
Kaahan Radia
18 posts

Kaahan Radia
@kradisme
Building something new @keyframelabs. Ex-Zipline.
Los Angeles, CA Katılım Nisan 2020
60 Takip Edilen37 Takipçiler
Kaahan Radia retweetledi

Datost (@datostapp) is an AI data analyst in Slack.
It keeps a semantic layer of your business definitions, crm, docs, and codebase so it knows what questions mean. 75.2% on the hardest public text-to-SQL benchmark, where Opus 4.6 scores 33%.
Congrats on the launch, @maceock & @jasonhywang!
ycombinator.com/launches/Pxg-d…
English

on the page: "as low as 0.06 cents a minute" - rather than 50 cents a minute like @pika_labs
and they are GOOD avatars, also unlike @pika_labs
Kaahan Radia@kradisme
@ycombinator @KeyframeLabs @parthnradia Try it live at keyframelabs.com!
English
Kaahan Radia retweetledi

We built a demo with Keyframe Labs avatars on the LiveKit Agents Framework.
The avatar doesn't just lip-sync. It picks up on the emotional context of the conversation, and you can see it in its face when the mood changes.
It can also hand off the conversation to a different agent without reconnecting. The new agent fires RPCs to update the UI in real time.
LiveKit x Keyframe plugin and sample repo in the thread.
English
English

@ycombinator @KeyframeLabs @parthnradia @kradisme The AI now looks like a human on video calls.
The human on the other end does not know.
The human on the other end may also be AI.
Neither has been informed.
This is called communication. 📡
English
Kaahan Radia retweetledi
.@KeyframeLabs turns AI into lifelike video calls.
Developers and enterprises can add photoreal, conversational humans to AI agents and applications in minutes.
Congrats on the launch, @parthnradia & @kradisme!
ycombinator.com/launches/Pwg-k…
English
English
Kaahan Radia retweetledi
Minicor (@minicor_) builds self-healing desktop automations for AI companies whose customers run on legacy desktop software with no APIs.
Congrats on the launch, @faizchishtie and @sahee_d!
ycombinator.com/launches/Pkq-m…
English
@arnie_hacker IMO initial experiments on a small dataset, image it, way easier to debug and iterate.
For larger datasets, kinda depends on your video characteristics; getting sampling diversity might require decoding more frames than you think. Preproc + streaming webdataset is our go to.
English

Anyone experienced with training video diffusion models?
Noob question: Do you pre-process mp4 into individual frames and store before training? Doesn't this blow-up storage requirements?
Or do you dynamically convert mp4 into frames during training (how is this parallelized?)
English

Neat idea: jointly diffuse pixels and DINO features with separate noise levels. Then optimise the trajectory through 2D noise level space.
Could do this with DINO + traditional VAE latents as well to get a souped-up version of ReDi (representationdiffusion.github.io @ThKouz et al.)!

Alan Baade@BaadeAlan
What's the right space to diffuse in: Raw Data or Latents? Why not both! In Latent Forcing, we order a joint diffusion trajectory to reveal Latents before Pixels, leading to improved convergence while being lossless at encoding and end-to-end at inference. w/ @drfeifei+... 1/n
Islington, London 🇬🇧 English
the only thing I’ve learned from this whole ai coding thing is that some people are really, really bad at reviewing PRs
English

any optimizer better than adam is 100% a waste of time and if you disagree you're literally just addicted
critter@BecomingCritter
any audiophile equipment better than airpods is 100% a waste of time and if you disagree you're literally just addicted
English
Kaahan Radia retweetledi

Introducing the world's most expressive, conversational AI humans. Runs in real-time at just $0.06 per minute.
Watch Cosmo move fluidly through emotions in an unedited conversation with our CTO.
English
@matiii Does an incredible job driving @KeyframeLabs's emotional avatars. Nice job.
English

Passing the Turing test for voice agents.
We just shipped a major ElevenAgents update:
- Lower-latency, smoother turn-taking with new conversational model
- Expressive Mode for contextual emotional delivery
- Available in 70+ languages
English
@gabriberton Did a little bit of this at Zipline, harder than you think to stop even a medium capacity ResNets from zero-ing out the gradient reversal layer's impact. It would bifurcate it's own feature representations!
English

