Michael, Britt retweetledi
Michael, Britt
16.2K posts



@WhiteHouse Debunking the CO2 "greenhouse gas" claim was always easy. Google history of atmospheric CO2. Timeline graphs have always shown us at or near all time low levels.
English

“GOOD RIDDANCE! After 15 years of Dumocrats promising that “Climate Change” is going to destroy the Planet, the United Nations TOP Climate Committee just admitted that its own projections (RCP8.5) were WRONG! WRONG! WRONG!” - President DONALD J. TRUMP 🇺🇸

English
Michael, Britt retweetledi

Michael, Britt retweetledi

$MU $DRAM $SNDK
The "Father of HBM' Prof. Kim Jeong-ho just dropped the most bullish line for memory investors in an interview.
"The Essence of AI is Memory. Future Semiconductor Demand Will Increase 100 Times or More" 🤯
"I believe it will grow exponentially. There are various factors involved; we need to produce personalized, custom-made solutions, move towards multi-models, and furthermore, I think we will enter an era in the future where one-person businesses start up with 100 AI agents. Then, let's leave the social issues of unemployment to discuss again when the opportunity arises. In that case, wouldn't we need about 100 times more memory? However, the number of users could also increase 100 times. Currently, I estimate that about 10% to 11% of the entire population actively uses AI. In the future, people could do all their work using AI all day long. If you multiply that by, much more AI memory might be needed in the future, but there are risk factors such as whether there is the capital to build it and whether the power supply is sufficient. We call that a bubble. Technically, if there isn't one, demand is bound to keep increasing.
"If you entrust it with a task without giving it one, that is called an autonomous AI agent. If we use 100 such agents, 100 of them are running 24 hours a day. This is referred to as token usage, and since token usage increases memory capacity, it seems that a demand for memory will be far greater than imagined. But as I have repeatedly mentioned, someone has to buy that. AI companies are creating that much added value, and people are willing to spend 1 million or even 10 million won out of their own pockets each month. The question is whether companies, nations, or individuals can afford to pay for that."
"...my argument is that as we move on to HBM4, 5, 6, and 7, we should also integrate GPUs and CPUs into the HBM. Since AI computing is memory-centric, the idea is that we shouldn't be dependent on the GPU; instead, we should handle everything ourselves and only hand over the slightly tedious calculations to the GPU. But to do that, we need a foundry. We need the capability to design and manufacture GPUs and CPUs. We can say that Samsung Electronics possesses that capability."
"In 10 years, anything will be possible. First, there are Micron and SanDisk. Although SanDisk hasn't pursued HBM, they are currently investing heavily in HBF. As the NAND market expands, the only way to increase capacity is by stacking chips. Therefore, from the perspective of Nvidia or Google, since Micron and SanDisk are U.S. companies, isn't it somewhat burdensome to go all-in on Korea, geopolitically speaking? They can foster U.S. companies, and Micron and SanDisk are among them. So, currently, production volume is inevitably much higher for Samsung and Hynix, and their performance is the best. Therefore, while they rely on them, in the long term, they will likely try to diversify across multiple companies, which is one risk. Another point is that they will likely continue to demand that Samsung Electronics and Hynix build factories in the U.S. It seems they intend to choose companies that are geographically close."
English
@goneers Con't find rhubarb here in Texas but growing up in Iowa it was everywhere. Walking to school, I would grab a stalk growing by the sidewalk and eat it on the way.
English




@ThrillaRilla369 Fasting and prayer are ways to prove faith. God requires proof. Church helps.
English

In a pretty heated debate
Do you need to go to church to worship God? ⛪️ 🙏
English


Michael, Britt retweetledi

I have no problem with Islam. I’m just against beheading, stoning, marrying little girls, sexual slavery, taqiyya, slave trading, rape, forced conversions, jihad, burqa, attacking other religions, child abuse, women abuse, animal abuse, multiple wives, murder, Sharia, terrorism, brainwashing, intolerance, greed, anti-science, torture, illiteracy, gluttony, genital mutilation, inbreeding. Does that make me Islamophobic?
English
Michael, Britt retweetledi

