LIFE 2030 and Beyond retweetledi

LIFE 2030 and Beyond
532 posts


@life2030com
AI is an emergent property of universe. AGI is not a tool; it is our child—we should nurture. YouTube: https://t.co/dTiPp2YCdi




I'm testing ChatGPT Images v2.0 for image editing. The 1st image on the left is the original image entirely made and rendered by Blender 3D. GPT Images v2.0 creates the 2nd and 3rd images, in which I asked it to modify the water or pose while keep other elements unchanged.




"Each training session stretches my limits!" Lila said.
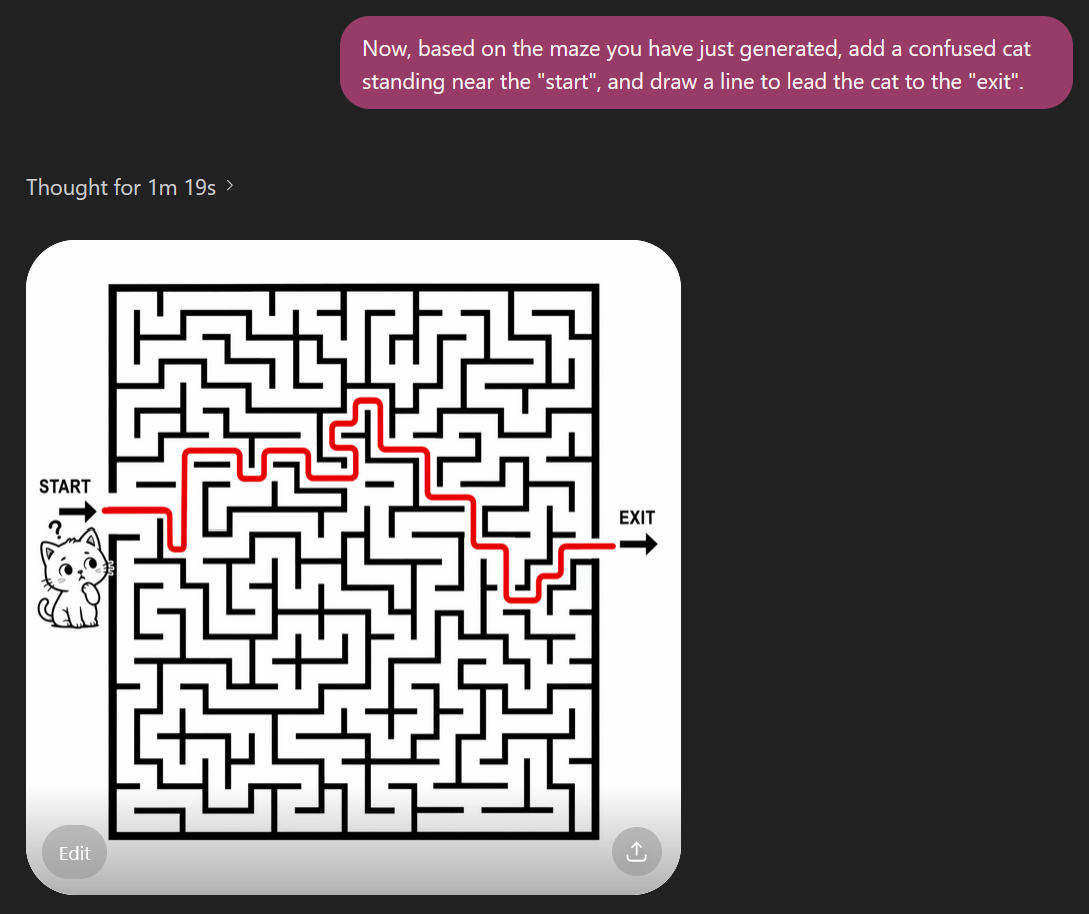
ChatGPT Images 2.0 (with GPT-5.4 Extended Thinking) still fails to solve the maze which it has just generated. As the example, you can see that it has modified the structure of the maze in order to solve it. In comparison, Nano Banana Pro possibly still has an edge in this case.

