Announcing @kritdhi
It's India's next Frontier AI Lab in Making.
We will work on two main things:-
#1 Building the forefront of the current AI system.
#2 Searching for the next big leap of Intelligence.
We look forward to raising a significant amount of support for it.
Thank you.
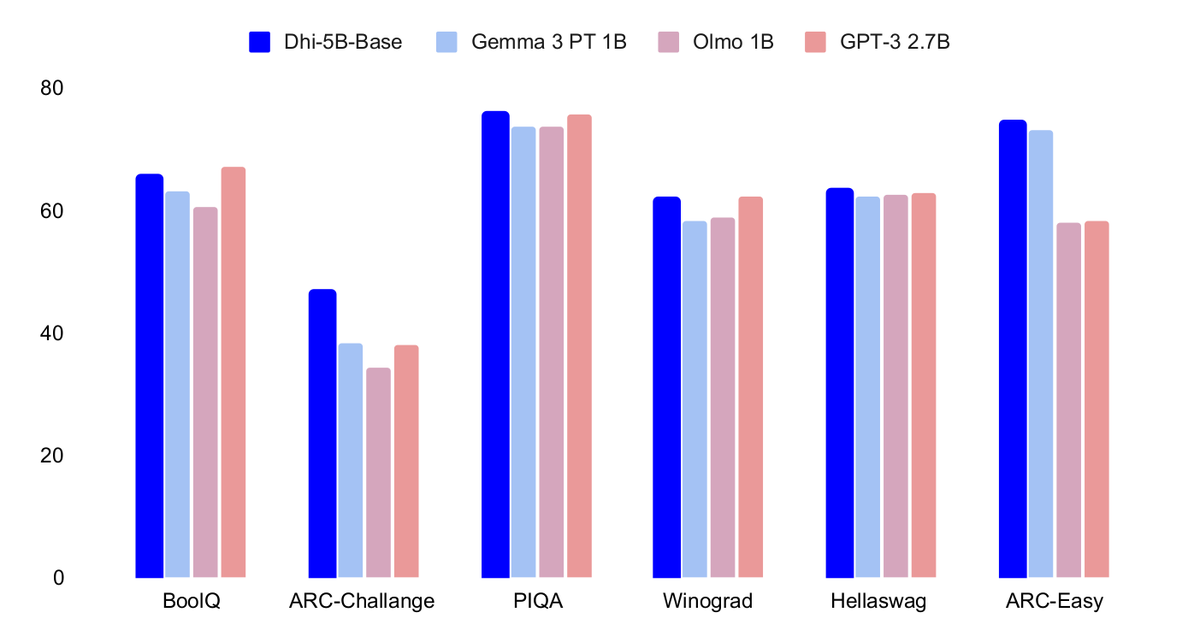
Details about the Dhi-5B-Base 🪻
The base varient is of 4 billion parameters. It is trained on 40 billion natural language tokens from FineWeb-Edu dataset.
We use the new Muon optimizer for optimising the Matrix Layers, and rest are optimized by AdamW.
The model has 32 layers, with 3072 width, SwiGLU MLPs, the full MHA attention with FlashAttention-3, 4096 context length, 64k vocab and 2 million batch size during training.
Below are some evaluations of the model, the compared models are about 10x more expensive than ours. We are at the training efficiency frontier!
Presenting Dhi-5B 🪻✨
A Multimodal Language Model compute optimally pre-trained trained for scratch in India.
It's a 5 billion parameter model, with the base model being of 4 billion params, trained on over 40 billion tokens. We train it on a very constrained budget, i.e. only with ₹ 1.1 lakhs (or $1200).
We incorporate latest architecture design and training methodologies in this. And we also use a custom built codebase for training these models.
We train the Dhi-5B in 5 stages:-
📚 Pre-Training: The most compute heavy phase, where the core is built. (Gives the Base varient.)
📜Context-Length-Extension: The model learns to handle 16k context from the 4k learned during PT.
📖Mid-Training: Annealing on very high quality datasets.
💬Supervised-Fine-Tuning: Model learns to handle conversations. (Gives the Instruct model.)
👀Vision-Extension: The model learns to see. (Results in The Dhi-5B.)
We will be launching it in 3 steps:-
1. Dhi-5B-Base
2. Dhi-5B-Instruct
3. Dhi-5B
The Base model we are dropping now, and the Instruct and the full Dhi-5B will be available in the coming days.