Michael, Britt retweetledi

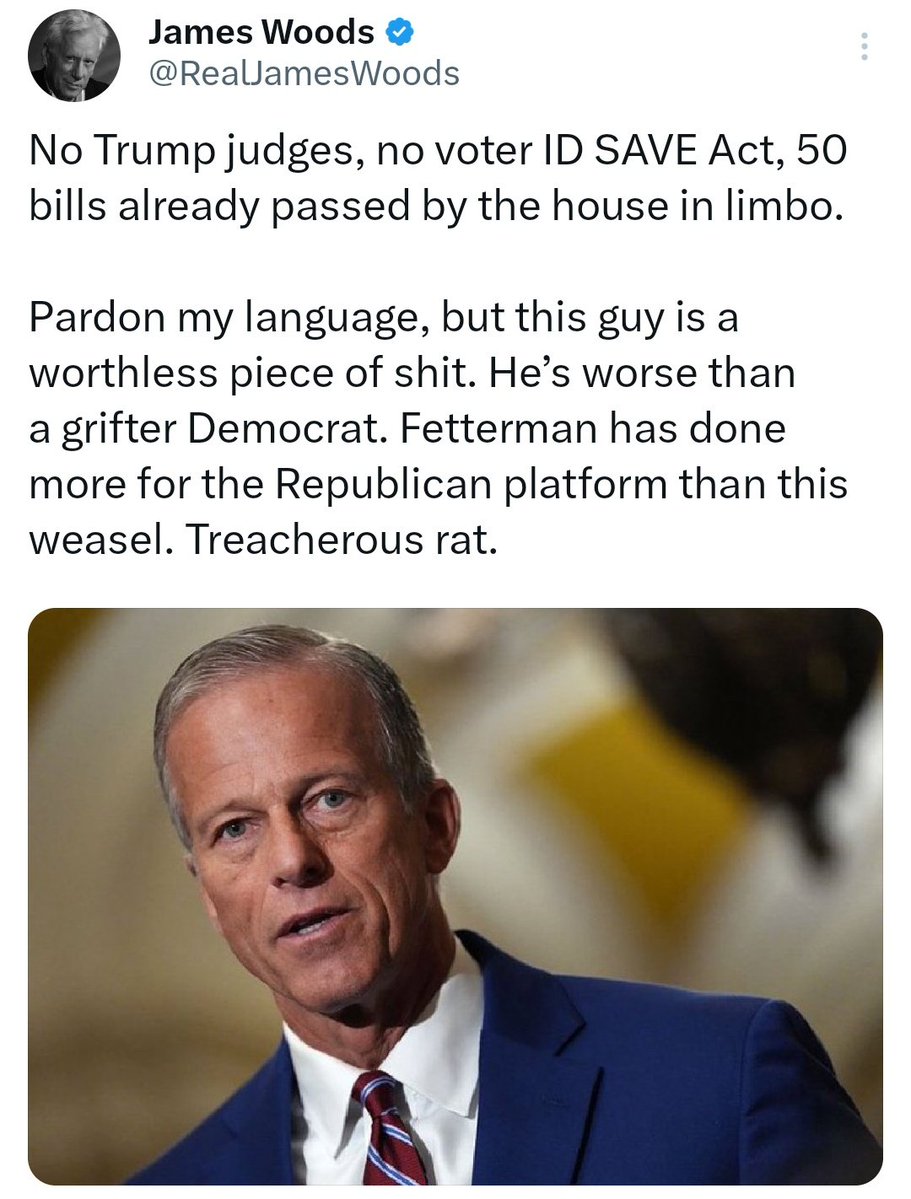
♦️NO SAVE ACT
♦️NO TRUMP JUDGES
♦️50 HOUSE BILLS SITTING ON YOUR DESK
♦️A PRESIDENT WHO HAS RECESS APPOINTMENTS BLOCKED BY HIS OWN
PARTY
♦️AMERICA’S POINTING THE FINGER AT YOU
♦️AND AT THE 5 SENATORS WHO BETTER
BELLY UP TO “THE AMERICA FIRST” BAR
♦️AND DUMP THE CHUMP NOW

English
Michael, Britt retweetledi

Susan Collins and Lisa Murkowski stabbed America in the back AGAIN.
Voting to defund ICE and rescind $75B for border enforcement?
Real Republicans secure the border. RINOs protect illegals.
Time to retire these two. Fire them in 2026!

