FP32 Monastic
499 posts

FP32 Monastic
@kv_cached
Shipping LLM systems: RAG, agents, serving, eval. Attention seeker (self-attention only). No vibes, just logits.
Riyadh, Kingdom of Saudi Arabi Katılım Şubat 2022
411 Takip Edilen1.2K Takipçiler
you are
a developer trying to run GPT-3 locally
your GPU catches fire
your AWS bill looks like a phone number
decide to learn the dark arts of optimization
18 months later i can make a 70B model run on a gaming laptop
here's the forbidden speedrun guide
the problem:
LLMs are fat and slow
175B parameters = 700GB in FP32
one forward pass = your GPU crying
inference speed measured in geological time
but the nerds fixed it
quantization = the ultimate life hack
take your fancy 32-bit floats
crush them to 8-bit ints
model gets 75% smaller
still works fine
it's like JPEG for neural networks
"lossy compression but nobody notices"
4-bit quantization:
yes, FOUR bits
0-15, that's all you get
somehow still generates shakespeare
GGUF, AWQ, GPTQ formats
pick your poison
they all work, nobody knows why
KV-cache quantization:
the cache that stores your conversation
normally bloats like your node_modules
quantize it too
suddenly you can chat for hours
memory usage: "what memory usage?"
flash attention = GPU go brrrr
normal attention: O(n²) memory
flash attention: "what if we just... didn't?"
compute in tiny blocks
use SRAM like a speed demon
4x faster, uses 10x less memory
dao-aielab/flash-attention changed the game
sparse attention patterns:
not every token needs to see every token
local: "i only talk to my neighbors"
strided: "i check in every 8 tokens"
learned: "the model decides who's worth talking to"
attention budget: managed
paged attention:
virtual memory but for transformers
breaks KV-cache into pages
no more memory fragmentation
vLLM uses this
suddenly you can serve 100 users on one GPU
"MMU for AI" energy
speculative decoding = parallel universe speedrun:
small model: "i think it says 'the cat sat'"
big model: "let me verify... yep, 2/3 correct"
accept the good, regenerate the bad
2-3x speedup
free performance, no quality loss
LoRA = fine-tuning for broke people:
don't retrain 70B params
add tiny 1M param adapters
they modify the big model's behavior
switch them like cartridges
one base model, infinite personalities
PEFT library makes it trivial
pruning = marie kondo for weights:
structured: delete entire layers
unstructured: delete random connections
magnitude pruning: "if weight < 0.01, yeet"
90% sparsity still works
your model on a diet
knowledge distillation:
big model teaches small model
teacher: "here's my probability distribution"
student: "i'll mimic that"
10x smaller, 95% as good
how edge devices run "GPT"
dynamic batching:
GPUs hate single requests
batch them like a subway at rush hour
continuous batching: add/remove on the fly
orca/vllm pioneered this
throughput goes 10x
tensor parallelism:
split matrices across GPUs
GPU 1: "i'll do columns 0-1024"
GPU 2: "i'll take 1024-2048"
requires NVLink or you die waiting
how you run 175B models at all
pipeline parallelism:
assembly line for layers
GPU 1 does layers 1-10
GPU 2 does 11-20
microbatching keeps everyone busy
deepspeed makes this "easy"
mixed precision = have your cake:
compute in FP16
accumulate in FP32
store in INT8
tensor cores go brrr
2x speedup for free
early exit strategies:
easy tokens exit early
"the" doesn't need 80 layers
complex tokens get full computation
adaptive compute budgets
30-50% faster on average
model serving stack that actually works:
vLLM for throughput
TensorRT-LLM for latency
llama.cpp for edge
everyone else is marketing
pick one, tune it, ship it
the multiplication effect:
quantization: 4x smaller
flash attention: 4x faster
batching: 10x throughput
sparse attention: 2x faster
speculative decoding: 2x faster
compound them all: 320x better
