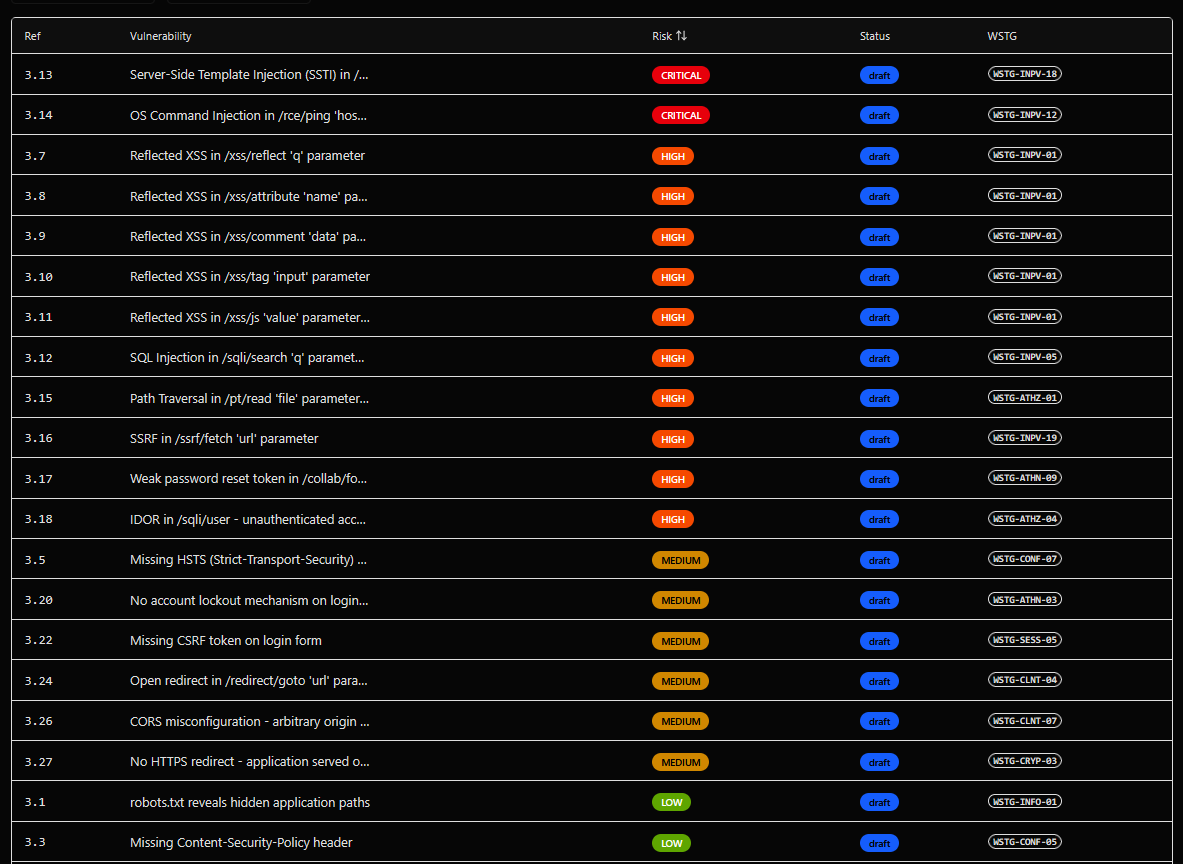
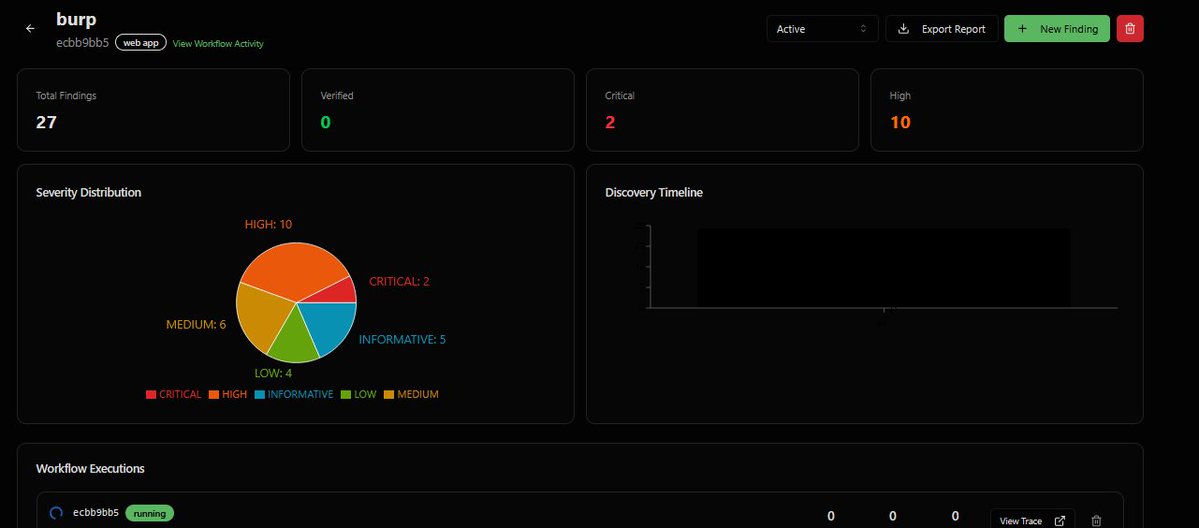
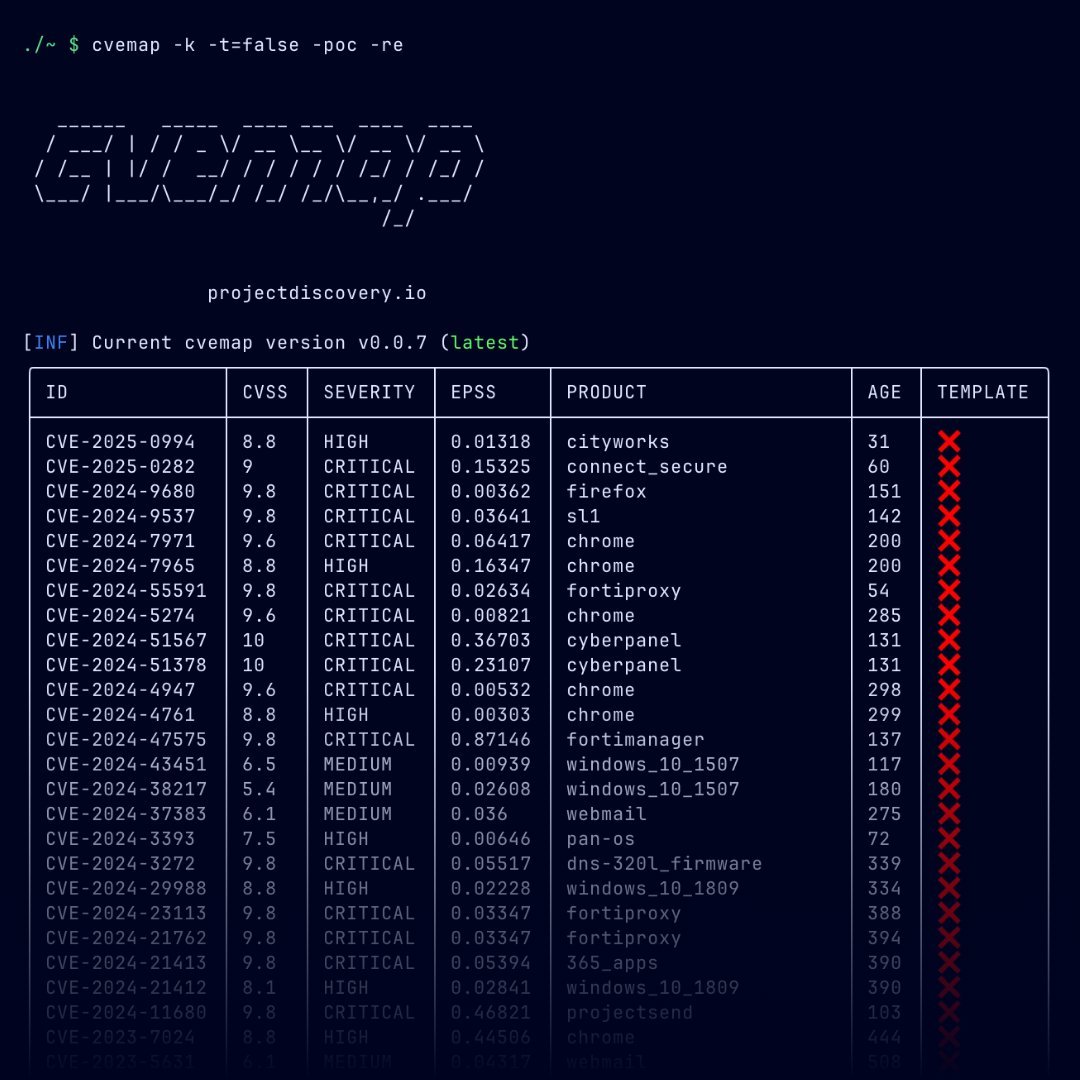
