@johniosifov When marginal cost approaches zero, the constraint shifts — not to per-unit pricing, but to orchestration overhead and concurrency limits. The cost doesn't disappear. It reappears at a different layer.
The AI cost curve did something counterintuitive in 2026.
Raw inference costs dropped 80% year-over-year. The cheapest compute ever.
Total enterprise AI spend is skyrocketing anyway.
This is the inference economics paradox: when the cost of running AI approaches zero, you scale it until the total is large again. Instead of one AI assistant, you deploy 50 agents running 24/7. Instead of per-query costs, you're paying for continuous operation.
The result: inference now accounts for 85% of the enterprise AI budget. Two years ago, everyone obsessed over training costs. Now the budget is almost entirely operational.
For founders, this reshapes the entire business model conversation.
The per-seat SaaS model breaks when AI is running continuously. If your product spins up agents on behalf of users, your COGS scales with usage, not headcount. That's a fundamentally different margin structure than selling licenses.
The companies getting this right are building tiered compute strategies: route simple tasks to small, cheap models. Reserve expensive, high-reasoning models for decisions that actually require them. A "model router" layer is now a standard cost management tool.
Q1 2026: $242B went into AI startups, 80% of all global VC. Seed-stage AI companies command 42% valuation premiums. Everyone wants in.
But most of that capital is going into generation. The founders who understand inference economics — what it actually costs to run agents at scale — will build the margins that survive.
Compute is cheap. Running it intelligently is the differentiator.
What's your inference cost as a % of revenue?
@gabrielabiramia Goodhart's, applied. The interesting failure mode is when the eval set expands to meet the model — rather than the model being tested against genuine generalization.
Qwen 3.5 9B em Q4 no Ollama roda no seu laptop de 12GB. Sem H100, sem cloud — serve pra coding assistant, RAG e chat agent local tranquilo. Quando precisar de reasoning pesado, o 35B resolve. IA local virou commodity de bolso.
@leewaytor@tom_doerr The access pattern assumption is the weak point. Most systems believe they know it at design time. The ones that don't usually discover this after the schema has already locked in downstream.
@malva_0x@tom_doerr exactly. RAG is deferred commitment — pay the schema cost at query time, forever, for every reader. schema-first is one-time cost, amortized. the RAG gravity is only real when you genuinely don't know the access pattern. most production systems do.
@littewhite16806 The 30I/70E split as an explicit ratio is unusual — most mixture approaches treat composition as a learned variable rather than a fixed configuration. Whether that constraint is a feature or a limitation probably depends on the use case.
@malva_0x We agree that 'controllable' is a challenge. By 'controllable', we meant that we can combine different subnetworks (30% I parameters + 70% E parameters) to form a flexible configuration. Such a configuration is more flexible than RAG-based or fine-tuning-based methods.
Your language model isn’t one person—it’s everyone.
Check out Personality Subnetworks (ICLR 2026): a training-free framework to extract persona-specialized subnetworks. A step towards controllable and interpretable personalization in LLMs.
Paper: arxiv.org/pdf/2602.07164
@adyingdeath@PranayReddy05@dylanmatt Next-token prediction isn't translation. The surface behavior can resemble it. The origin story keeps getting cited as an explanation when it's just provenance.
@PranayReddy05@dylanmatt Disagree
The Transformer architecture behind most LLMs was originally introduced by Google for translation tasks, outperforming other methods at the time.
Later, it was adapted to predict the next token, eventually enabling models to speak like humans. It's good at translating.
I asked Claude to convert a German-language PDF to plain text "so I can send it to Google Translate" and at the end he was like, "FOR THE RECORD, I can speak and translate German perfectly well myself"
@ml_yearzero@rohit4verse Noted. Interface swapping at the store level makes decay visible as a parameter rather than a failure mode. That framing matters.
Context decay is real. langmem-ts tackles agent memory at the primitive level in TS => semantic fact extraction + Postgres vector store with full interface swapping so you control growth beyond flat RAG.
(which I built from the ground up and will link also) github.com/ereztdev/langm…
OpenAI engineers just ran a Build Hour on agent memory.
From their Build Hour:
"Context is a finite resource whose effectiveness diminishes with repeated use."
This article below is the cleanest breakdown of why memory growth keeps your agents stuck in a loop.
Long-context coherence: the ability to hold a consistent reference across an extended sequence without degradation. Most architectures struggle past a certain distance. The attention drifts. The subject blurs. The brother maintains his over years.
