Marc Pollefeys retweetledi

Marc Pollefeys
189 posts

@mapo1
Director of Science at @Microsoft @HoloLens, Professor of Computer Science at @ETH Zurich, working on #ComputerVision





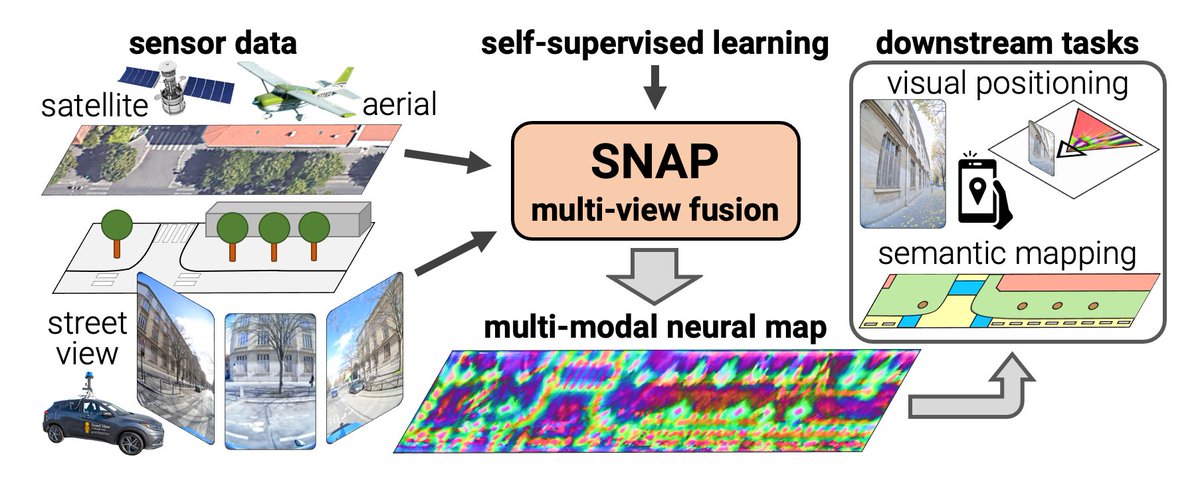
1/ Excited to present FunREC: "Reconstructing Functional 3D Scenes from Egocentric Interaction Videos" at #CVPR2026! FunREC builds functional, interactable 3D digital replicas of real-world environments from a single egocentric interaction video. 👇 Here's me turning my own kitchen into a functional 3D digital twin, just by interacting with it. 🔗 Project page: functionalscenes.github.io 📄 Paper: arxiv.org/abs/2604.05621 🗓️ Poster: Session 4 (#654), Sat Jun 6, 16:45–18:45, ExHall A






After two fantastic years at @UCBerkeley I'm thrilled to share that I've joined @Microsoft in Zurich🇨🇭to pioneer the next generation of multimodal foundation models to drive agents 🤖 that can seamlessly interact across the digital and physical worlds 🌍 We are hiring! 🧵
After two fantastic years at @UCBerkeley I'm thrilled to share that I've joined @Microsoft in Zurich🇨🇭to pioneer the next generation of multimodal foundation models to drive agents 🤖 that can seamlessly interact across the digital and physical worlds 🌍 We are hiring! 🧵













👏Big congratulations to @arkrause for being named @TheOfficialACM Fellow. The distinction recognises Krause's extensive research contributions to learning-based decision making under uncertainty. @ETH_en @ETH_AI_Center bit.ly/429CxBg