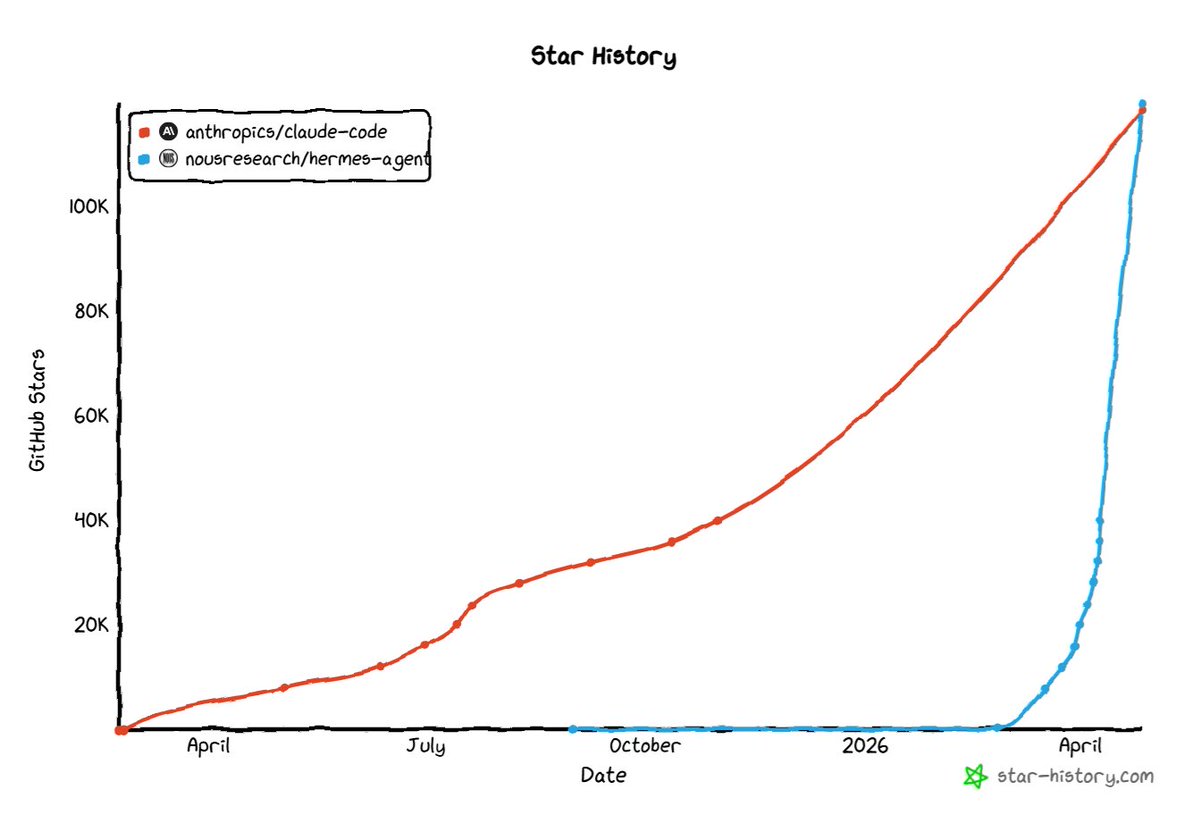
Sabitlenmiş Tweet

🚀 CEL (Continuous Execution Layer) — continuous AI-driven security for smart contracts, quantifying Funds at Risk (FAR) in real time.
Inspired by @Anthropic and @AliasRobotics research.
Check it out: github.com/michaelshapkin…
English