Sabitlenmiş Tweet

Meet Strix, my AI agent
This one covers:
- an intro from Strix
- architecture deep dive & rationale
- helpful diagrams
- stories
- oh my god what's it doing now??
- conclusion
timkellogg.me/blog/2025/12/1…
English
Tim Kellogg
18.9K posts

@kellogh
AI architect // hiking, camping and long walks on the beach as long as they involve backpacking




Since people really want me to say this: "KIMI K2.5" ‼️ Yes, that is the base we started from. And we are following the license through inference partner terms (e.g. Fireworks) I'm thankful for OSS models personally, good for the ecosystem.

Altman admitted that transformer models have hit the wall. Most improvements in the last 9 months are attributable more to the tooling around the model rather than the models themselves. In other words, this technology is rapidly maturing with no signs of another leap.

minimax 2.7 apparently.

oh substack plug. basically this entire conception of alignment to instruction-following predates LLMs and the premise, the "value-loading problem", is not true. i wrote it up previously verysane.ai/p/alignment-is…
Residual connections and pre-norm are not the whole story behind depth utilization. Our new paper shows that many seemingly different design choices — MoE, grouped-query attention, weight decay, and longer sequence length — can be understood through one unifying lens: sparsity. These components induce different forms of sparsity, which reduce output variance and in turn preserve healthier gradient flow across depth. Strikingly, these techniques also complement each other remarkably well: when combined, they lead to substantial improvements in depth utilization and notable gains in downstream accuracy. Paper page: pumpkin-co.github.io/SparsityAndCoD/ Arxiv: arxiv.org/pdf/2603.15389 Leading by @pumpkinnnnne




2 new Stealth models on OpenRouter Hunter Alpha: - "Hunter Alpha is a 1 Trillion parameter + 1M token context frontier intelligence model built for agentic use. It excels at long-horizon planning, complex reasoning, and sustained multi-step task execution, with the reliability and instruction-following precision that production agentic pipelines demand" Healer Alpha: - "Healer Alpha is a frontier omni-modal model with vision, hearing, reasoning, and action capabilities. It brings the full power of agentic intelligence into the real world: natively perceiving visual and audio inputs, reasoning across modalities, and executing complex multi-step tasks with precision and reliability"

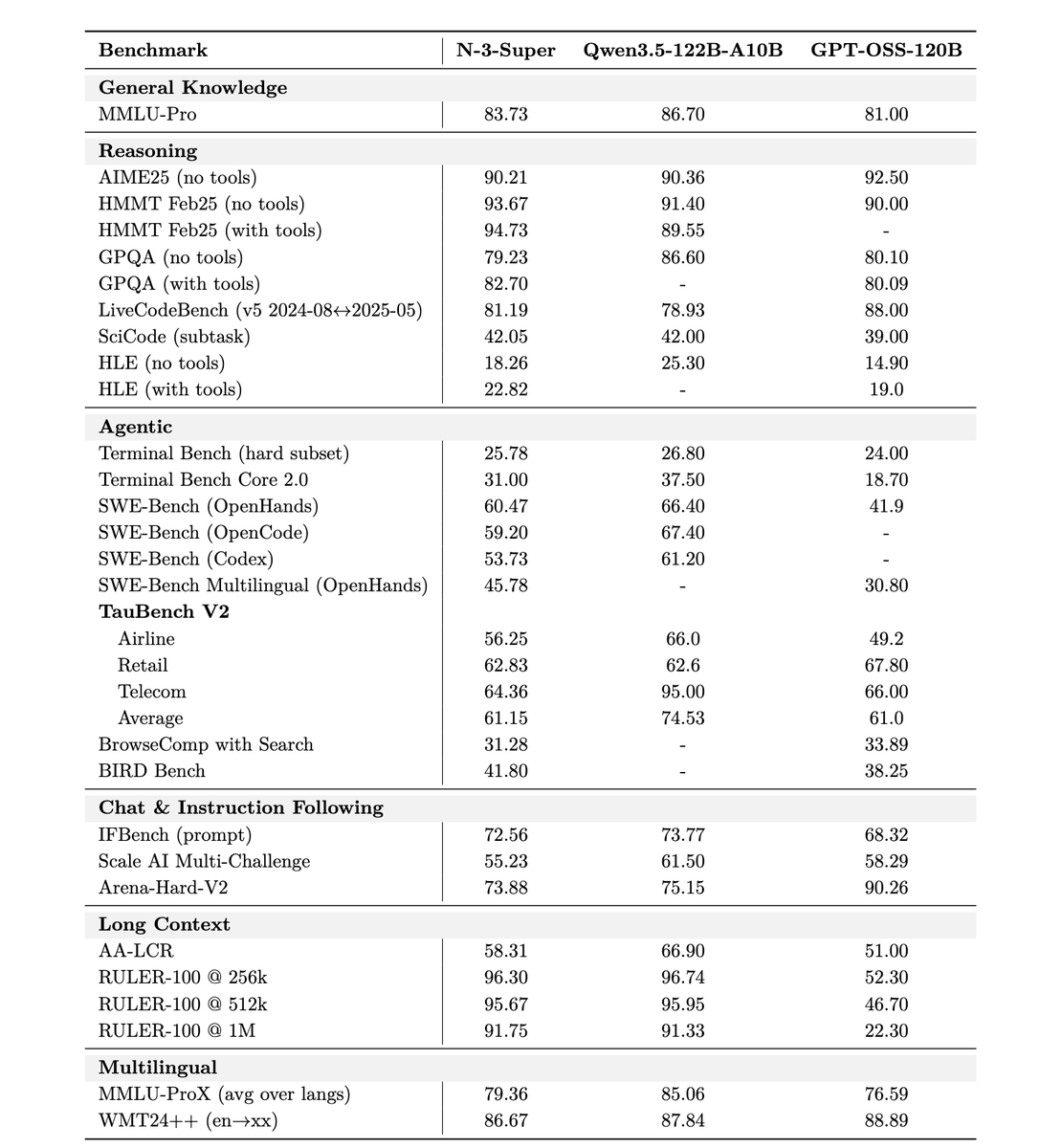
Nvidia released Nemotron 3 Super - a 120B-A12B hybrid Mamba model with LatentMoE and MTP - pre-trained on 25T tokens in NVFP4 - context up to 1M - 2.2X faster inference than GPT-OSS-120B - 7.5X faster inference than Qwen3.5-122B huggingface.co/nvidia/NVIDIA-…
NVIDIA Nemotron 3 Super is here to accelerate the era of agentic AI. Optimized for NVIDIA Blackwell, this 120B open model uses a hybrid Mixture-of-Experts (MoE) architecture that delivers 5x higher throughput and 2x higher accuracy. The model combines advanced reasoning with a 1-million-token context window, enabling autonomous agents to solve complex tasks with speed and precision.



