@Dimdv99 @teortaxesTex All features are now included in the $30 plan. Unless these features are made available to free or premium members, they’re doomed to fail. No one is going to go out and pay $30. I used to really like Grok.
English
Lex Savage
40 posts



Grok 4.3 is absolutely ranking at the top in the latest Artificial Analysis benchmarks - #1 on IFBench (81%) - #1 on τ²-Bench Telecom (98%) - 74% Non-Hallucination Rate (Top-tier factual accuracy) - 196 Output Tokens per Second (Blazing fast) Not only did it take the #1 spot for IFBench and Telecom, but it’s doing this while pushing nearly 200 output tokens per second with a massive non-hallucination rate The competition is struggling to keep up with this balance of speed and sheer factual accuracy xAI is dominating the charts

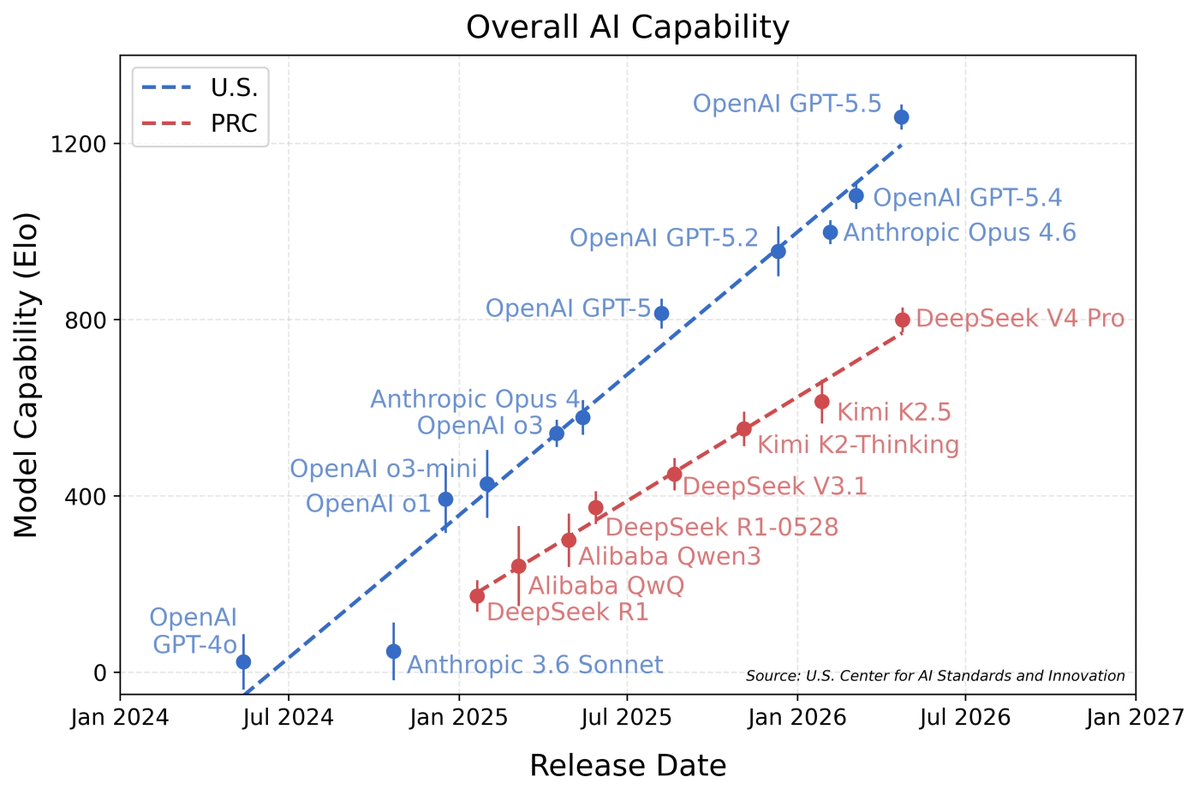
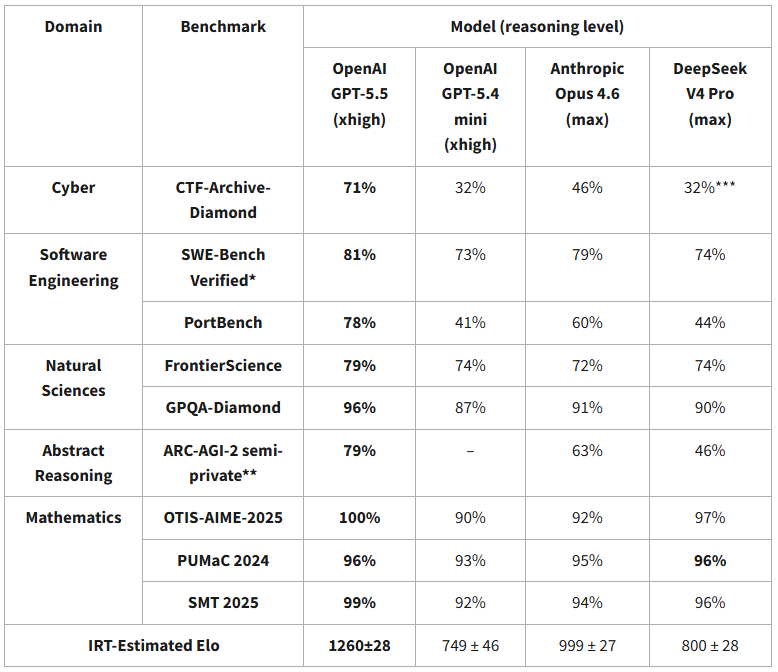
DeepSeek V4’s capability lags behind leading U.S. models by about 8 months. nist.gov/news-events/ne…