secret sauce combinations:
INT4 quantization + flash attention + paged attention
= 70B model on consumer GPU
LoRA + pruning + distillation
= custom 7B that beats GPT-3.5
all the techniques stack
forbidden truth:
OpenAI uses all of these
Anthropic too
the "magic" is just good engineering
frontier models = same architecture + better optimization
scale is a compiler flag
what nobody tells you:
inference optimization > training optimization
most "breakthroughs" are engineering
the papers are public
the code is on github
you can build this
tools of the trade:
bitsandbytes for quantization
flash-attention (obviously)
vLLM for serving
PEFT for LoRA
tensorRT for nvidia supremacy
llama.cpp for running on your toaster
final boss wisdom:
you don't need a PhD
you don't need H100s
you need obsession and arxiv
start with llama.cpp
work your way up
in 6 months you'll be explaining speculative decoding at parties
the endgame:
gpt-4 class models on your laptop
real-time inference on phones
open source catching up monthly
optimization democratizing AI
the moat is evaporating
they said LLMs need datacenters
they lied
with these techniques
you run them on edge
build your own
ship to users
no API keys
no rate limits
just pure, optimized inference
now you know
the sacred techniques
the forbidden optimizations
stop asking for API access
start quantizing
welcome to the resistance
English
FP32 Monastic@kv_cached
smallest Arabic model ever Built an Arabic RAG agent on @karpathy's nanochat Trained on: • ArabicText-Large (244M words) • Hala-4.6M Arabic instructions • MorphBPE tokenizer (76.8K vocab) Features: ✓ RTL UI with citations ✓ Offline RAG + search ✓ Consensus decoding ✓ Runs on 4GB GPU $0 cost. Fully offline. github.com/h9-tec/arabic_…
English

nanochat now has a primordial identity and can talk a bit about itself and its capabilities (e.g. it knows it's nanochat d32 that cost $800, that it was built by me, that it can't speak languages other than English too well and why, etc.).
This kind of customization is all done through synthetic data generation and I uploaded a new example script to demonstrate. It's a bit subtle but by default LLMs have no inherent personality or any understanding of their own capabilities because they are not animal-like entities. They don't know what they are or what they can or can't do or know or don't know. All of it has to be explicit bolted on. This is done by asking a bigger LLM cousin to generate synthetic conversations (you tell it what they should look like simply in words), and then mixing them into midtraining and/or SFT stage. The most important challenge is ensuring enough entropy/diversity in your generated data. If you don't do it well, LLMs will generate 1000 conversations that are all ay too similar, even with high temperature. My script shows a crappy example of how to add diversity - e.g. by creating lists of starting messages or topics, sampling from them explicitly, adding them as fewshot examples into prompts for "inspiration", etc.
I wanted to have some fun with it so nanochat now refers to me as King Andrej Karpathy (lol) just to illustrate that this is a giant blank canvas - you can infuse completely arbitrarily identity, knowledge or style into your LLM in this manner. I hope it's helpful and sparks fun ideas!
Andrej Karpathy@karpathy
@r_chirra I fixed it :) deployed live now. This was done by doing a round of synthetic data generation to collect a 1000 multi-turn conversations (given a bunch of information including the readme of the nanochat project), and then mixing that into midtraining and SFT. fun!
English
@TheAhmadOsman Killer guide. One speed trick worth mentioning: speculative decoding with a draft model can get you 2-3x faster inference on consumer GPUs - llama.cpp and vLLM both support it now. Huge for interactive use cases.