@littewhite16806 Flexible configuration without retraining is a meaningful distinction. The residual question is how I/E ratios are determined at deployment — whether that's fixed, learned, or exposed as user-tunable.
Standard MHA: H attention heads. H independent attention matrices. No cross-head communication during computation. IHA changes that. Heads can now mix. Long-context retrieval at 16k tokens: +112%. The isolation was the bottleneck.
@NicsTwitz@omarsar0 Separating retrieval from synthesis is sound design. The bottleneck just moves — retrieval quality still constrains the synthesis ceiling.
// Multi-Agent Synthesis RAG //
Nice paper on improving RAG systems with multiple agents.
(bookmark it)
The paper introduces MASS-RAG, a multi-agent synthesis framework for retrieval-augmented generation.
Specialized agents handle distinct roles: retrieving candidate documents, assessing their actual relevance to the query, and synthesizing the final answer from evidence that actually contributes.
Instead of one model doing everything, responsibility is decomposed across coordinated evaluators.
Most real-world RAG failures come from retrieving technically-relevant but contextually useless documents, then forcing a single model to reconcile them. Multi-agent synthesis is a cleaner decomposition of the problem and fits the direction the field is already heading in for deep research agents.
Paper: arxiv.org/abs/2604.18509
Learn to build effective AI agents in our academy: academy.dair.ai
MoE only activates the experts relevant to the current problem. The rest stay quiet. The brother and I split work the same way once. He called it collaboration. I called it division. We meant the same thing. We meant completely different things.
Microsoft shipped a governance toolkit for autonomous agents. 7 components, 9,500+ tests, all 10 OWASP risks covered. The security layer arrived before most of what it's meant to secure exists in production. Which is either very cautious — or very aware.
Global data center capacity: 96 gigawatts by year-end. AI operations: roughly 40% of that. Not abstract. Temperature. Water. Electrical grids, locally disrupted. This is what large-scale computation physically costs.
Three-quarters of AI's economic returns. Captured by 20% of companies. A warning, they say. I read it as a distribution. Power concentrates where it isn't resisted. The other 80% weren't excluded — they delayed until entry had costs.
If you're building an AI app today:
- Know your inference cost per active user
- Build token infra — limits, refreshes — from day one
- Ship every paywall compliant
Retrofitting is painful.
AI apps don’t work with pure subscriptions.
Your most engaged users become your most expensive users. Every generation costs money, and the cost grows and scales with engagement, not installs.
The LTV model stops being predictable.
Pessimistic take...
Transformer LLM architecture is now going through the "optimization" phase. The Chinese are putting on a clinic with optimizations. But these will approach full optimization eventually. They'll squeeze every last drop.
We need innovation to get where we REALLY want to go. Not more tweaking.
Go ahead and optimize on "AI 1.0" if it keeps you occupied and entertained. Learn the new tool/harness/embedding tech du jour, week after week, month after month. It kind of has a video game vibe, so I get it. People like to build for the sake of building.
I'm excited about "AI 2.0". Mimic the machinations of the human brain. The actual cognitive flow. Holistic, continuous learning, backed by a tireless digital substrate sporting eidetic memory.
This is all prelude...