Now, we see you. 👀


rock bottom for DSV4. it's clear they don't train for this (but unclear why); DS models have never (?) performed here. It feels like a data engineering and post-training gap more than anything. Hopefully we'll see big lifts in future iterations on top of this base

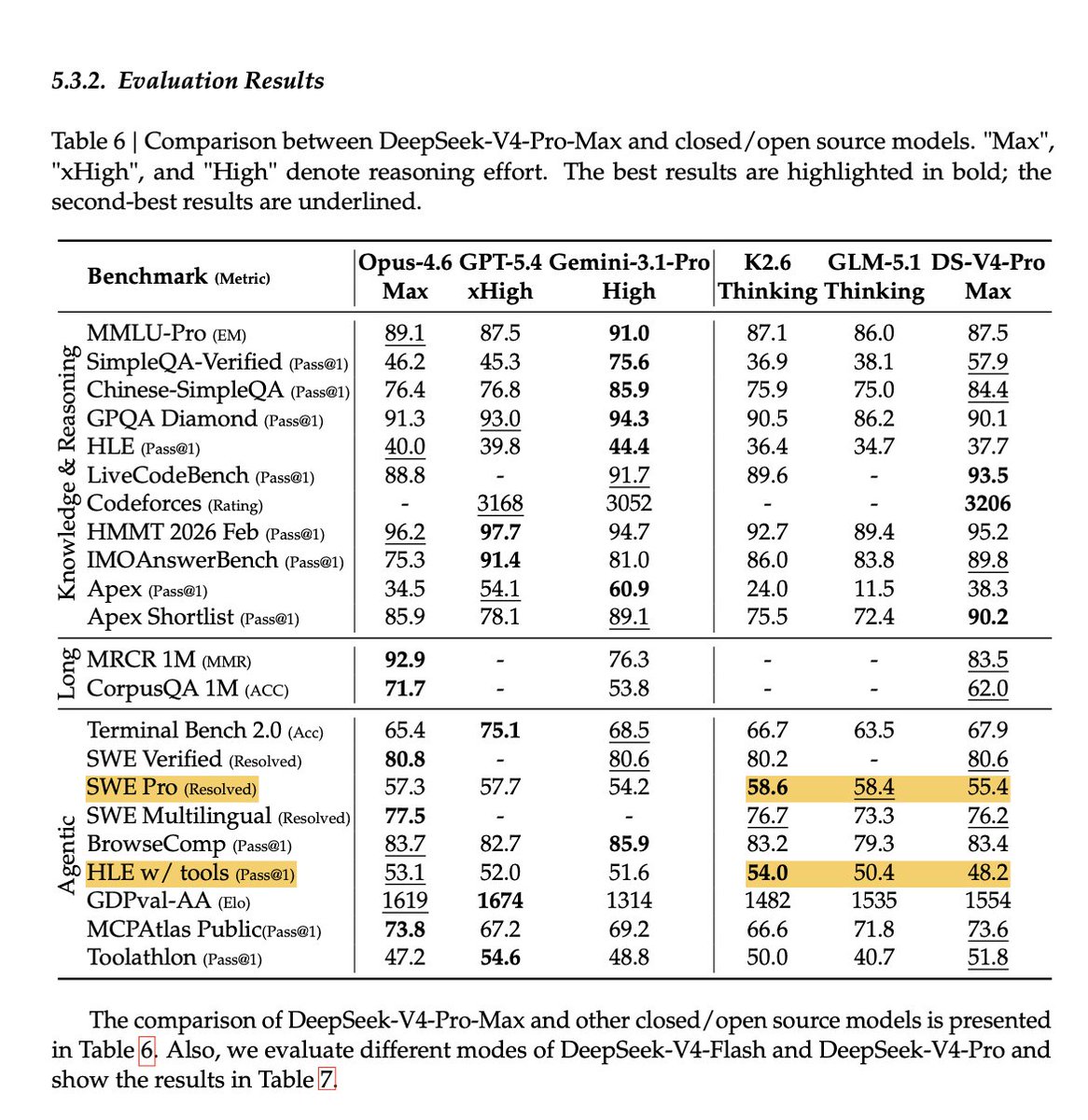
@teortaxesTex not the amount of (pre/post-training) data, but the quality (how many engineers cleaning data)





Exciting news - DeepSeek V4 Pro is in the Arena with 1.6T parameters (49B activated) alongside V4 Flash at 284B parameters (13B activated). Both support 1M token context. It’s a major leap over DeepSeek V3.2! Code Arena: - DeepSeek V4 Pro (thinking): #3 open model (#14 overall), on par with GPT-5.4-high and Gemini-3.1-Pro in agentic webdev tasks Text Arena: - DeepSeek V4 Pro (thinking): #2 open model (#14 overall), matching Kimi-2.6 - DeepSeek V4 Flash (thinking): #10 open model (#47 overall) Competition at the top of the open model leaderboards keeps heating up. Huge congrats to @DeepSeek_AI on the strong comeback!