A little more info on Domain Adaptation: the task is that you would have a labelled train set of one "source" domain (e.g. daytime images) and an unlabelled set from the test/target domain (e.g. night images). [1/N]
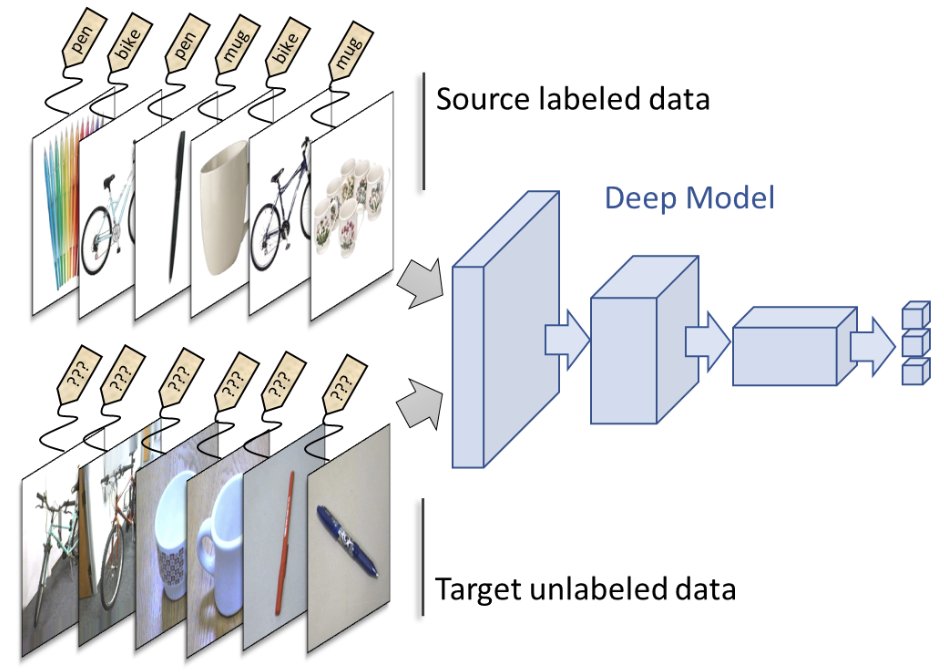
Gabriele Berton@gabriberton
Writing this gave me flashbacks of when CLIP came out. Part of my lab was working on Domain Adaptation, i.e. adapting models to unseen domains. CLIP killed that field CLIP has seen everything, suddenly there was this model with no unseen domain. [1/2]
English
@KBlueleaf Smells like FSQ shenanigans, maybe a residual variant? Cool stuff.
English

30k step from scratch, no GAN training
F16 VQ-VAE with effective 2^64 codebook size, 512 emb dim, trainable param for VQ is 66K only

English
@unilightwf Feels like there’s an obvious extension for TTS — reminds me, in spirit, of the similarity scoring Tortoise did.
English

While everyone is amazed by SAM audio, the hidden gem to me is the SAM Audio Judge!
SAM Audio judge assesses how well a separated audio matches a given text description in terms of (1) overall quality (2) recall (3) precision (4) faithfulness.
huggingface.co/facebook/sam-a…
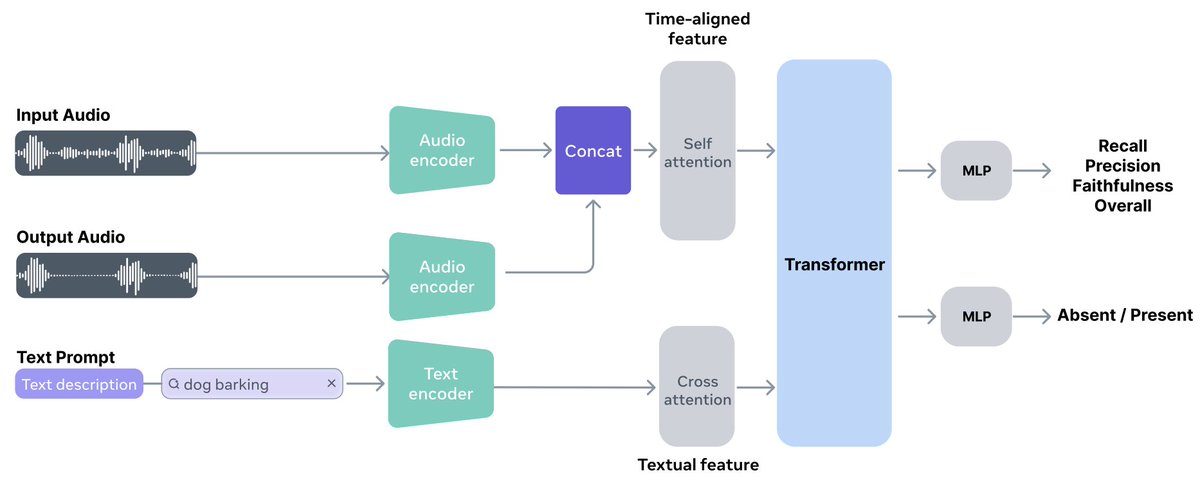
English
Kaahan Radia retweetledi
