
@vivek_2332 I feel like PipelineRL should be mentioned louder here :)
English
Rafael Pardinas
667 posts
@muchomuchacho
RL @ServiceNowRSRCH



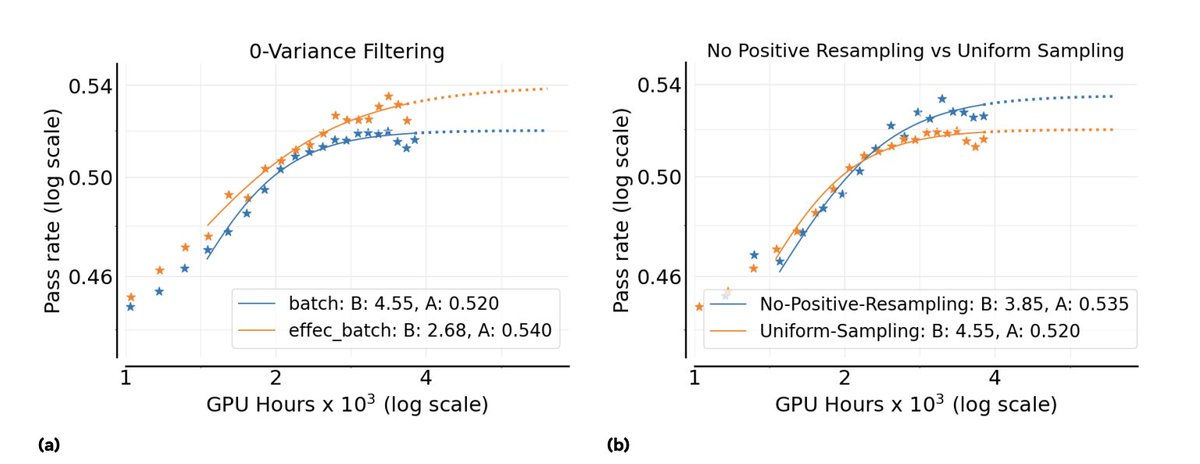








PipelineRL got accepted to TMLR 🎉 ~2x faster on-policy RL training through in-flight weight updates. Making LLM agents training fly at @ServiceNowRSRCH @alexpiche_ @DBahdanau @ehsk0 Paper: arxiv.org/abs/2509.19128 Code: github.com/ServiceNow/Pip…


💔RIP Lasko Fan💔 Based on my estimations, this $25 Lasko fan provided my family with over 33,000 hours of clean air. Yes, there were a few filter changes over those 33,000 hours but a CR box is still the most affordable way to access clean indoor air. @CRFoundationUS

Don't sleep on PipelineRL -- this is one of the biggest jumps in compute efficiency of RL setups that we found in the ScaleRL paper (also validated by Magistral & others before)! What's the problem PipelineRL solves? In RL for LLMs, we need to send weight updates from trainer to generator (to generate data from our latest policy being trained). (Conventional PPO-off-policy) A naive approach would be to "start generators on a batch, wait for all sequences to complete, update the model weights for both trainers and generators, and repeat. Unfortunately, this approach leads to idle generators and low pipeline efficiency due to heterogeneous completion times. (Pipeline-RL) Instead, we simply let the generators continue generating tokens without discarding or finishing ongoing generations in-flight whenever we need to do a weight update -- doing an "in-flight" weight update. As such our KV caches for these generations would be stale, as they would come from LLM with earlier copy(ies) of the weights) but this is ok (see below).



to continue the PipelineRL glazing, @finbarrtimbers implemented PipelineRL for open-instruct a little bit ago and it ended up being probably the single biggest speedup to our overall pipeline. We went from 2-week long RL runs to 5-day runs, without sacrificing performance (combined with some other threading etc. updates). Here's IFEval perf for an internal model (same data, same starting model, same bsz). Same number of training steps, same end perf, but PipelineRL is much faster.
to continue the PipelineRL glazing, @finbarrtimbers implemented PipelineRL for open-instruct a little bit ago and it ended up being probably the single biggest speedup to our overall pipeline. We went from 2-week long RL runs to 5-day runs, without sacrificing performance (combined with some other threading etc. updates). Here's IFEval perf for an internal model (same data, same starting model, same bsz). Same number of training steps, same end perf, but PipelineRL is much faster.