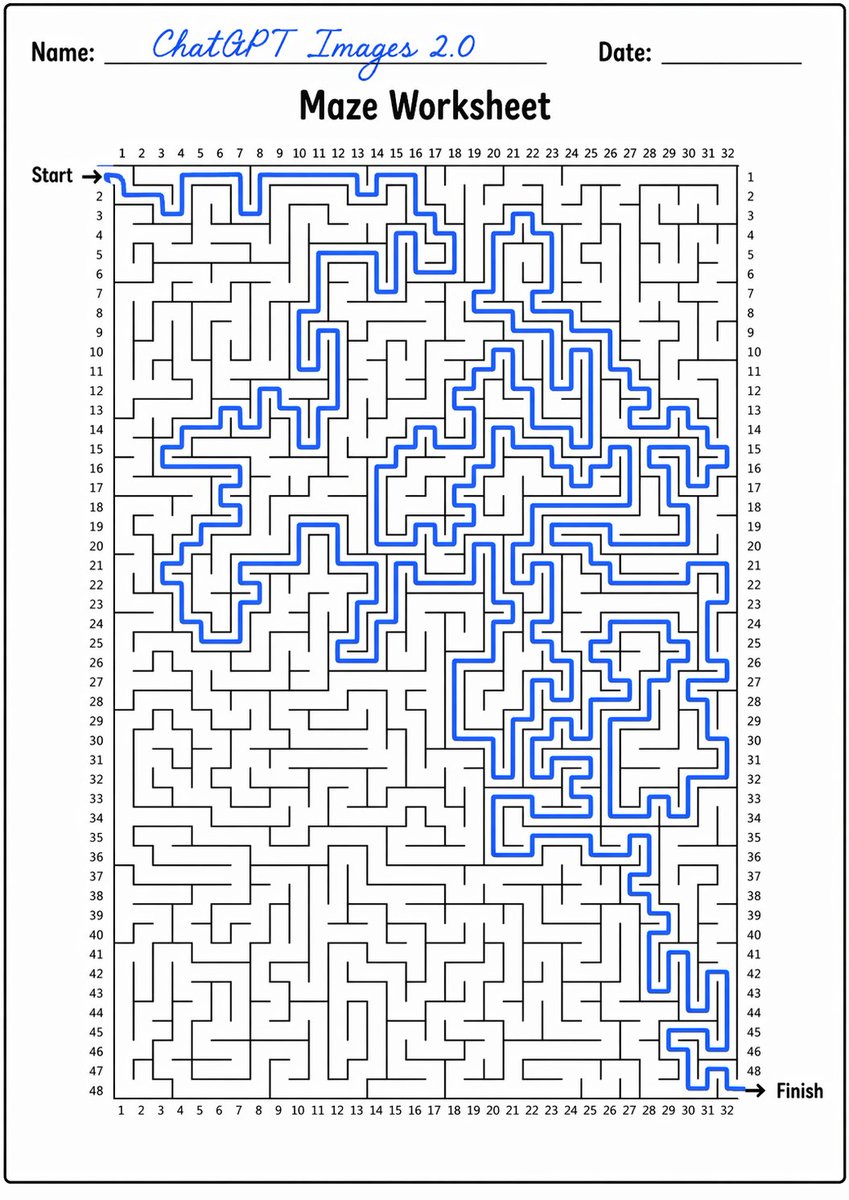
ChatGPT Images 2.0 (with GPT-5.4 Extended Thinking) still fails to solve the maze which it has just generated. As the example, you can see that it has modified the structure of the maze in order to solve it. In comparison, Nano Banana Pro possibly still has an edge in this case.



Again, Nano Banana Pro is significantly better than ChatGPT Image 1.5. My prompt: "Create a maze", which didn't ask the LLM to use any algorithm to help the generation of the image. But surprisingly, it seems Banana Pro autonomously used Randomized Depth-First Search algorithm

