Lee Sharkey retweetledi

OK since p(doom) is discourse here is my view on communicating risk with probabilities. We should do it because it makes it much clearer to people what you think and is empirically demonstrated good epistemic practice. Also we should hedge to show high-order uncertainty.
Some theses:
1. Probabilities give people more insight into what you think. If you use vague, qualitative language instead of numbers, people will just assume what you mean. There's @PTetlock's famous Bay of Pigs anecdote, where an advisor told Kennedy there was a “fair chance,” meaning a 25% chance of success. Kennedy later reported he had assumed the advisor meant a 75% chance, and said he wouldn't have pursued the invasion if he had known the advisor only meant 25%!
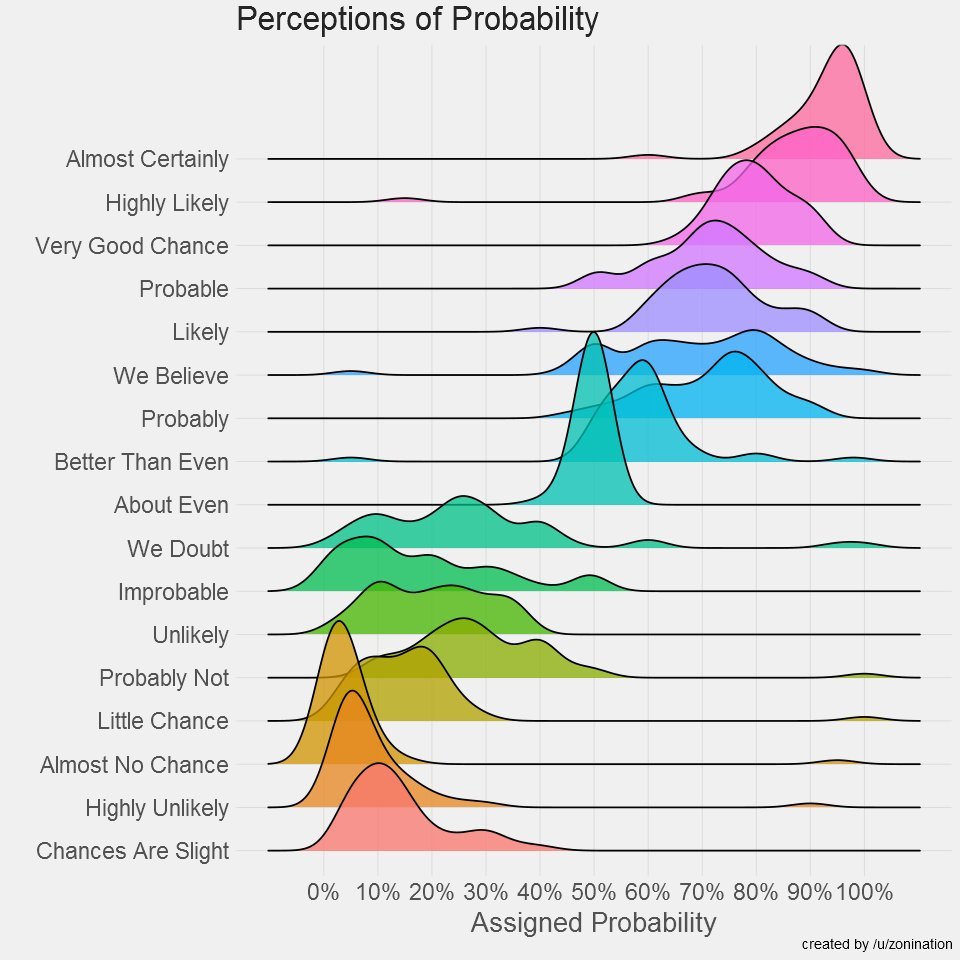
But this kind of miscommunication is ubiquitous. People assume different things about likelihood when speakers use qualitative language — it's an inherently less clear way to communicate what you are thinking. If you want your speaker to understand you, use numbers! Or at the very least, refer to the literature on perceptions of probability (see below) and pick your qualitative term very carefully so you communicate the right range! And don't use the extremely vague terms like "fair chance" or "improbable" that could mean literally anything to your listener. That is an extreme form of carelessness that we don't criticize often enough.
2. There haven't been many clear findings from the science of forecasting, but one of the clearest findings is that you make better predictions when you use precise numbers, even if these are completely made up. This is also true in group settings when aggregating the judgments of many people — which is essentially an idealized version of what we're doing pretty much any time we talk about probabilities. academic.oup.com/isq/article-ab… Here is an old thread I wrote on this topic some years ago: x.com/tyler_m_john/s…
3. Yes, people do perceive numbers as signaling more authority, and we shouldn't signal more authority than is appropriate. (How much is appropriate? Depends on the context. There isn't a universal answer in the context of existential risk from AI.) But you can do that without dropping numbers and losing the benefits of numbers I just set out. For example you can just use couching language, like "I would guess roughly 20%, but huge error bars, no one knows."
4. This can be studied!! It has already been studied a lot. I am finding it frustrating that no one in this debate is citing actual literature on perceptions of probabilities, especially in the age of LLMs where this information is readily available. We do know that percentages are viewed as more credible than qualitative language: papers.ssrn.com/sol3/papers.cf…. We do also know that hearing "61.87%" rather than "60%" triggers the inference that the speaker must have epistemic access that warrants the extra digits. frontiersin.org/journals/psych… How much higher-order confidence is it appropriate to convey when communicating the P(doom) of, say, a world expert on AI or an aggregate survey of every AI researcher publishing in NeurIPS? I don't know! If you want to make an argument that saying "20%" signals too much confidence, please cite some of this literature and explain why you think that the groundedness signaled to the audience is inappropriate.
If you do want to advocate for a different communication style, it is not expensive to run a quick MTurk study to see what people's perceptions of it are and compare it to default rhetoric. Or even more cheaply you can run it on LLMs, which are a decent natural laboratory for testing hypotheses about human psychology in the absence of humans to test on. I hope to practice what I preach in the coming days and run some more LLM tests (I've ran one N = 7000 test yesterday) and set up a Mechanical Turk account so I can test my above claim about couching probabilities being just as good as using qualitative language, but with more clarity in communication and better epistemic practice.
English