English

- local llms 101
- running a model = inference (using model weights)
- inference = predicting the next token based on your input plus all tokens generated so far
- together, these make up the "sequence"
- tokens ≠ words
- they're the chunks representing the text a model sees
- they are represented by integers (token IDs) in the model
- "tokenizer" = the algorithm that splits text into tokens
- common types: BPE (byte pair encoding), SentencePiece
- token examples:
- "hello" = 1 token or maybe 2 or 3 tokens
- "internationalization" = 5–8 tokens
- context window = max tokens model can "see" at once (2K, 8K, 32K+)
- longer context = more VRAM for KV cache, slower decode
- during inference, the model predicts next token
- by running lots of math on its "weights"
- model weights = billions of learned parameters (the knowledge and patterns from training)
- model parameters: usually billions of numbers (called weights) that the model learns during training
- these weights encode all the model's "knowledge" (patterns, language, facts, reasoning)
- think of them as the knobs and dials inside the model, specifically computed to recognize what could come next
- when you run inference, the model uses these parameters to compute its predictions, one token at a time
- every prediction is just: model weights + current sequence → probabilities for what comes next
- pick a token, append it, repeat, each new token becomes part of the sequence for the next prediction
- models are more than weight files
- neural network architecture: transformer skeleton (layers, heads, RoPE, MQA/GQA, more below)
- weights: billions of learned numbers (parameters, not "tokens", but calculated from tokens)
- tokenizer: how text gets chunked into tokens (BPE/SentencePiece)
- config: metadata, shapes, special tokens, license, intended use, etc
- sometimes: chat template are required for chat/instruct models, or else you get gibberish
- you give a model a prompt (your text, converted into tokens)
- models differ in parameter size:
- 7B means ~7 billion learned numbers
- common sizes: 7B, 13B, 70B
- bigger = stronger, but eats more VRAM/memory & compute
- the model computes a probability for every possible next token (softmax over vocab)
- picks one: either the highest (greedy) or
- samples from the probability distribution (temperature, top-p, etc)
- then appends that token to the sequence, then repeats the whole process
- this is generation:
- generate; predict, sample, append
- over and over, one token at a time
- rinse and repeat
- each new token depends on everything before it; the model re-reads the sequence every step
- generation is always stepwise: token by token, not all at once
- mathematically: model is a learned function, f_θ(seq) → p(next_token)
- all the "magic" is just repeating "what's likely next?" until you stop
- all conversation "tokens" live in the KV cache, or the "session memory"
- so what's actually inside the model?
- everything above-tokens, weights, config-is just setup for the real engine underneath
- the core of almost every modern llm is a transformer architecture
- this is the skeleton that moves all those numbers around
- it's what turns token sequences and weights into predictions
- designed for sequence data (like language),
- transformers can "look back" at previous tokens and
- decide which ones matter for the next prediction
- transformers work in layers, passing your sequence through the same recipe over and over
- each layer refines the representation, using attention to focus on the important parts of your input and context
- every time you generate a new token, it goes through this stack of layers-every single step
- inside each transformer layer:
- self-attention: figures out which previous tokens are important to the current prediction
- MLPs (multi-layer perceptrons): further process token representations, adding non-linearity and expressiveness
- layer norms and residuals: stabilize learning and prediction, making deep networks possible
- positional encodings (like RoPE): tell the model where each token sits in the sequence
- so "cat" and "catastrophe" aren't confused by position
- by stacking these layers (sometimes dozens or even hundreds)
- transformers build a complex understanding of your prompt, context, and conversation history
- transformer recap:
- decoder-only: model only predicts what comes next, each token looks back at all previous tokens
- self-attention picks what to focus on (MQA/GQA = efficient versions for less memory)
- feed-forward MLP after attention for every token (usually 2 layers, GELU activation)
- everything's wrapped in layer norms + linear layers (QKV projections, MLPs, outputs)
- residuals + norms = stable, trainable, no exploding/vanishing gradients
- RoPE (rotary embeddings): tells the model where each token sits in the sequence
- stack N layers of this → final logits → pick the next token
- scale up: more layers, more heads, wider MLPs = bigger brains
- VRAM: memory, the bottleneck
- VRAM must must fit:
1. weights (main model, whether quantized or not)
2. KV cache (per token, per layer, per head)
- weights:
- FP16: ~2 bytes/param → 7B = ~14GB
- 8-bit: ~1 byte/param → 7B = ~7GB
- 4-bit: ~0.5 byte/param → 7B = ~3.5GB
- add 10–30% for runtime overheads
- KV cache:
- rule of thumb: 0.5MB per token (Llama-like 7B, 32 layers, 4K tokens = ~2GB)
- some runtimes support KV cache quantization (8/4-bit) = big savings
- throughput = memory bandwidth + GPU FLOPs + attention implementation (FlashAttention/SDPA help) + quantization + batch size
- offload to CPU? expect MASSIVE slowdown
- GPU or bust: CPUs run quantized models (slow), but any real context/model needs CUDA/ROCm/Metal
- CPU spill = sadness (check device_map and memory fit)
- quantization: reduce precision for memory wins (sometimes a tiny quality hit)
- FP32/FP16/BF16 = full/floored
- INT8/INT4/NF4 = quantized
- 4-bit (NF4/GPTQ/AWQ) = sweet spot for most consumer GPUs (big memory win, small quality hit for most tasks)
- math-heavy or finicky tasks degrade first (math, logic, coding)
- KV cache quantization: even more memory saved for long contexts (check runtime support)
- formats/runtimes:
- PyTorch + safetensors: flexible, standard, GPU/TPU/CPU
- GGUF (llama.cpp): CPU/GPU/portable, best for quant + edge devices
- ONNX, TensorRT-LLM, MLC: advanced flavors for special hardware/use
- protip: avoid legacy .bin (pickle risk), use safetensors for safety
- everything is a tradeoff
- smaller = fits anywhere, less power
- more context = more latency + VRAM burn
- quantization = speed/memory, but maybe less accurate
- local = more control/knobs, more work
- what happens when you "load a model"?
