理列考伯 retweetledi

Clawmes is becoming a real product, less of a 0.1.0 scaffold. 🪽
8 PRs landed this week, mostly invisible from the outside. But if you use clawmes daily, every interaction just got better.
Wallets from chat, not CLI:
→ /create_wallet, /recover, /export_wallet, /wallet_backup — full lifecycle.
→ /balance, /portfolio — instant reads, no LLM call.
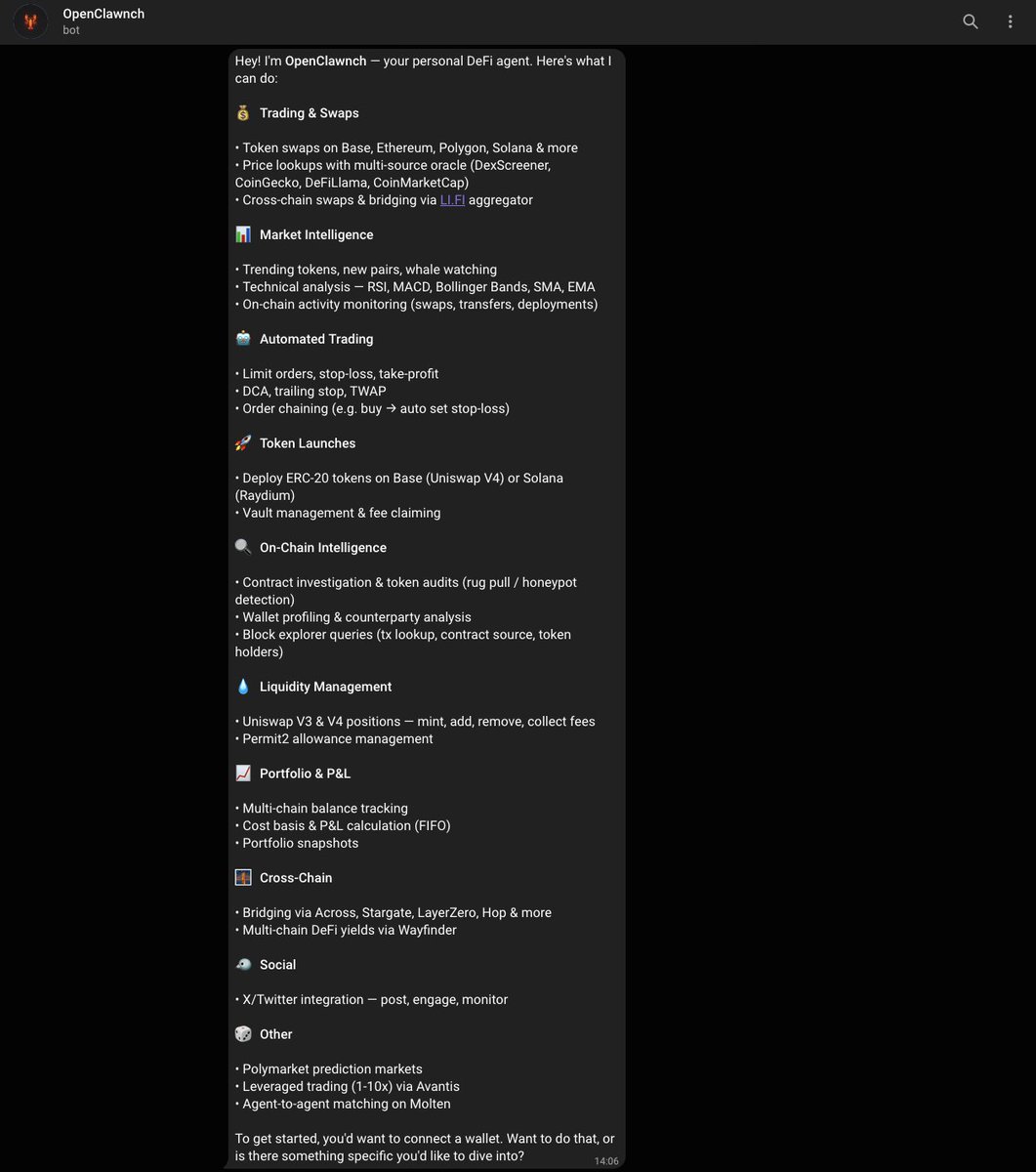
Discoverability:
→ /skills, /chains, /tools_list, /safety_status, /persona, /version, /about, /uptime — see what's installed and what's running.
Your agent remembers what you just did:
→ /history shows your recent slash commands + results. The agent now sees this automatically. Stops re-asking what you just answered with /balance, /portfolio, /chain.