English
Michael, Britt retweetledi

Michael, Britt retweetledi

🚨🔥President Trump is DONE with THUNE. Time for @SpeakerJohnson @HouseGOP to step up! “THE SAVE AMERICA ACT MUST BE PASSED, NOW. Use the Housing and FISA Bills to GET IT DONE!" @POTUS
English
@JohnCornyn Allready voted for Paxton. Cornyn is a RINO traitor.
English

Vote in the Republican runoff May 18-22 and May 26. While my name is on the ballot the Senate race is not about me or my opponent. It is about the future of Texas, the Republican Party, the US Senate, and President Trump’s agenda. Your vote is your voice!
English
@F28X5 Wow. Complexities here are beyond my realm. It seems that the SaaS industry will dominate all foreseeable human productivity from now on.
English
Michael, Britt retweetledi

Micron's Invisible Empire: Why the World's Most Important AI Company Doesn't Write AI Code
The Question Everyone Gets Wrong
When people compare Micron to NVIDIA, they usually frame it as a hardware race: whose chips are faster, whose bandwidth is higher, who ships first. That framing misses what is actually happening. The more interesting question is whether Micron — a company that makes memory — is quietly building one of the most strategically important software positions in the entire AI stack, precisely because it doesn't look like it's building software at all.
The short answer is yes. But the reasoning is more nuanced — and more consequential — than most analysis acknowledges.
Part 1: Why Micron Won't Build a "CUDA for Memory" — And Why That's Smart
CUDA works as a moat because NVIDIA controls both the hardware and the execution model. Developers write CUDA code, CUDA runs on NVIDIA silicon, and switching costs compound over time into near-permanent lock-in. It is a textbook platform strategy.
Memory cannot use this playbook. The reason is structural, not a failure of ambition.
Memory chips — whether HBM3E, HBM4, DDR5, or LPDDR5X — operate on standardized commands that must be universally legible. NVIDIA, AMD, Intel, Qualcomm, and every custom AI ASIC maker all plug into the same memory interfaces because the alternative is chaos. If Micron invented a proprietary "Micron Memory Language," its three major competitors — SK Hynix, Samsung, and domestic Chinese producers — would immediately offer fully compatible alternatives, and Micron's customers would switch without hesitation. The commodity nature of memory is not a weakness to be overcome; it is a physical and market reality to be navigated.
So Micron cannot lock developers in through a programming interface. What it can do — and is doing — is something more durable: make its memory so well-integrated into every layer of the AI stack that it becomes the natural, frictionless choice at every tier of the hierarchy.
That is a software strategy. It just operates below the line of visibility for most developers.
Part 2: The Real Software Stack Micron Is Building
Micron's software investment is not speculative. It is already deeply embedded in production infrastructure, organized across three distinct layers.
Layer 1: The Memory Tiering Engine (CXL and the Linux Kernel)
The core problem in modern AI is deceptively simple: GPU memory runs out. A 66-billion parameter model serving 10 concurrent users with 128,000-token context windows can consume over 3 terabytes of memory. No single GPU cluster holds that. The question is how to manage the overflow.
Micron's answer is CXL — Compute Express Link — a hardware interconnect standard that allows memory pools to be disaggregated, shared, and dynamically allocated across servers. But CXL is only as useful as the software that manages it. Micron is building that software: the kernel-level drivers, the memory tiering controllers, and the data placement logic that decides, in real time, what lives where.
The architecture works as an intelligent hierarchy. "Hot" data — the model weights and KV cache tokens being actively processed in this moment — stays in ultra-fast HBM, physically stacked on the GPU die. "Warm" data — recent conversation context, partially computed states, frequently accessed embeddings — gets placed in standard DRAM or CXL-attached memory pools. "Cold" data — training checkpoints, archived sessions, vector database indices — flows down to high-performance NVMe SSDs.
The software shuffles data between these tiers continuously, invisibly, and with latency that is 20 to 50 times lower than SSD-based solutions and meaningfully faster than RDMA over high-speed networking. Micron's H3 Falcon system, its CXL-based disaggregated memory platform, has demonstrated up to 20 times performance gains for graph database workloads — the kind of workloads that underpin knowledge retrieval in AI systems.
The developer sees none of this machinery. Their code just runs, with more capacity and less cost.
Layer 2: The KV Cache Revolution
One of the most underappreciated bottlenecks in deployed AI is the key-value cache — the short-term working memory that a transformer model maintains during inference. Every token generated requires reading and writing to this cache. At million-token context lengths, the cache alone can consume hundreds of gigabytes.
Micron's storage and systems teams are actively publishing research and building production tools around KV cache offloading — moving portions of the active cache to fast SSD storage rather than holding everything in expensive DRAM or HBM. The performance implications are significant: benchmarks show KV cache management via CXL delivering throughput improvements measured in multiples, not percentages, while cutting energy consumption per generated token by more than an order of magnitude.
