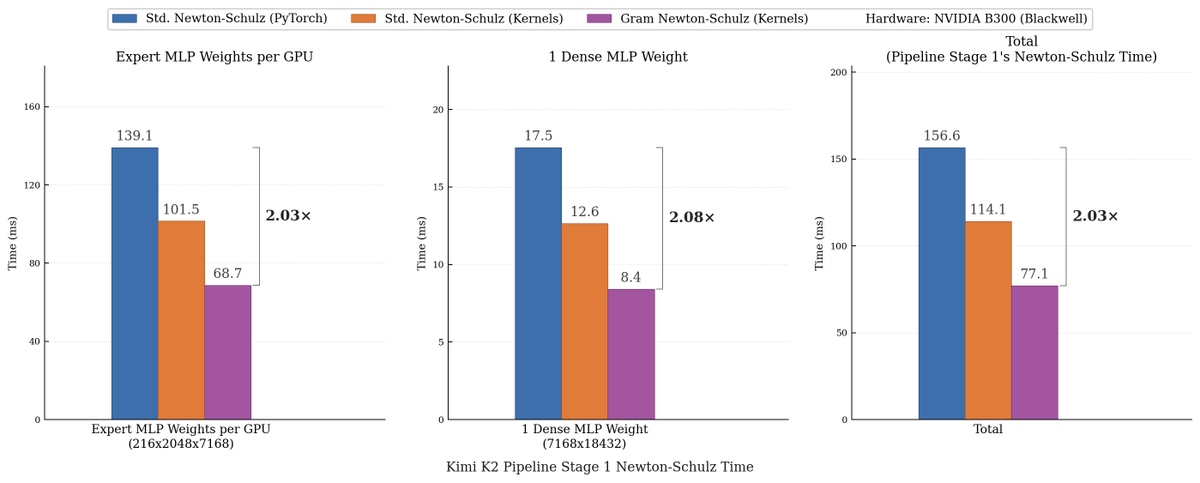
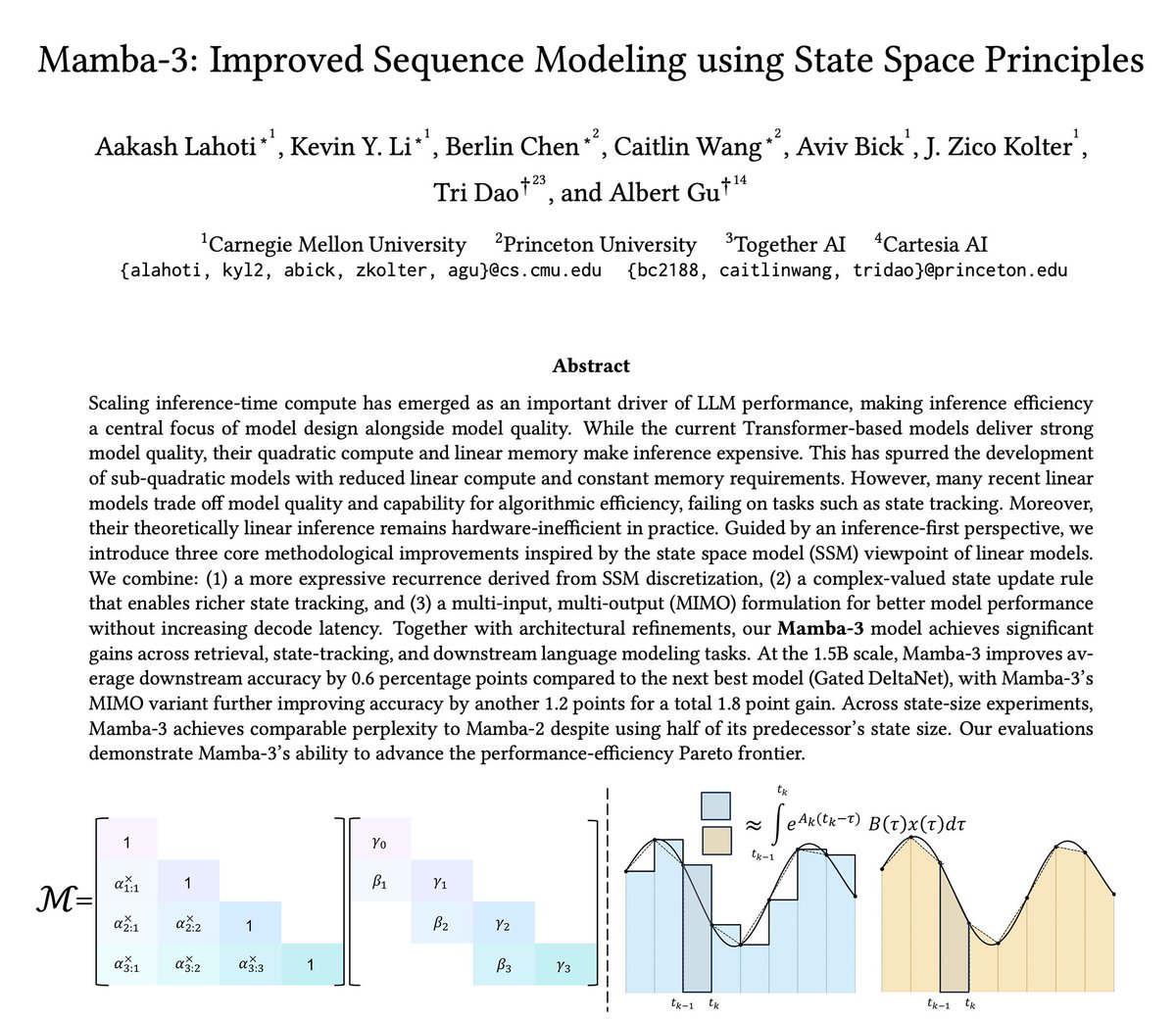
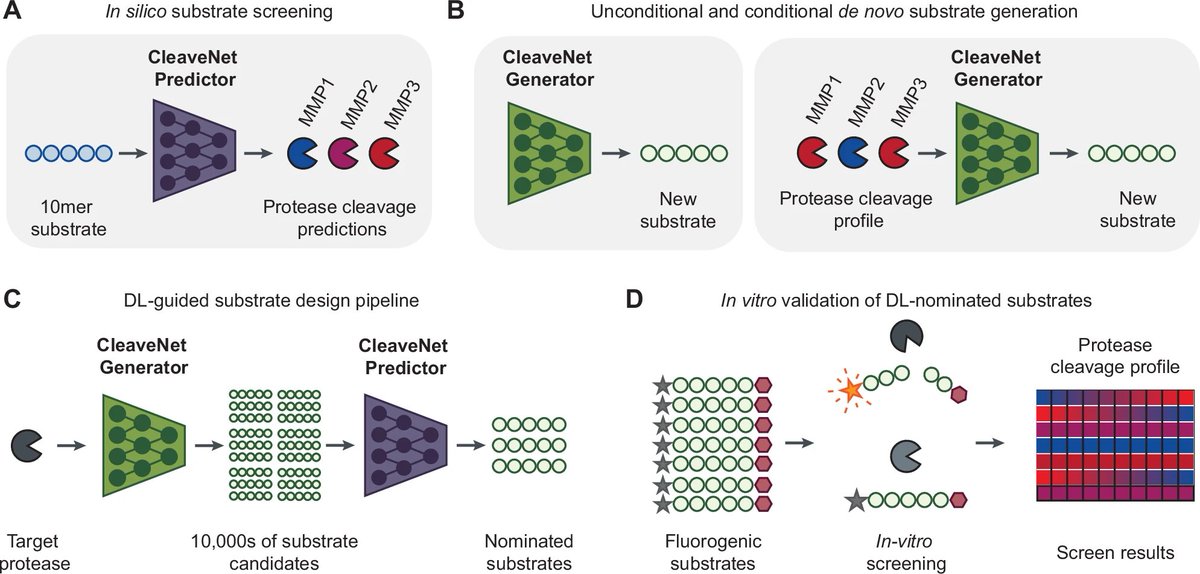
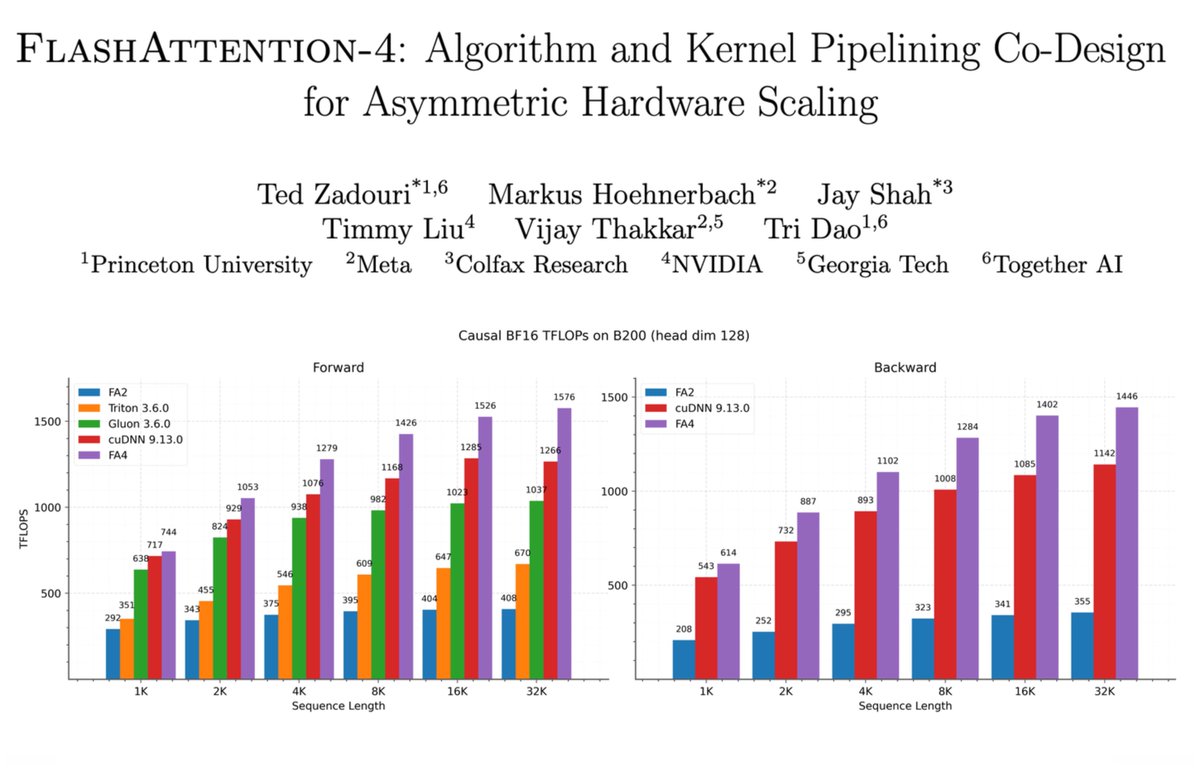
Sabitlenmiş Tweet

🧬 Meet Lyra, a new paradigm for accessible, powerful modeling of biological sequences. Lyra is a lightweight SSM achieving SOTA performance across DNA, RNA, and protein tasks—yet up to 120,000x smaller than foundation models (ESM, Evo). Bonus: you can train it on your Mac.
read our paper here: arxiv.org/abs/2503.16351

English