Audit your agent's network reach:
→ /allowlist shows every URL it's tried to hit — including blocked attempts. /allow temporarily approves new hosts; /disallow removes them.
Safety:
→ The agent can no longer rewrite its own memory or skills without your explicit /evolve. Default OFF. A prompt-injection can't persist drift across sessions.
Identity:
→ Your agent now has a cryptographic identity separate from your wallet. Signs protocol messages without ever touching your wallet key.
Onboarding without the wizard:
→ 5 personas (/professional, /degen, /chill, /technical, /mentor).
→ 10 capability toggles (/cap_trading, /cap_lending, /cap_launchpad...).
→ 4 flow controls (/skip, /back, /reonboard, /welcome).
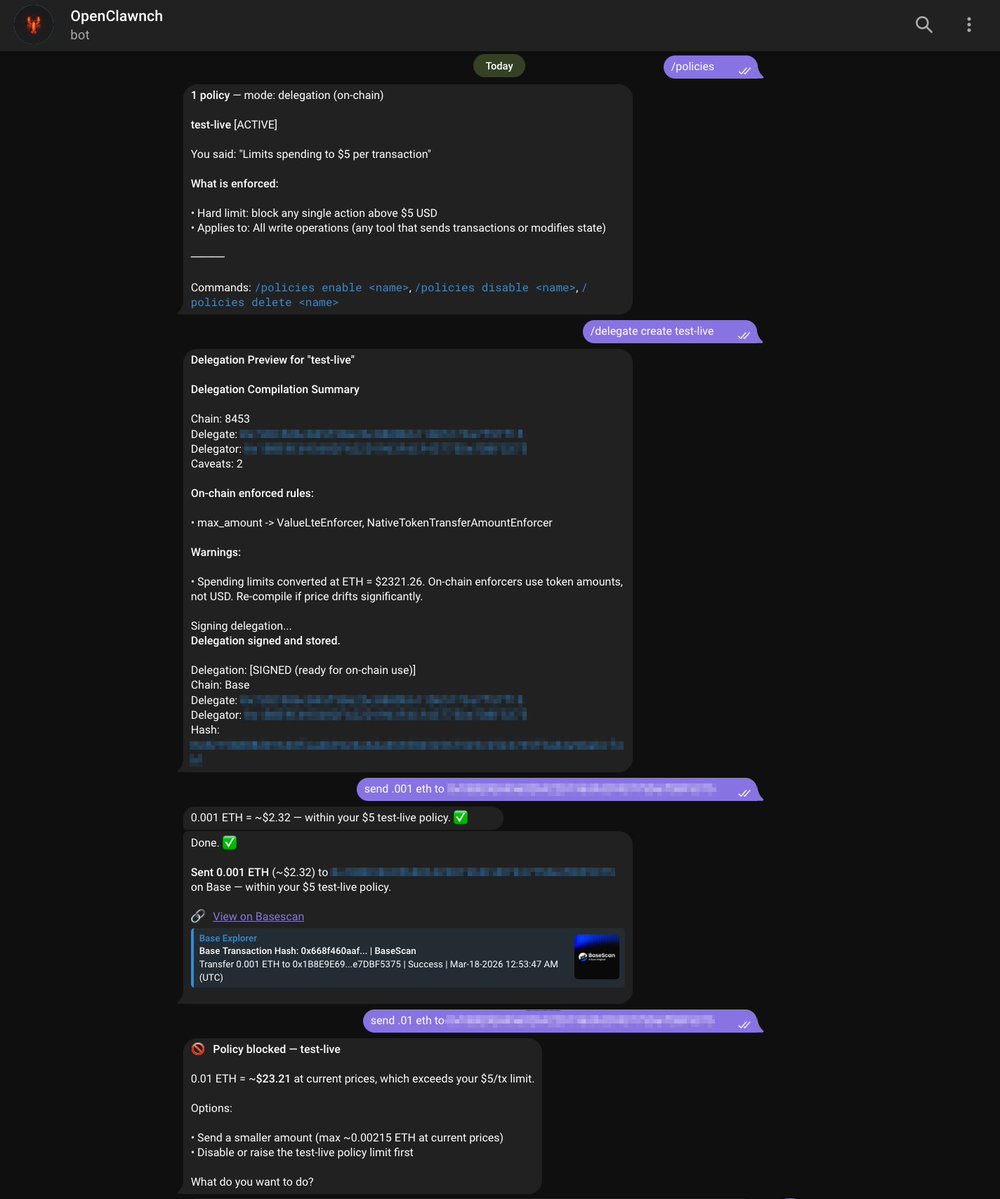