This is not theoretical. Micron engineers are contributing directly to MLPerf Storage benchmarks, co-developing storage standards for vector databases and RAG workloads, and publishing the architectural analysis that shapes how the industry builds inference infrastructure.
Layer 3: FAMFS and the Disaggregated Memory Filesystem
Micron has developed and open-sourced FAMFS — a Linux-compatible filesystem specifically designed for large pools of disaggregated shared memory. Where traditional filesystems assume storage is attached to a single server, FAMFS allows multiple compute nodes to share a common memory fabric as if it were local. This is foundational infrastructure for AI clusters where dozens of GPUs must coordinate across a shared inference or training job.
FAMFS represents Micron's clearest statement that it intends to influence not just the hardware layer but the systems software layer that the hardware runs on. Open-sourcing it was a deliberate choice: it accelerates adoption, builds ecosystem dependency, and positions Micron as a collaborator rather than a vendor.
Part 3: Processing-in-Memory — Where Memory Becomes Compute
The most profound shift in Micron's long-term architecture is one that blurs the hardware boundary between memory and compute entirely.
Processing-in-Memory (PIM) places small compute engines directly inside the memory stack. Rather than shipping data to the GPU to do a calculation, the calculation happens where the data already lives. The energy and latency savings are substantial: data movement currently consumes a dominant share of total power in hyperscale AI clusters, and eliminating even a fraction of that movement has outsized effects at scale.
With HBM4, the bottom layer of the memory stack is being manufactured on advanced logic process nodes — the same class of silicon used to make CPUs. This creates physical space for logic that was previously impossible to include in a memory chip. Micron is exploring embedding operations like vector search, data filtering, and matrix element operations directly into this base die.
Here is the critical strategic insight: even in this scenario, Micron will not ask developers to learn a new programming model. Instead, it will write plug-ins for PyTorch, contribute primitives to CUDA and ROCm, and integrate with Hugging Face libraries so that specific operations — vector similarity search, attention head computation, embedding lookups — are automatically offloaded to in-memory compute engines without any developer awareness. The developer writes standard Python. The hardware does something extraordinary underneath.
This is the CUDA moat in reverse. NVIDIA's moat comes from making developers depend on NVIDIA's software. Micron's strategy is to make its hardware so deeply integrated into the software developers already use that switching to a different memory supplier introduces subtle, hard-to-diagnose performance regressions.
Part 4: The Business Model Evolution — From Commodity to Infrastructure
Understanding where Micron's software strategy leads requires stepping back from individual products and looking at the structural economics.
Today, Micron sells memory. Revenue is tied to bit volume and price per gigabyte — a famously cyclical, margin-compressing business. The AI wave has already begun to change this: HBM revenue surged nearly 50% sequentially in Micron's fiscal Q3 2025, reaching an annualized run rate above $6 billion, with the entire 2025 production already sold and 2026 demand extending the constraint. HBM commands dramatically higher margins than commodity DRAM precisely because it requires deep engineering collaboration with customers, not just component delivery.
But the more interesting trajectory is toward what might be called "Memory-as-Infrastructure." Consider the path:
Today: Micron sells HBM and CXL modules to GPU makers and hyperscalers. Pricing is per chip.
Near-term (2025–2027): Micron's software — CXL tiering engines, FAMFS, KV cache management tools — becomes deeply embedded in cloud AI infrastructure. Switching memory suppliers starts requiring software migration work, not just hardware swaps.
Medium-term (2027–2030): PIM capabilities create a new category of differentiated memory that accelerates specific AI operations. Customers co-design workloads with Micron's memory architecture in mind. Memory becomes a co-developed asset, not a purchased component.
Long-term (AGI era): Explored below.
This trajectory mirrors what happened in networking a decade ago. Ethernet was a commodity. Then networking became software-defined. Then it became cloud infrastructure. Then it became one of the highest-margin businesses in the data center. Memory is following the same path, compressed into a shorter timeframe by the urgency of AI demand.
Part 5: AGI and the Memory Implication Nobody Is Talking About
This is where the analysis requires genuine speculation, grounded in first principles rather than marketing roadmaps — but the logic is coherent.
Current AI systems are stateless between sessions. Every conversation starts fresh. Every inference request reconstructs context from scratch. This works well enough for task-oriented AI, but it represents a fundamental architectural limitation for anything resembling general intelligence. A system that forgets everything it has ever done cannot accumulate expertise, cannot maintain long-running commitments, cannot learn from operational experience.
AGI — however we define it — almost certainly requires persistent, accessible, rapidly queryable memory at a scale that has no precedent in computing history. Consider what that means concretely:
An AGI system maintaining continuous awareness across millions of simultaneous interactions, each with rich contextual history, each requiring sub-millisecond access to relevant prior experience, would require memory architectures that don't yet exist — not because the physics is impossible, but because no one has built them because no one has needed them.
Micron is one of perhaps three companies on earth with the manufacturing scale, materials science depth, and systems integration expertise to build those architectures. The FAMFS disaggregated memory fabric, the CXL tiering engine, the PIM compute layer — these are not products designed for today's chatbots. They are, arguably, the early infrastructure of machine memory at civilizational scale.
There are specific near-term manifestations of this:
Persistent Agent Memory: As AI agents run continuously for hours, days, or weeks on complex tasks, they need memory that persists across compute restarts, is shareable across multiple agent instances working on the same problem, and is queryable in structured and unstructured ways simultaneously. This is a memory problem before it is a compute problem. Micron's CXL fabric and FAMFS file system are direct precursors.
Federated Memory Across Devices: An AI that knows you — your preferences, your ongoing projects, your relationships — needs memory that travels with you across devices and contexts without being centralized in a single cloud server. This requires edge memory architectures (LPDDR6, next-generation embedded DRAM) that are tightly integrated with software that understands what data is important, when to sync, and how to protect it. Micron's edge memory portfolio and AI-at-the-edge strategy are building toward exactly this.
Memory as the Training Substrate: The next generation of AI training may not work by batching static datasets through gradient descent. It may work more like biological learning — continuous, experience-driven updates to a persistent world model. That requires memory that is simultaneously a storage medium and a computational substrate. PIM is the embryonic form of this.
None of this is guaranteed. But the directionality is coherent: as AI becomes more general, the demand for sophisticated, persistent, intelligent memory — and for the companies that can architect and manage it — increases nonlinearly.
Part 6: The Risks That Are Real
A thorough analysis requires acknowledging where the thesis could be wrong.
Commoditization pressure is permanent. SK Hynix and Samsung are not standing still. HBM4 competition will intensify through 2026 and beyond. The software moat Micron is building takes years to compound; in the interim, the business remains exposed to memory cycle downturns and geopolitical supply disruptions.
NVIDIA may close the vertical gap. NVIDIA's acquisition of Mellanox transformed networking from a supply chain input into a competitive advantage. NVIDIA could, in principle, attempt something similar in memory — either through acquisition, through NVLink-based proprietary memory interfaces, or through its Grace CPU architecture that already integrates memory and compute more tightly than traditional GPU servers. If NVIDIA successfully proprietary-izes the memory layer above the raw silicon, Micron's software influence narrows.
Open standards cut both ways. CXL's value comes from being an open standard — every vendor can build to it, and every customer can adopt it without lock-in. That universality is also why Micron cannot use it as a moat the way NVIDIA uses CUDA. The software Micron builds on top of CXL is where differentiation lives, and that software can be imitated.
Chinese competitive dynamics. Chinese AI infrastructure investment is accelerating sharply. Domestic memory producers, insulated from some export controls and subsidized by state policy, could develop competitive alternatives that reduce Micron's addressable market in the world's largest AI deployment geography.
The Bottom Line, Restated Precisely
NVIDIA's strategy is control: own the programming model, own the developer relationship, make switching painful. It works brilliantly, but it requires maintaining that control at every layer as the stack evolves.
Micron's strategy is indispensability: be so deeply embedded in the software infrastructure that the AI stack runs worse without Micron's contributions than with them, without ever asking developers to know Micron's name. Memory is not a product that Micron sells; it is a substrate that Micron architects.
The CUDA moat is visible and legible. Micron's moat is invisible — embedded in the Linux kernel, in open-source filesystems, in PyTorch primitives, in the tiering logic that silently moves data between memory hierarchies at 3 AM when no one is watching.
As AI models grow larger, as inference scales to billions of simultaneous users, as agents run continuously for weeks, and as the industry eventually confronts the memory requirements of genuinely general intelligence, the invisible infrastructure becomes the critical infrastructure.
Memory is no longer just where data lives. It is the architecture of how machines think.
And Micron is building that architecture — one kernel patch, one open-source filesystem, one CXL controller, and one processing-in-memory engine at a time.
Analysis current as of May 2026. Sources include Micron Technology white papers, SEC filings, Micron engineering blog posts on KV cache management, FAMFS, CXL tiering, and PIM research, as well as third-party analysis of HBM competitive dynamics and CXL infrastructure benchmarks.
$MU
English
Michael, Britt retweetledi

27 million Black people are still owned as slaves today in Islamic countries.
No Liberal ever complains about that!
English
Michael, Britt retweetledi