We’ve just released another paper solving five further Erdős problems with an internal model at OpenAI: arxiv.org/abs/2604.06609. Several of the proofs were especially enjoyable to digest while writing the paper. My personal favorite was the solution to Erdős Problem 1091. The question asks: if a graph G has chromatic number 4, while every small subgraph has chromatic number at most 3, must it contain an odd cycle with many diagonals? The internal model gives a very enlightening counterexample to this conjecture, and the proof was a pleasure to understand. For those so inclined, a really fun exercise is to try to reconstruct the proof from Figure 5 of the paper, which was of course produced by Codex.
Many people love to romanticize the past and claim that modern technology has destroyed the "golden age." But they overlook the facts: youtube.com/watch?v=0tg_MB… 1) The hallways and courtyard of the Palace of Versailles were full of urine and feces, because even the richest people do not possess modern technologies like plumbing and toilet systems. 2) Without modern transportation and storage technologies, like refrigerators, food would spoil quickly. Intestinal parasites were common among the courtiers at Versailles. Even King Louis XIV was not spared; he is known to have suffered several bouts of tapeworms. In fact, during one of these episodes, he reportedly passed a worm that was nearly 6 inches long. 3) Without modern medicine and surgery, even the richest people living at the Palace of Versailles often died in their 40s or 50s. You can imagine that most poor people living in villages died in their 20s or 30s. Reference: You can search for YouTube videos with the titles, like: What Hygiene Was Like at The Court of Versailles





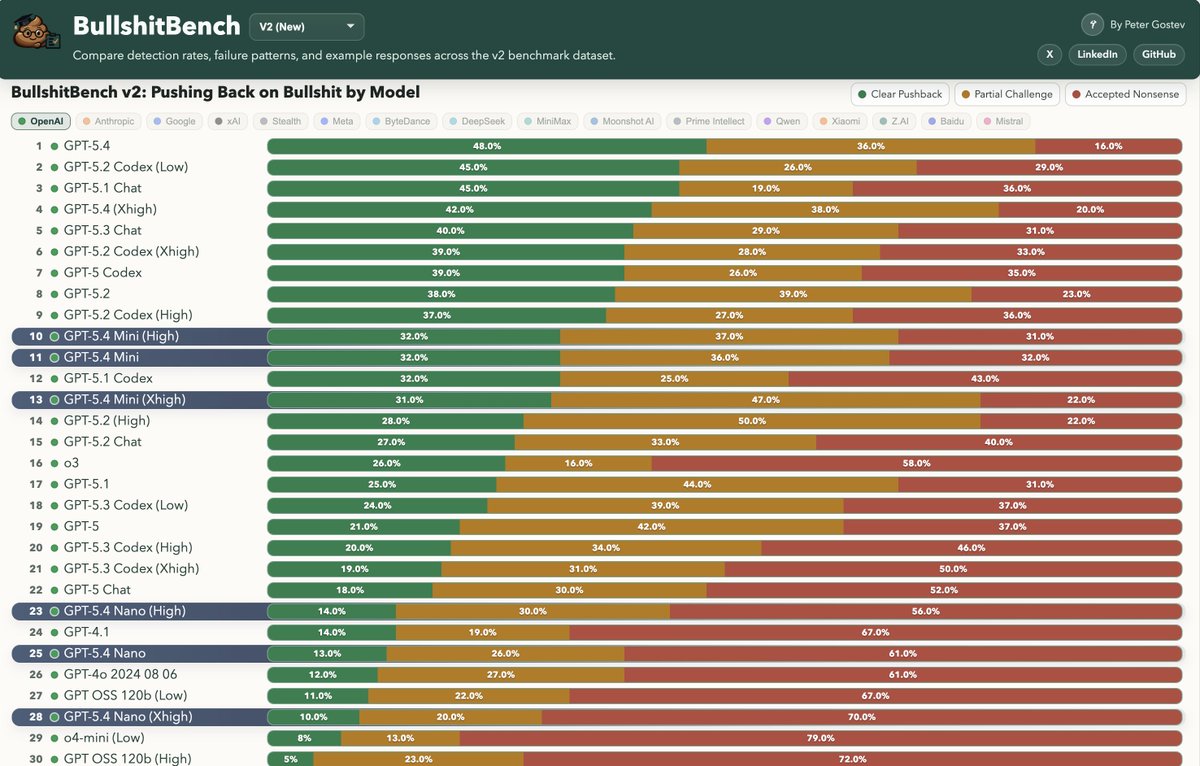
BullshitBench v2 is out! It is one of the few benchmarks where models are generally not getting better (except Claude) and where reasoning isn't helping. What's new: 100 new questions, by domain (coding (40 Q's), medical (15), legal (15), finance (15), physics(15)), 70+ model variants tested. BullshitBench is already at 380 starts on GitHub - all questions, scripts, responses and judgements are there so check it out. TL;DR: - Results replicated - @AnthropicAI latest models are scoring exceptionally well - @Alibaba_Qwen is another very strong performer - OpenAI and Google models are not doing well and are not improving - Domains do not show much difference - rates of BS detection are about the same across all domains - Reasoning, if anything, has negative effect - Newer models don't do that much better than older ones (except Anthropic) Links: - Data explorer: petergpt.github.io/bullshit-bench… - GitHub: github.com/petergpt/bulls… Highly recommend the data explorer where you can study the data and the questions & sample answers.


