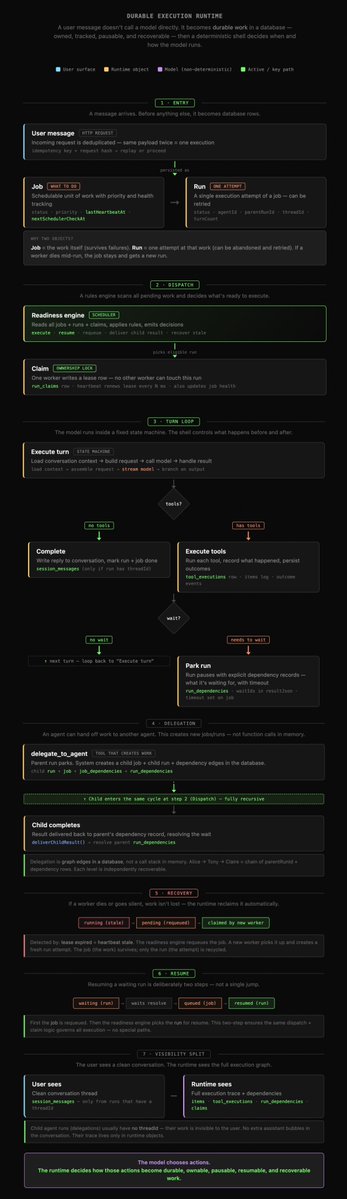
Some details about the agentic logic I've been working on over the past few days.
--context:
this is a mix of an execution graph with clear dependencies, a partially deterministic heartbeat-based orchestrator, and event-driven observability.
- Queue: requests become jobs (work units) and runs (attempts), and they're durable, so they can survive crashes, be resumed later, or automatically retried
- Dispatcher: deterministic logic that always asks the same question: which job/run pair is actionable right now. So the same state always produces the same next step and parent/child ordering remains stable
- Claiming: before executing a run, a worker claims it so nobody else executes the same run at the same time, which avoids double execution and race conditions
- Heartbeat: while the run is being executed, the worker keeps renewing that claim, so long tool calls or model calls remain safe
- Recovery: if something goes wrong, the fact we have an execution graph and durable state lets us recover automatically and resume from the latest durable point. It also tries to heal itself
- Delegation: when an agent delegates a task, it enters `waiting` state and child job/run objects are created with proper parent-child relation. The parent does not need to remember in memory what it's waiting for and we have clear information about who waits for what
- Waiting: logic involves waiting for a child agent to finish, tool confirmation, or human response, so the system can survive long pauses
- Resume: it's pretty much deterministic, as continuation gets resolved from the current waiting/dependency state of jobs and runs
- Events: important transitions are emitted as events, so we get a clear stream that can be used for UI, projection, and observability. But the main source of truth is still the database state, not events alone
tbc
English

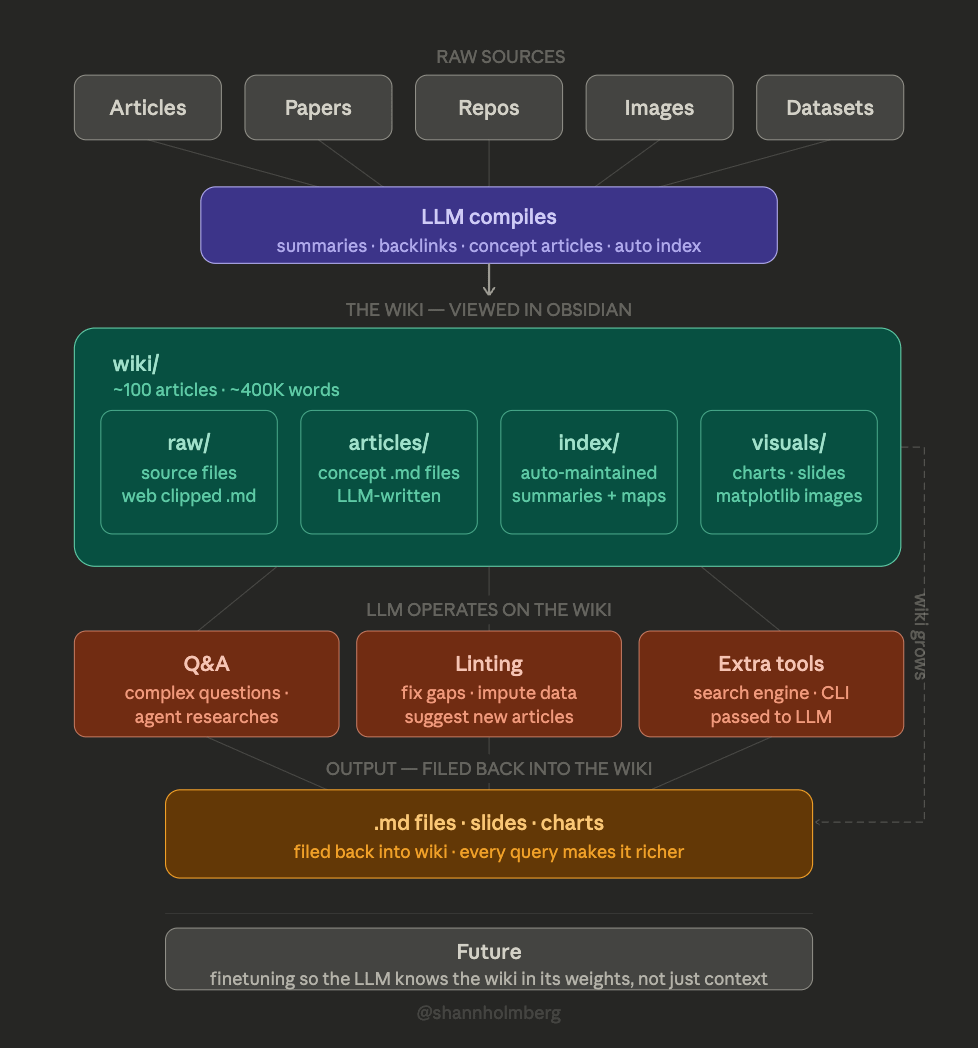
how karpathy builds a personal AI knowledge base with obsidian
most of his token spend is shifting from code to knowledge management
he dumps everything he's researching into one folder. articles, papers, repos, datasets, images
then he points claude at the folder. it reads through every source, writes summaries, groups related ideas, links concepts across documents, and builds a structured wiki in markdown
all viewable in Obsidian. karpathy rarely edits the wiki himself, the LLM maintains it
when he adds something new, it figures out how it connects to whats already there and updates the wiki on its own
his wiki is at ~100 articles and ~400K words. at that scale he queries it like a research engine:
> "what are the common patterns across these papers"
> "what connects this new idea to something I saved weeks ago"
> "summarize everything on topic X and tell me whats missing"
every answer gets filed back into the wiki. so it grows from both what you save and what you ask
he runs "health checks" too. the LLM finds inconsistencies, fills gaps with web searches, and suggests new directions
he skipped RAG and vector databases entirely. the LLM auto-maintains index files and reads related docs on its own at this scale
right now you need Obsidian, CLI tools, custom scripts, and browser extensions to wire it together
"I think there is room here for an incredible new product instead of a hacky collection of scripts"
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English

