Sabitlenmiş Tweet

DSRs, @DSPyOSS for Rust is here🚀
Happy to finally announce the stable release of DSRs. Over the past few months, I’ve been building DSRs with incredible support and contributions from folks Maguire Papay, @tech_optimist, and @joshmo_dev.
A big shout out to @lateinteraction and @ChenMoneyQ who were the first people to hear my frequent rants on this!! Couldn't have done this without all of them.
DSRs originally started as a passion project to explore true compilation and as it progressed I saw it becoming more. I can’t wait to see what the community builds with it.
DSRs is a 3 phase project:
1. API Stabilization. We are nearly done with this and it was mostly implementing the API design. We kept the DSPy style in mind and tried to keep it close to it so it's easier to onboard and while at it we tried to improve it and make it a bit more idiomatic and intuitive!
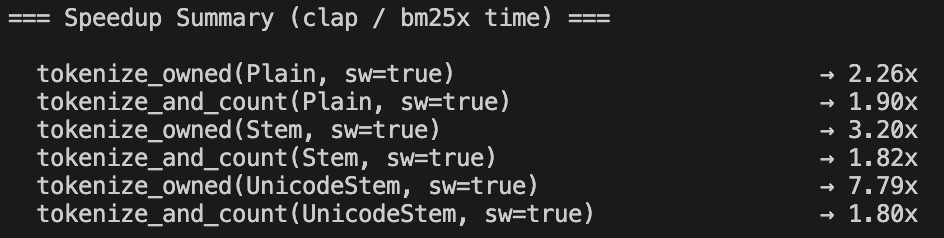
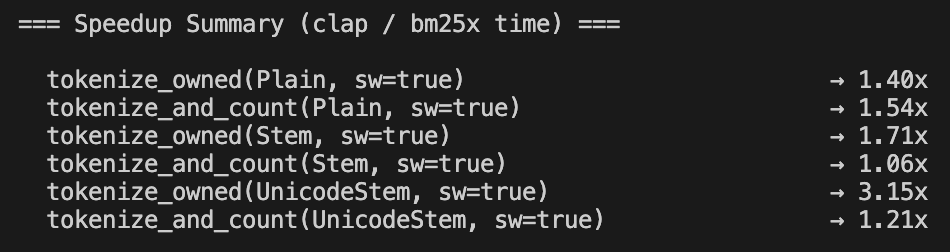
2. Performance Optimisation with benchmarking vs DSPy. We want to benchmark LLMs performance vs DSPy, with API design finalized we want to improve performance in every front. We'll improve the latency and improve the templates and optimizers in DSRs.
3. True Module Compilation. Why should you optimize signature when you can optimize and fuse much more? This is the idea of the final phase of DSRs. A true LLM workflow compiler. More on this after Phase 2.
Really grateful for @PrimeIntellect offering compute to drive Phase 2 and 3 experimentation for this! Big shoutout to them and @johannes_hage for this!!!
But what is DSRs? What does it offer? Let's see.

English