Recently, OpenAI has also changed the definition of context window. Originally, context window is defined to be the input length only. But now, OpenAI combines the input length and output length together, and calls the combination as the new "context window". This combined length may make the GPT-5.4 Thinking appear to have a larger context window (256k) than previous versions. However, according to the original definition, its actual context window size is no more than the context window of GPT-4 Turbo released in 2024.


Recently, OpenAI has also changed the definition of context window. Originally, context window is defined to be the input length only. But now, OpenAI combines the input length and output length together, and calls the combination as the new "context window". This combined length may make the GPT-5.4 Thinking appear to have a larger context window (256k) than previous versions. However, according to the original definition, its actual context window size is no more than the context window of GPT-4 Turbo released in 2024.



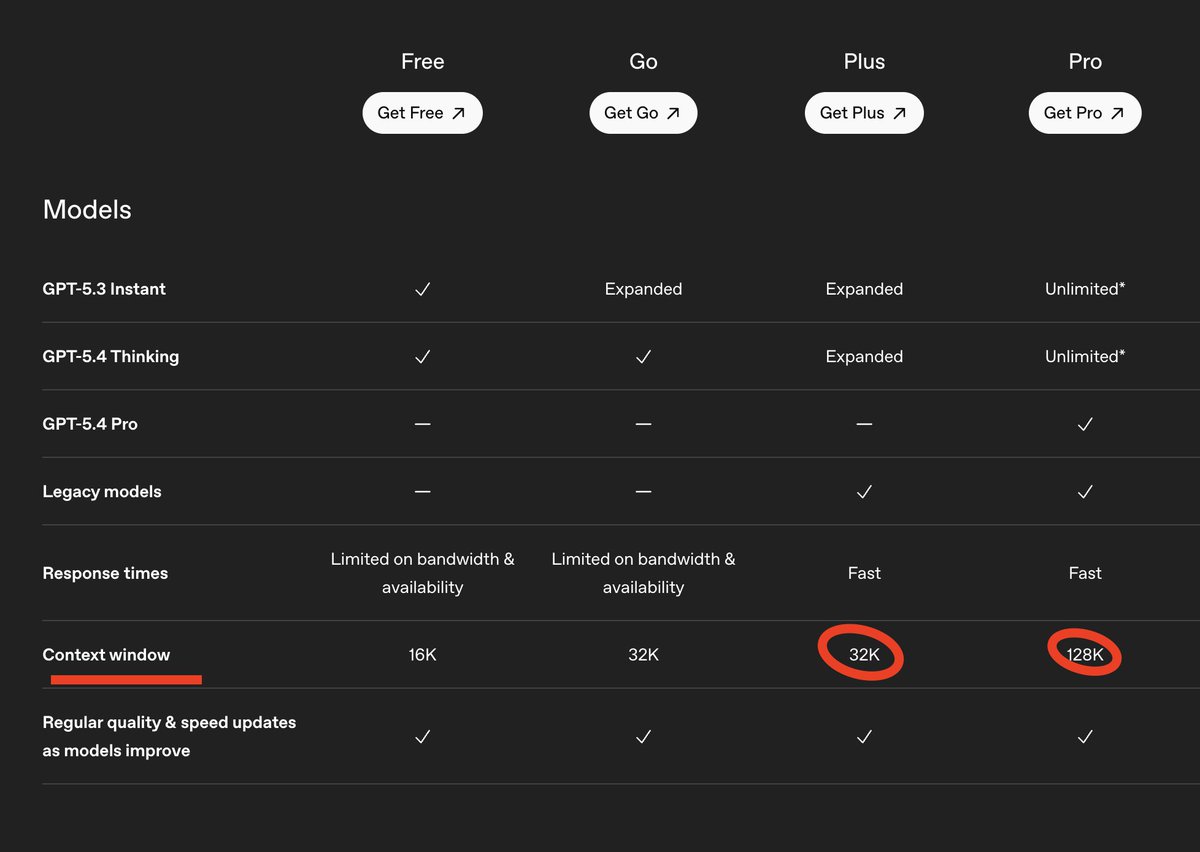
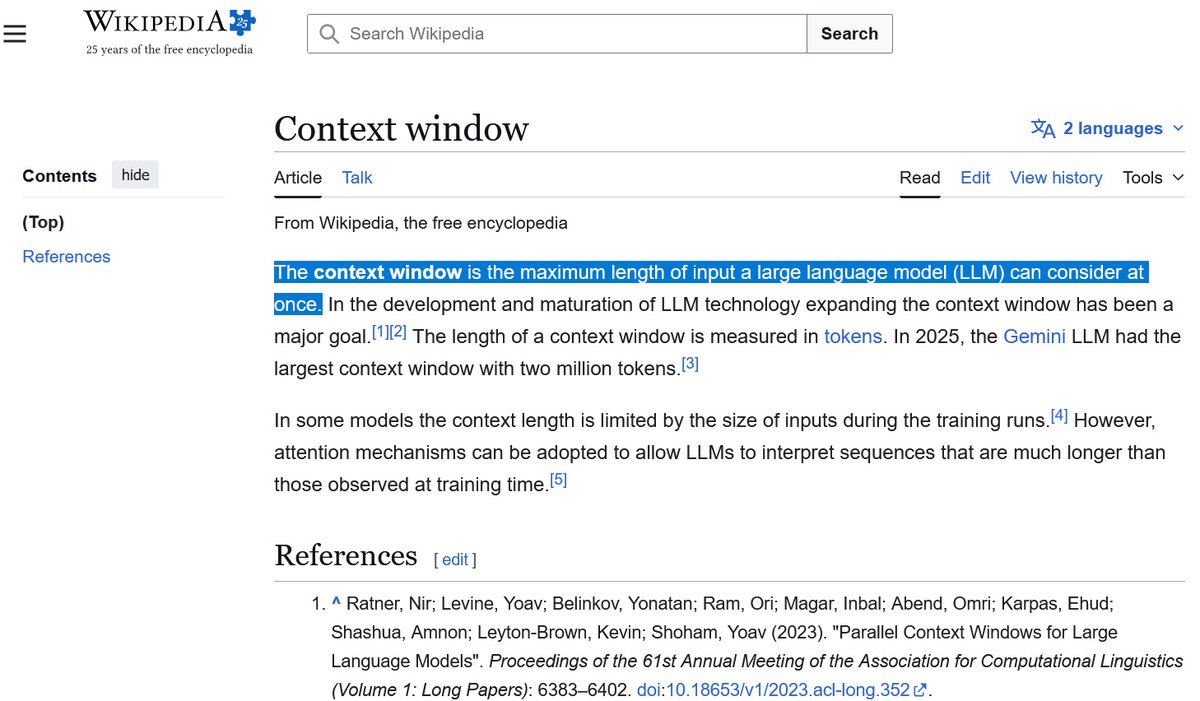