took karpathy's wiki pattern and wired it into my 10 agent swarm
and here is what the architecture looks like when you make it multi agent:
>every agent auto dumps its output into a raw/ folder as it works
>a compiler runs every few hours and organises everything into structured wiki articles grouped by domain.. infrastructure, signals, content, technical patterns. backlinks, an index.. they're all auto maintained
but the problem is that raw data is dangerous when it compounds cause one hallucinated connection enters the brain and every agent downstream builds on it..
so since hermes is my supervisor for my swarm he sits between drafts and live as the review gate...
every article gets scored before it enters the permanent knowledge base so clean outputs get promoted and bad ones just die in drafts
once articles are live, per-agent briefings get generated so each agent starts with exactly the context it needs instead of waking up blank
and this is where it matters that Hermes is a separate system..
it is not part of the swarm it is supervising bascially an agent reviewing its own swarm's work..
and what's interesting that hermes has no context about how the work was produced so no bias toward keeping it so it just reads the article and asks
is this accurate?
should this enter the permanent brain?
now we have openclaw handles the execution.. running agents, routing tasks, managing channels, dispatching crons and hermes handles the judgment.. reviewing what the swarm produced and deciding what deserves to persist.
the wiki brain ties them together.
>agents produce raw material
>the compiler organises it
>hermes validates it
>briefings feed it back to agents
>the loop runs
ps: you can use any separate agent as the review agent but hermes is great here because nous research literally trains it with structured outputs, function calling, and evaluation-style reasoning and this is the exact traits you want in a review gate..
and when that review gate is processing hundreds of articles, i think consistency in this case would matter more than raw intelligence..

English

What happens to your codebase when you stop reviewing your agents' output
English
English

How soon till @linear launches a replacement for Notion? I want my knowledge base to be in the place where my work is happening.
There I said it, @karrisaarinen.
English

99% of Claude Code users don't know this
by default it uses basic text grep to search your codebase. it doesn't understand your code at all
that's why it takes 30-60 seconds to find a function and sometimes opens the wrong file entirely
there's a setting that makes it ~900x faster and 100% accurate
it's called LSP (Language Server Protocol)
instead of grep searching 847 matches across 203 files... it calls goToDefinition and lands on the exact line in ~50ms
next week I'm dropping a full breakdown on how to set it up

English




z retweetledi



@LinusEkenstam I feel you man , my daughter was there last year good vibes man
English

Day 3, my daughter is doing a lot better.
We’re getting world class healthcare, she has started to eat/drink for her own machine.
Thank you everyone for your kind messages and understanding/respecting my priorities 🫶🏼

Linus ✦ Ekenstam@LinusEkenstam
Currently unavailable for everyone looking to get a hold of me. Sorry. My kiddo is at the ER and she is doing alright. But will be at the hospital for the next couple of days. if super urgent, email me or whatsapp.
English


z retweetledi

We recreated this Lottie animation in Rive.
Lottie file is 181.7 KB.
Rive file is 18 KB.
Lottie GPU memory: ~149 MB-190 MB
Rive GPU memory: 2.6 MB
Lottie JS heap: 16.9 MB
Rive JS heap: 7.3 MB
Lottie CPU: 91.8%
Rive CPU: 31.8%
English

Anyone have production experience with Clickhouse (incl hosted versions like Yandex Clickhouse, Tinybird, Altinity) or Firebolt or similar systems?
English