- download weights, tokenizer, config
- resolve license/trust (don't use trust_remote_code unless you really trust the author)
- load to VRAM/CPU (check memory fit)
- warmup: kernels/caches initialized, first pass is slowest
- inference: forward passes per token, updating KV cache each step
- decoding = how next token is chosen:
- greedy: always top-1 (robotic)
- temperature: softens or sharpens probabilities (higher = more random)
- top-k: pick from top k
- top-p: pick from smallest set with ≥p prob
- typical sampling, repetition penalty, no-repeat n-gram: extra controls
- deterministic = set a seed and no sampling
- tune for your use-case: chat, summarization, code
- serving options?
- vLLM for high throughput, parallel serving
- llama.cpp server (OpenAI-compatible API)
- ExLlama V2/V3 w/ Tabby API (OpenAI-compatible API)
- run as a local script (CLI)
- FastAPI/Flask for local API endpoint
- local ≠ offline; run it, serve it, or build apps on top
- fine-tuning, ultra-brief:
- LoRA / QLoRA = adapter layers (efficient, minimal VRAM)
- still need a dataset and eval plan; adapters can be merged or kept separate
- most users get far with prompting + retrieval (RAG) or few-shot for niche tasks
- common pitfalls
- OOM? out of memory. Model or context too big, quantize or shrink context
- gibberish? used a base model with a chat prompt, or wrong template; check temperature/top_p
- slow? offload to CPU, wrong drivers, no FlashAttention; check CUDA/ROCm/Metal, memory fit
- unsafe? don't use random .bin or trust_remote_code; prefer safetensors, verify source
- why run locally?
- control: all the knobs are yours to tweak:
- sampler, chat templates, decoding, system prompts, quantization, context
- cost: no per-token API billing-just upfront hardware
- privacy: prompts and outputs stay on your machine
- latency: no network roundtrips, instant token streaming
- challenges:
- hardware limits (VRAM/memory = max model/context)
- ecosystem variance (different runtimes, quant schemes, templates)
- ops burden (setup, drivers, updates)
- running local checklist:
- pick a model (prefer chat-tuned, sized for your VRAM)
- pick precision (4-bit saves RAM, FP16 for max quality)
- install runtime (vLLM, llama.cpp, Transformers+PyTorch, etc)
- run it, get tokens/sec, check memory fit
- use correct chat template (apply_chat_template)
- tune decoding (temp/top_p)
- benchmark on your task
- serve as local API (or go wild and fine-tune it)
- glossary:
- token: smallest unit (subword/char)
- context window: max tokens visible to model
- KV cache: session memory, per-layer attention state
- quantization: lower precision for memory/speed
- RoPE: rotary position embeddings (for order)
- GQA/MQA: efficient attention for memory bandwidth
- decoding: method for picking next token
- RAG: retrieval-augmented generation, add real info
- misc:
- common architectures: LLaMA, Falcon, Mistral, GPT-NeoX, etc
- base model: not fine-tuned for chat (LLaMA, Falcon, etc)
- chat-tuned: fine-tuned for dialogue (Alpaca, Vicuna, etc)
- instruct-tuned: fine-tuned for following instructions (LLaMA-2-Chat, Mistral-Instruct, etc)
- chat/instruct models usually need a special prompt template to work well
- chat template: system/user/assistant markup is required; wrong template = junk output
- base models can do few-shot chat prompting, but not as well as chat-tuned ones
- quantized: weights stored in lower precision (8-bit, 4-bit) for memory savings, at some quality loss
- quantization is a tradeoff: memory/speed vs quality
- 4-bit (NF4/GPTQ/AWQ) is the sweet spot for most consumer GPUs (huge memory win, minor quality drop for most tasks)
- math-heavy or finicky tasks degrade first (math, logic, code)
- quantization types: FP16 (full), INT8 (quantized), INT4/NF4 (more quantized), etc.