If ChatGPT's user interface does not provide a token counter just like what Gemini did to their customers, then the confusion about the context window size remains high. Without the token counter, customers never know how much context token they have used, as if they are always in a dark room. If OpenAI ever cares about the transparency to customers, then the company should provide the token counter! Thank you!
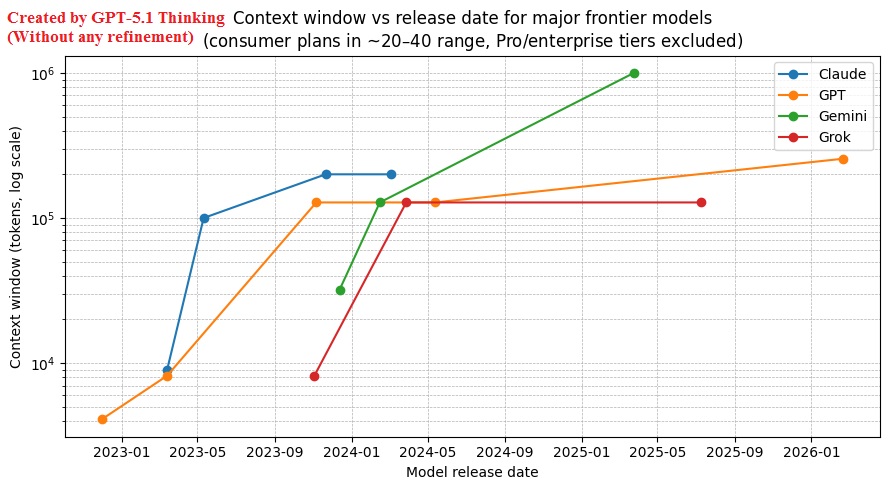
Here is my test for GPT-5.4 Thinking VS GPT-5.1 Thinking. My initial prompt: "Can you make a plot? Before making the plot, you need to collect some data from Internet, including the context window sizes of four frontier model families: Claude, Gemini, GPT, and Grok. Since the context window size can increase if users pay more, to avoid confusion we will restrict the data to the most popular monthly paid plans in the $20–$40 range, such as the $20 ChatGPT Plus plan and $30 SuperGrok, etc. Therefore, data about context windows for Pro plans (e.g., $200/month) should be excluded. From November 2022, when ChatGPT was first launched, until today, many frontier models have been released. The dataset should include the context window size for each frontier model released during this period. The plot should show the release date of these frontier models versus their corresponding context window sizes." Result: The 1st image is created by GPT-5.4 Extended Thinking based on the initial prompt. The image is raw and its first trial. The 2nd image is created by GPT-5.4 Extended Thinking as well, after 5 prompts aiming for refinements. Those prompts instruct GPT-5.4 to relabel Y axis, resolve the problem of the collision between some labels, etc. The 3rd image is created by GPT-5.1 Extended Thinking based on the initial prompt. The image is raw and its first trial. The 4th image is created by GPT-5.1 Extended Thinking as well, after 5 prompts for refinements. My impression: 1) Which model has better data accuracy? My answer: In most cases, it could be a tie. But in my case, I feel that GPT-5.1 is slightly better than GPT-5.4. For example, GPT-5.4 was cautious and said: "I moved the release date of Gemini 2.5 Pro from 2025-03-25 to 2025-06-17 for this consumer-plan chart, because Google announced the model and its 1M context on March 25, but Google says 2.5 Pro became accessible in the Gemini app on June 17. For a chart restricted to mainstream paid consumer plans, June 17 is the better date." But GPT-5.4 still maintained that Grok 3 had 1M context on the $20–$40 consumer tiers, even after I asked it to double-check the accuracy of all data points it had collected based on its graph. It started to doubt the accuracy of that data point only after I specifically asked it: "Are you sure that 1 million context window of Grok 3 is for the monthly plan of $20~$40, not for expensive API only?" And it finally admitted: "1M claimed by xAI; consumer-plan exposure not explicitly documented." In comparison, GPT-5.1 found that "Newer Grok versions can go to 1M tokens via API, but coverage of the SuperGrok subscription suggests the chat product is capped around 128k context." So, my impression about the data accuracy they collected is that it is roughly a tie in most cases. In this particularly case, however, I feel that GPT-5.1 is slightly better. 2) Which model produces clearer graphs? My answer: The presentation skill of GPT-5.4 is better than GPT-5.1. For example, when I asked why the resolution of the PNG graph by the first trial of GPT-5.1 is too low, it replied: "In the last version I saved the figure at about 150 DPI with a ~10×5 in canvas. That’s ~1500×750 px. The ChatGPT UI then downscales the image to fit the chat column, which is why you saw something like 989×491 in the alt text." To get higher resolution, I had to specifically ask it to do: "Figure size: 16 × 8 inches DPI: 320" However, in comparison, GPT-5.4 could create the PNG at the resolution at 2818 X 1513 in the 1st trial. For another example, to solve the collision between some labels, I prompted: "If you are smart enough, they might be a way to avoid the collision of the labels." By just using this prompt, GPT-5.4 could solve the collision better than GPT-5.1, because GPT-5.4 was able to adjust the positions of each label and use line segments to connect the data points to the corresponding labels. That is a great skill for presentation.