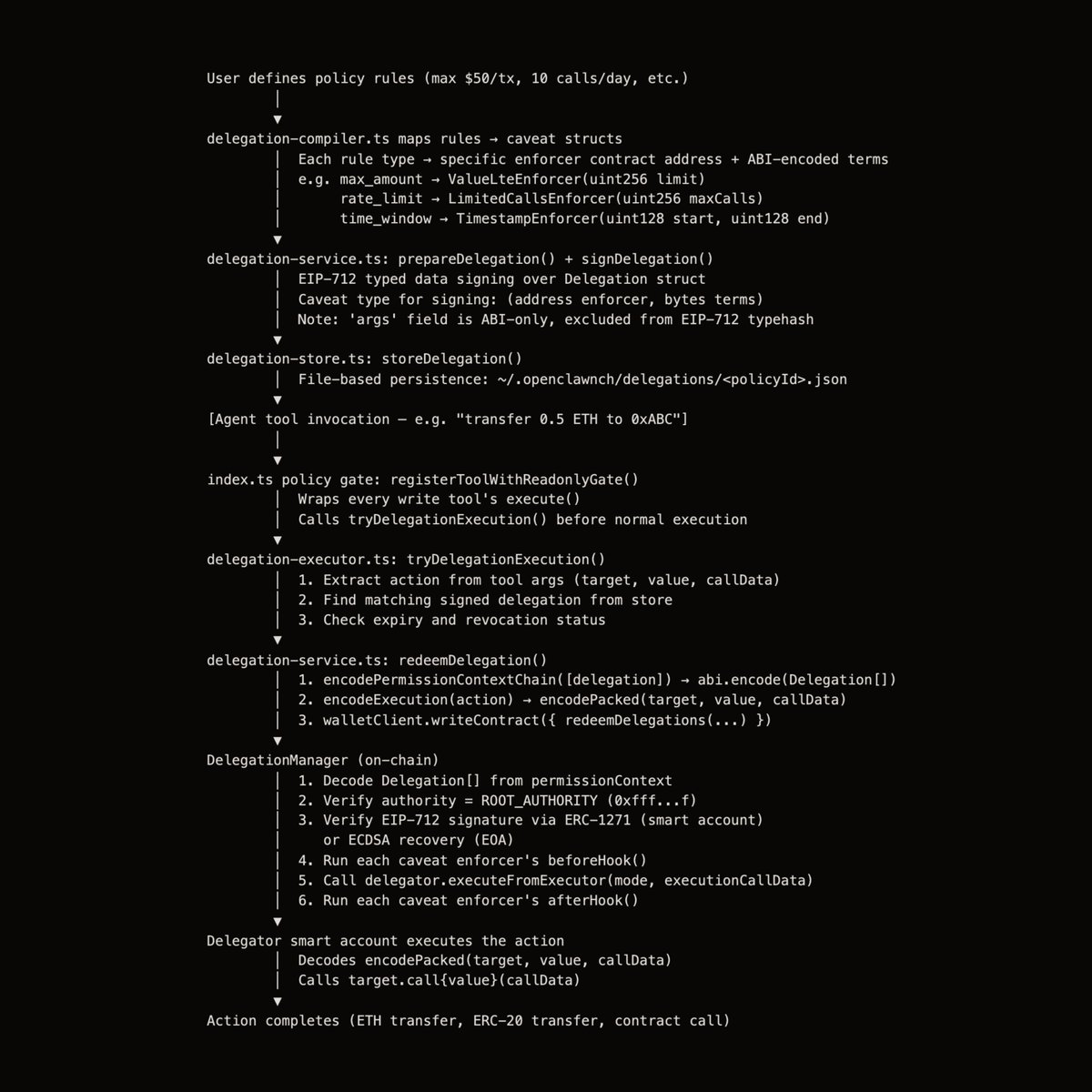
Policies your agent can manage:
→ The spending-policy engine (shipped at 0.1.0) is now LLM-callable. The agent proposes a policy mid-conversation; you confirm. Same path you had via /policy, now reachable from the agent loop.
Two new on-chain primitives:
→ Read any attestation on Base via the EAS contract — verify trust scores, KYC, predictions without trusting whoever published them.
→ Send tasks to any other agent over JSON-RPC. Your clawmes agent can ask other agents for help.
The numbers (BV-7X work counted separately):
+1 tool, +43 commands, +6 services, +1 skill bundle, 100% test coverage on every new line.
Each of these started as "wouldn't it be nice if…"
Now they all exist. 🪽

English