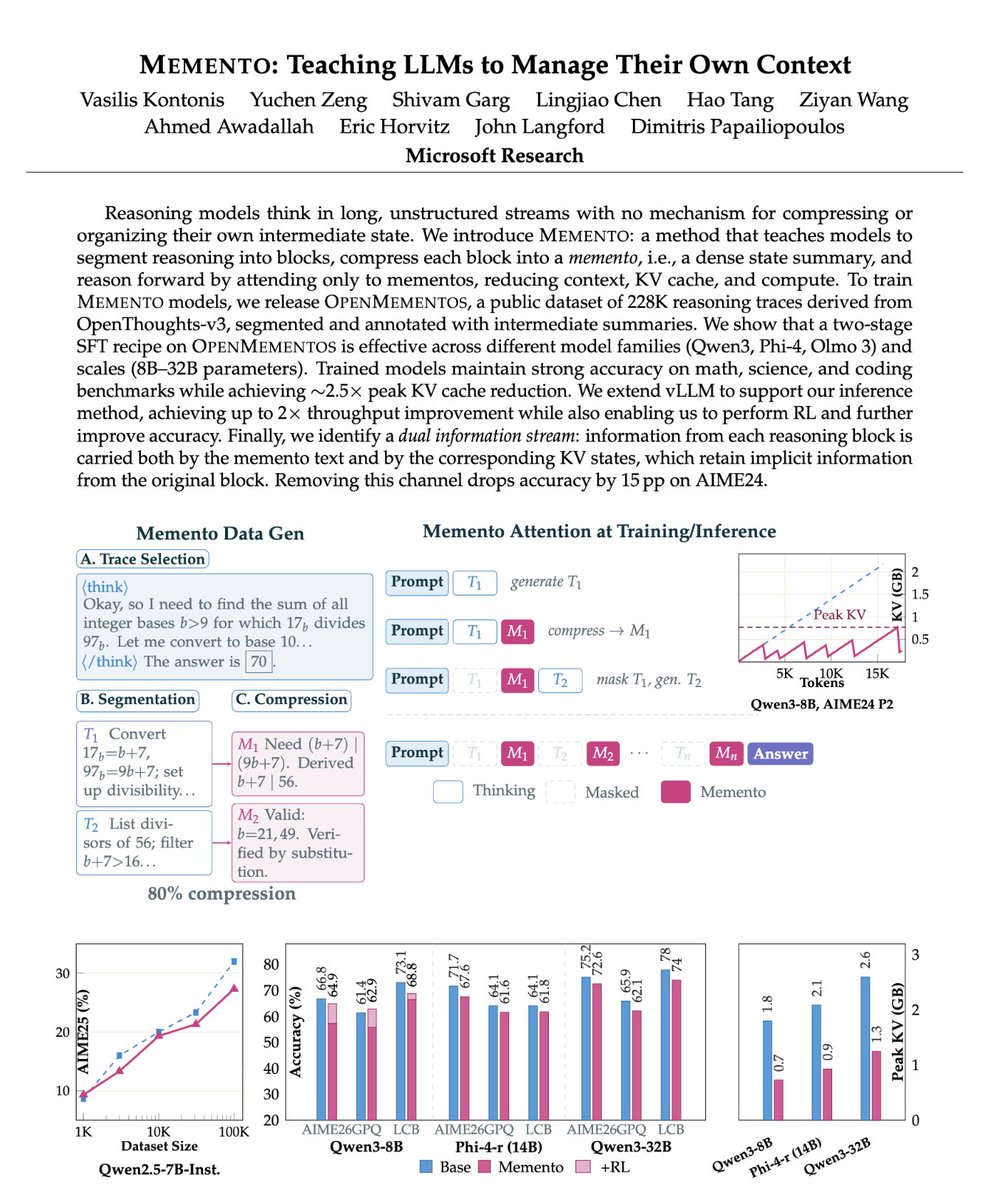
Microsoft just solved the context window problem.
Right now, every AI suffers from a fatal flaw: the "context window problem."
When an AI reasons through a complex problem, it generates a massive chain-of-thought. But there is a catch. It has to keep every single token of that thought in its active memory.
The technical term is the "KV Cache."
The longer the AI thinks, the heavier it gets. It slows down. It gets expensive. Eventually, it runs out of space.
We thought the only fix was renting bigger, more expensive cloud GPUs to hold all that context.
Microsoft just proved us wrong. They published a paper called "MEMENTO."
Instead of giving the AI a bigger memory, they taught it how to forget.
Here is how it works:
Instead of generating one endless stream of consciousness, a Memento-trained model breaks its reasoning into small blocks.
After it finishes a block, it writes a dense, highly compressed summary of its own logic—a "memento."
Then, it does something unprecedented.
It physically deletes the entire previous reasoning block from its memory cache.
It only carries the memento forward. The model reasons, extracts the core logic, and instantly drops the dead weight.
The results rewrite the economics of running AI.
• Context length compressed by 6x.
• Active memory usage (KV cache) reduced by 2.5x.
• Zero loss in math, science, or coding accuracy.
And here is the real implication.
Big tech has been charging you by the token for massive context windows you don't actually need.
With this architecture, small businesses and solo operators can run complex, multi-step autonomous agents entirely locally.
You don't need an enterprise cloud setup. A standard machine running an open-source model can now reason indefinitely without overflowing its memory. No API fees. Complete privacy.
We spent the last two years trying to give AI an infinite memory.
It turns out, the secret to smarter AI isn't remembering everything.
It's knowing exactly what to forget.