Wangda Tan
120 posts

Wangda Tan
@leftnoteasy
CTO & Co-Founder at https://t.co/l3GZZc31FW. ex SQL @ Snowflake, Member of Apache Software Foundation








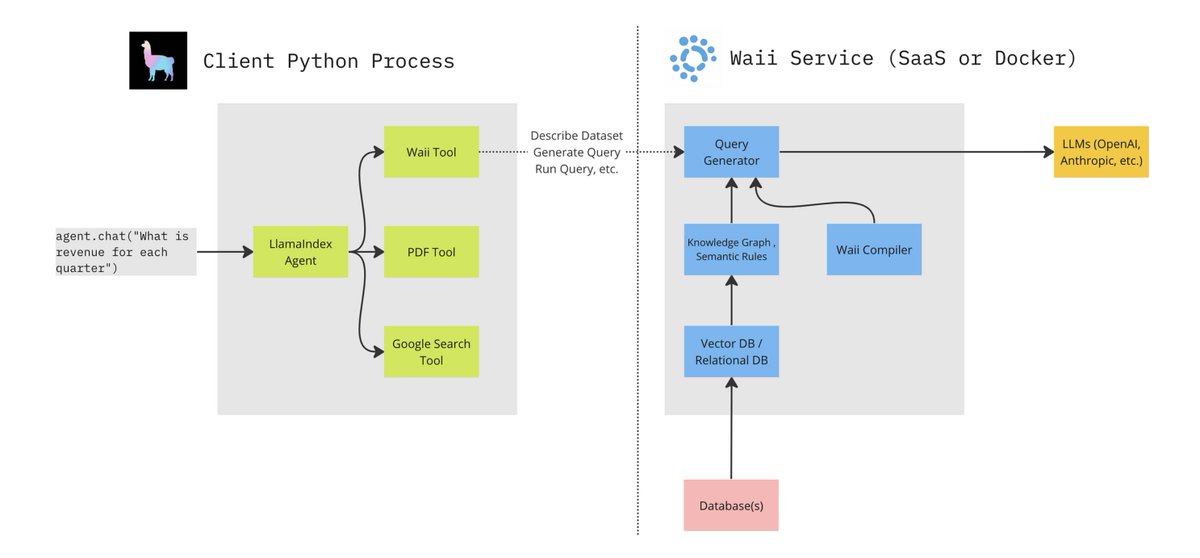
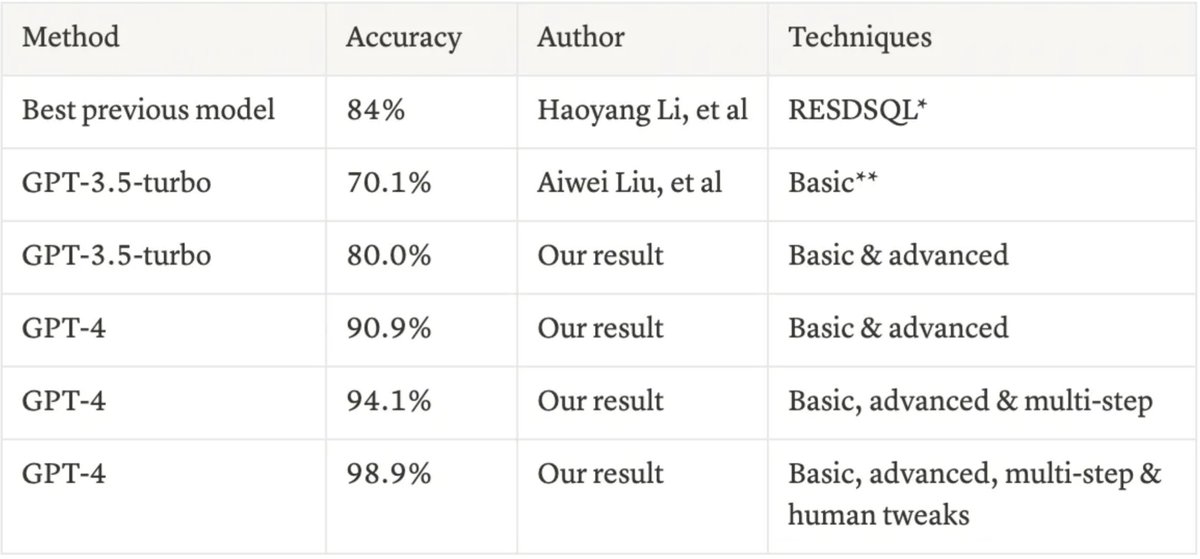
Building advanced text-to-SQL is hard. Building advanced QA over both structured and unstructured docs is even harder. We’re excited to feature a blog by @leftnoteasy (Waii.ai) - build an agent that can query enterprise-grade DB’s along with PDF data, with @llama_index + Waii.ai The enterprise text-to-SQL consists of the following: ✅ Knowledge Graph modeling metadata/query history to help table/schema selection ✅ Semantic rules: guide producing the right queries ✅ Automatic error correction through query compiler We use this over a SQL database of retail data, and combine this with a @llama_index RAG pipeline over a Deloitte PDF report. This allows our agent to compare the structured/unstructured data ⚖️ - e.g. the top items sold during the holidays. Check out the full blog! blog.llamaindex.ai/llamaindex-wai… Notebook: #scrollTo=fvye9sqAcn5j" target="_blank" rel="nofollow noopener">colab.research.google.com/drive/1hL_Ztb1…
Signup with Waii here: #request-demo" target="_blank" rel="nofollow noopener">waii.ai/#request-demo