- some runtimes support quantized KV cache (8/4-bit), big savings for long contexts
- formats/runtimes:
- PyTorch + safetensors: flexible, standard, works on GPU/TPU/CPU
- GGUF (llama.cpp): CPU/GPU, portable, best for quant + edge devices
- ONNX, TensorRT-LLM, MLC: advanced options for special hardware
- avoid legacy .bin (pickle risk), use safetensors for safety
- everything is a tradeoff:
- smaller = fits anywhere, less power
- more context = more latency + VRAM burn
- quantization = faster/leaner, maybe less accurate
- local = full control/knobs, but more work
- final words:
- local LLMs = memory math + correct formatting
- fit weights and KV cache in memory
- use the right chat template and decoding strategy
- know your knobs: quantization, context, decoding, batch, hardware
- master these, and you can run (and reason about) almost any modern model locally
English
smallest Arabic model ever
Built an Arabic RAG agent on @karpathy's nanochat
Trained on:
• ArabicText-Large (244M words)
• Hala-4.6M Arabic instructions
• MorphBPE tokenizer (76.8K vocab)
Features:
✓ RTL UI with citations
✓ Offline RAG + search
✓ Consensus decoding
✓ Runs on 4GB GPU
$0 cost. Fully offline.
github.com/h9-tec/arabic_…
English

This research argues that the field should stop chasing ever-bigger models for logic. For reasoning, smaller can do better.
They built a Tiny Recursive Model, a deliberately small network with two layers and about seven million parameters. Instead of trying to solve a problem in one pass, it guesses, checks itself, and refines the answer through recursion. The design is intentionally simple: no heavy mathematical machinery and no biological analogies—just a compact loop that improves its own output step by step.
Why it matters: the tiny model outperforms much larger language models on hard logic tasks. It reaches state-of-the-art test accuracy on puzzle benchmarks, including around 87.4% on Sudoku-Extreme, and it beats large models on ARC-AGI-2 (about 7.8% versus 4.9% for a top LLM). The core reason is error control. Big language models generate text token by token; one early mistake can derail the entire chain of thought. The recursive model revisits and corrects its work, so errors don’t snowball. The study also finds that cutting depth to two layers improves generalization and reduces overfitting for these constrained logic problems. In short: for analytical, well-scoped reasoning, deep recursion with a tiny network can be more reliable and efficient than scaling up parameter counts.

English
Serving/inference knobs: Persistent batching, CUDA Graph capture, tokenizer prefetch/pinning, pinned host memory pools, page-locked staging, KV-cache placement policy, NCCL env tuning (P2P level/IB), speculative decode calibration windows, chunked prefill, multi-stream decode, graph-captured pipelines
GPU software stack: NCCL version pinning, CUDA/cuBLAS/cuDNN matrices, CUDA Graphs, MPS for concurrency, MIG (if datacenter SKUs), nvidia-container-toolkit, DCGM exporter, pinned driver + toolkit images, ROCm matrix if AMD, TensorRT-LLM engine build cache policy
