Sri Kosuri@srikosuri
OK. Here it is. Over the last year, the @OctantBio and OpenADMET team have been hard at work developing scalable, quantitative, data-rich, and low-cost methods for assessing CYP reactivity and inhibition. The interplay between building a data engine and building predictive models is often the most subtle, difficult, and impactful work in small-molecule AI/ML.
The blog post below is intended to highlight these issues and serve as a dialogue starter to help us, help you. In the post, we are:
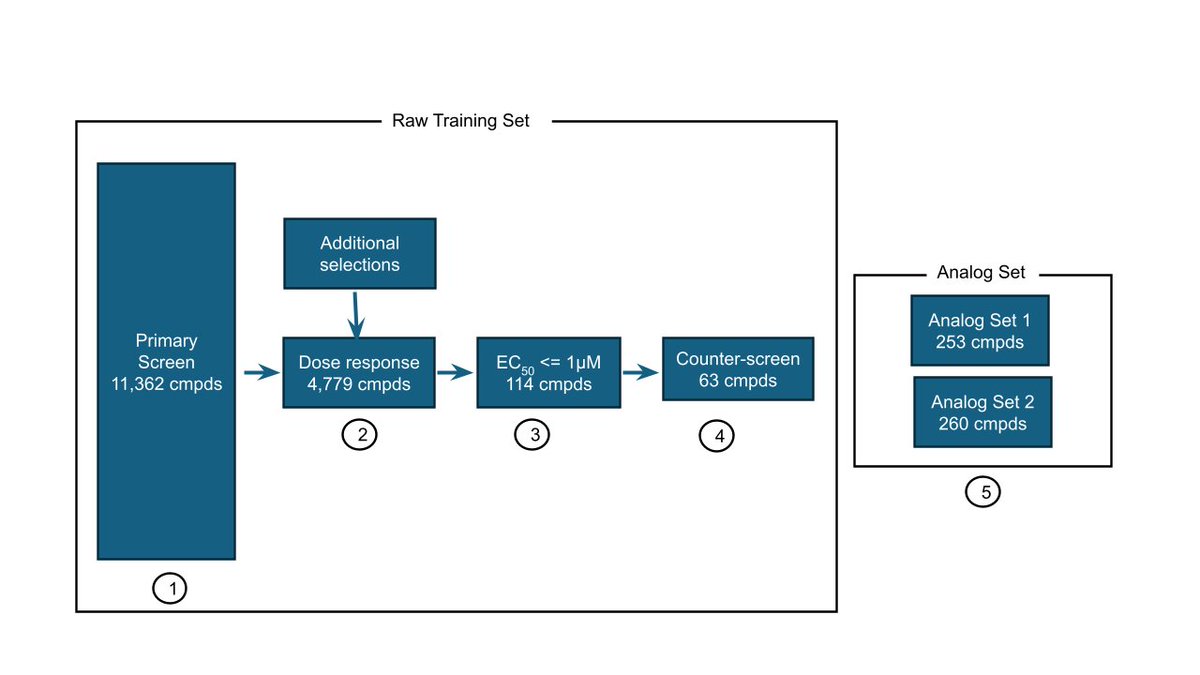
1. Give some background on the types of assays we are building and the technologies we are developing to scale ADMET datasets. We also go deeper into the tradeoffs inherent in building assays and exposing some of our design decisions.
2. A data drop of some of the largest self-consistent datasets for CYP reactivity and inhibition (CYP3A4 & CYP2J2). Importantly, we are exposing the raw datasets and are urging the community to help us design better methodologies and analytical tools to best extract the most informative data. This is a teaser dataset for the competitions we are running on CYP reactivity/inhibition blind challenge later this year.
4. A call to the AI/ML and ADMET community to help us decide on the types of data we should be collecting and holding blind competitions for. Should we focus more on inhibition or reactivity? What about TDI, metID, microsomal, and other types of assays? What should our screening funnel look like? What summary statistics should we try to predict? How useful is the raw data and uncertainty? How important is true negative data, or is it more important to get more quantitative data? What compounds should we screen? Given a budget, what data should we collect (some assays are more expensive than others)? How should we split the data for the blind challenge?