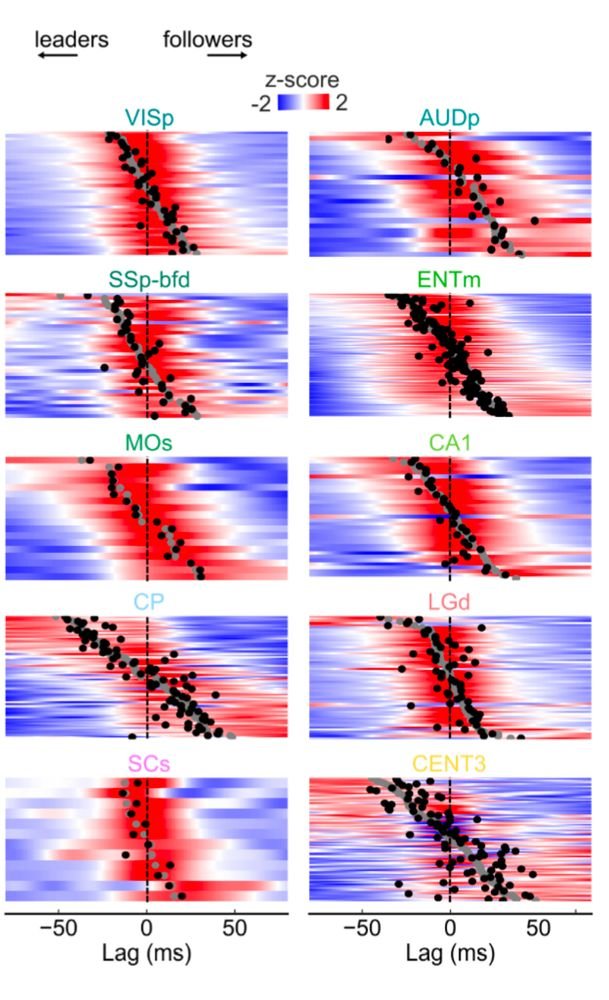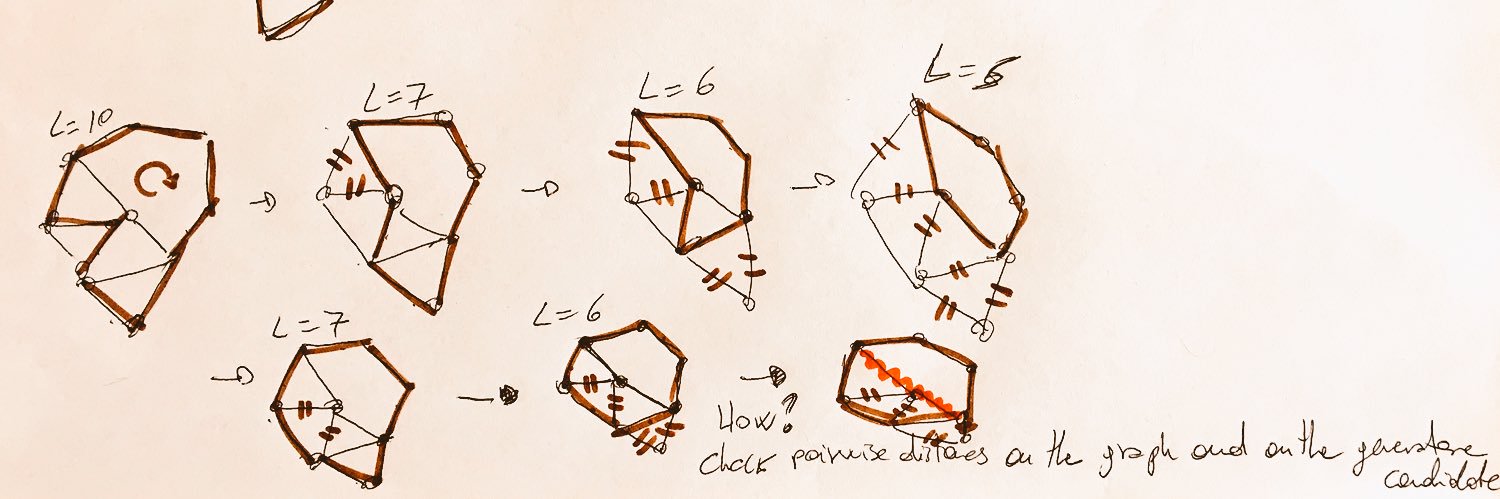
Sabitlenmiş Tweet

🧠 Renormalization in the brain?
With @andreasantor0 @richlyn_jesseba, we're organizing a full-day workshop at @CosyneMeeting (Lisbon, March 16) on how coarse-graining principles from physics can explain neural computation across scales.
Link here: nplresearch.github.io/neurorenorm202…

English