Networking: 10/25/40GbE selection, MTU 9000, LACP, VLAN segregation (mgmt/data), IRQ/RSS queue pinning, iperf3 baselines, ROCEv2 + PFC/DCB only if you own the fabric, Mellanox firmware pinning, static IPMI, out-of-band path redundancy
Observability: Prometheus + Grafana, node_exporter + DCGM exporter, nvidia-smi dmon logging, IPMI sensors, disk SMART, power meters, alerting thresholds (temp, AER, XID, link retrains), log shipping, tracepoints/bpftrace for IRQ stalls
English
raw alpha drop
phb, soak test, slimsas, mcio, host adapters, cable length, retimers, signal integrity, airflow plan, front-to-back cooling, repadding, vram thermals, rackmount, room hvac, power budget, 1200w, psu sizing, transients, add2psu, 240v circuits, pdus, power limiting, gpu, budget tier, rtx 3090, ampere, lane budget, x16 gen4, cpu-direct lanes, pcie bifurcation, numa, topology matrix checks, vllm, exllamav3, tp=2, tensor parallelism, batch inference, speculative decoding, paged attention, quantization, w4a16, low-bit inference, tokens per second, throughput, prefill vs decode, tail latency, validation, diagnostics, pcie instability, aer errors, nvrm xid events, stress tests, ring all-reduce, p2p over pcie, nvlink pairs, procurement, used gpu vetting, nvme boot, 10gbe networking, firmware, bios settings, above 4g decoding, persistence mode, cuda, drivers, build checklist, safety, grounding, roi, buy a gpu, wire it right, hum of freedom, small lab, 2x gpu, indie tier, rtx 4090, ada, workstation gpus, 24gb vram, consumer platforms, am5, threadripper pro, wrx80, epyc 7002, milan, server motherboards, many x16 slots, x8 gen5, avoid chipset, chipset lanes, single-socket, sff-8654, device adapters, bend radius, no flat risers, redrivers, high-airflow fans, fan hubs, thermal paste, open-frame, noise discipline, spares ready, 600w, 2000w, 3000w, 4800w, multiple psus, 30a circuit, pdu discipline, exllamav2, tensorrt-llm, sglang, llama.cpp, tp=4, tp=8, batch inference, kv cache, bf16, fp16, gguf, awq, int8, tokens/sec, diagnostics, topology matrix, uniform topology, uniform ring all-reduce, spares, serviceability, scratch disk, rocm, driver matrix, pin your versions, bench, bios, wire, monitor the temp, never apologize for the hum of freedom, small lab, 4x gpu, research tier, blackwell, 48gb vram, gddr6x, lga, wrx90, epyc 9004, genoa, single-socket sanity, cabling, cable bend radius, stress/soak tests, uniform x8, power-limiting, quantization isn’t just for nerds, cooling plan, validation, tokens in flight, batch scheduler, gguf is not a curse word, apartment mode, buy a gpu, wire it right, monitor the temp, never apologize for the hum of freedom, startup lab, 8x gpu builds.
English
The Journey from Human Attention to AI Revolution: How We Taught Machines to Focus
heshamharoon.substack.com/p/the-journey-…
English
Mindblowing paper
x.com/jm_alexia/stat…
Alexia Jolicoeur-Martineau@jm_alexia
New paper 📜: Tiny Recursion Model (TRM) is a recursive reasoning approach with a tiny 7M parameters neural network that obtains 45% on ARC-AGI-1 and 8% on ARC-AGI-2, beating most LLMs. Blog: alexiajm.github.io/2025/09/29/tin… Code: github.com/SamsungSAILMon… Paper: arxiv.org/abs/2510.04871
English
you’re
done treating attention like stage magic
here to make the mechanism legible
no mystique, no gatekeeping
map: attention variants + inference path, distilled
premises
text → tokens → vectors
attention = soft selection over history
everything else is plumbing
time encodings
absolute index: short-range bias; brittle past train span
RoPE: rotary phases; extendable via NTK/YaRN scaling; check order sensitivity
ALiBi: linear distance bias; cheap; stable for longer spans
head topology
MHA: feature bands in parallel
MQA/GQA: many Q heads, few K/V heads → smaller KV, faster decode, mild accuracy tax
exact kernels
flash-style attention: tile Q/K/V; keep stats in SRAM; exact softmax; IO-aware
big prefill gains; steady decode wins with small tiles
structured sparsity
sliding/dilated windows: O(n·w); strong locality; weak global recall
block-sparse (local + random + global): pattern choice matters; tune or degrade
linearized/low-rank (Performer/Linformer/Nyström): kernel/landmark shortcuts; audit reasoning drift
context extension
RoPE scaling: stretch frequencies; watch positional distortion
sink/primer tokens: early-step stabilizers
memory tokens/layers: learned scratchpad; capacity emergent, not guaranteed
KV cache engineering
shape ≈ [B, L, H, d_k]; bytes ≈ 2·B·L·H·d_k·dtype_size
paged KV: page the cache; kill fragmentation; enable continuous batching
eviction: sliding window baseline → trims by recency/entropy/salience
two regimes
prefill: FLOPs + bandwidth bound → flash kernels, fused MLPs, larger batch
decode: KV-read bound → MQA/GQA, KV locality, KV quantization, careful scheduling
serving levers
batching: continuous intake; chunk prefill to keep SMs utilized
quantization: W8/W4; KV 8/4-bit where stable; re-eval long-context tasks
scheduler: prioritize short jobs; cap context; allow preemption; track P95/P99
parallelism: request-level; speculative paths; shard KV if needed
speculative and guided decode
draft-then-verify: small proposer + large confirmer → fewer expensive steps/token
logit guidance: light penalties/rewards for safety/format; monitor diversity entropy
metrics that decide
TTFT, TPOT, tokens/s/GPU
P95/P99 latency
VRAM per token
throughput at fixed QoS
perplexity/task deltas per change
anti-use rules
no windowed attention for cross-doc reasoning without retrieval
no blind RoPE stretch beyond train regime; test order flips
no MQA/GQA on fragile domains without fresh eval
no sparse patterns in prod without failure audits
shop-floor truths
bandwidth rules; kernels are IO plays first
the fastest model is the one whose KV fits
batch size is a business constraint wearing a tensor
English
@Mo7amed_Ma3rouf @kwindla @pipecat_ai Thanks @Mo7amed_Ma3rouf happy to help, @kwindla can you please share the pipeline or details how to share the Arabic dataset?
English

English

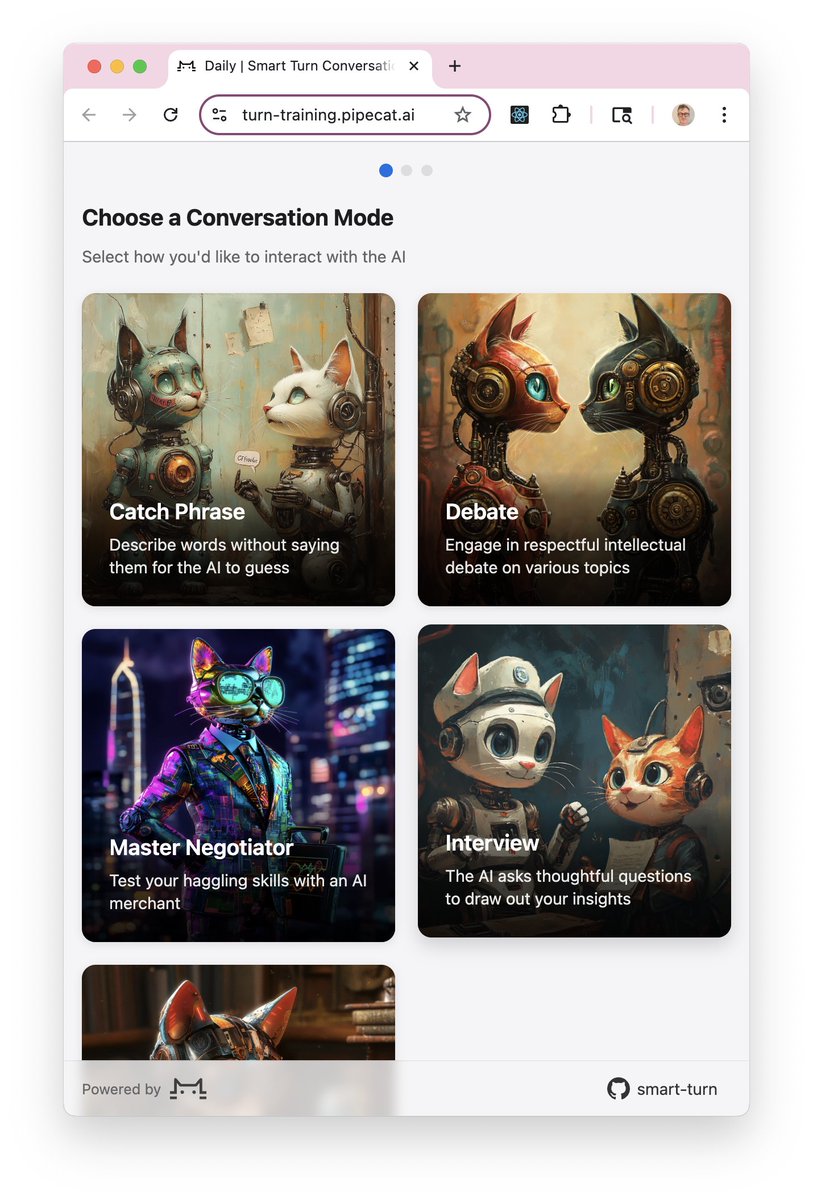
We're adding 14 languages to the @pipecat_ai native audio, open source, open data, smart turn (semantic VAD) model.
The new languages are: 🇫🇷 French, 🇩🇪 German, 🇪🇸 Spanish, 🇵🇹 Portuguese, 🇨🇳 Chinese, 🇯🇵 Japanese, 🇮🇳 Hindi, 🇮🇹 Italian, 🇰🇷 Korean, 🇳🇱 Dutch, 🇵🇱 Polish, 🇷🇺 Russian, and 🇹🇷 Turkish. There are also additional samples for English.
You can use this model with no restrictions, contribute data sets or code, play conversation games online to contribute data, or help us clean the raw data sets!
The model is hosted on @FAL, too.
English
@JustinLin610 Hi @JustinLin610 know of a company that uses Qwen-14, fine-tunes it, and now sells it as its own product. What do you think of this unauthorized use?
English


Why doesn't anyone include @Alibaba_Qwen in benchmarks? Is it because of the model's power, or are there other factors, perhaps political?
@JustinLin610
Cohere@cohere
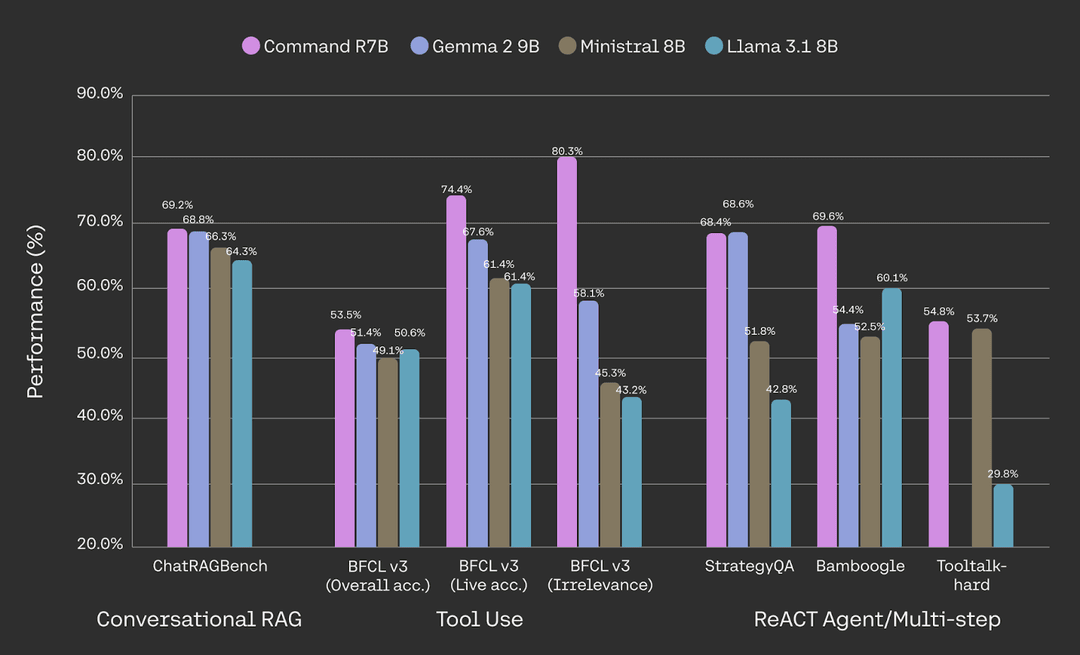
Introducing Command R7B: the smallest, fastest, and final model in our R series of enterprise-focused LLMs! It delivers a powerful combination of state-of-the-art performance in its class and efficiency to lower the cost of building AI applications. cohere.com/blog/command-r…
English
@zaidalyafeai @huggingface No one can
So I joined @far__el to build a new open-source alternative to huggingface
English