
Matt Woods
2.7K posts
Matt Woods
@mv2woods
Builder | Additive Manufacturing | Bitcoin | EVs | XR | AI Founder Scrap Labs Co-founder Xact Metal Founder X Material Processing Ex-SpaceXer
Boulder Katılım Kasım 2011
222 Takip Edilen324 Takipçiler

@0xSero tbh its their model, they can do as the pls with the license. Weights are out there, they just want to be compensated if someone profits with their model. Not an unreasonable ask. Source available, open source... its just semantics if you ask me.
English

Defending MiniMax
I think it’s fine they set up a license. We kind of deserve it.
You work on something with dozens of people burning through investment money. Put it out to the world for free.
People say you’re benchmaxxing, call you a communist spy, take your models and sell them. Demand more from you.
You deal with this for a year, your peer’s models are being used in the west with little to no credits, same story.
They released the research, gave us the weights, released the environments, proved you can max 230B params competitive.
Thank you MiniMax. I hope you win more and more.

English

This afternoon I picked up a new Nvidia DGX Spark computer with the goal of trying to run Gemma 4 31b (4bit) on it locally as a server.
Just 1.5 hours later, it’s working!
Using Open WebUI on my MacBook as the interface and it’s connecting to my DGX Spark running as a Gemma 4 server.
English
@0xSero Are you bifurcating on x8? I need to figure out how to do this. I'm sure it's not that hard, just haven't gotten there yet. Do you see any drop in performance vs x16 pcie?
English

@observie i remember when PETG first came onto the scene. I switched and dont think i ever looked back. Why would you?
English

PETG is nice:
1. It doesn't smell. Both ABS and PLA too honestly smell too bad for me to keep working in the same room
2. It's not as brittle as PLA. You can actually use it for some dynamic system testing
3. Better heat resistance than PLA: it won't warp or soften as easily
I'm not sure why PLA is perceived as a beginner friendly go-to filament. I'd prefer PETG if only for the lack of smell

English


Introducing Gemma 4, our series of open weight (Apache 2.0 licensed) models, which are byte for byte the most capable open models in the world!
Gemma 4 is build to run on your hardware: phones, laptops, and desktops.
Frontier intelligence with a 26B MOE and a 31B Dense model!

English
Here are all the open weight models that can get close frontier level code, and tie for agentic purposes.
GLM-5.*
MiniMax-M2.*
Kimi-K2.5
Deepseek-V3.2
Qwen-3.5-Plus-397B
If you want AI at home for coding agents similar to Claude/Codex the VRAM needed 192GB for Q4 quant + REAP

English
Best models to run on your hardware:
—— 64 GB ——
- Qwen3-coder-next-80B-4bit (coding, Claude code, general agent)
- Qwen3.5-122B-reap: (browser use, multimodal, tool calling, general agent)
—— 96 GB ——
- GLM-4.6V (multimodal and tool calls)
- Hermes-70B (Jailbroken)
- Nemotron-120B-Super: (openclaw)
- Mistral-4-Small (general agent)
—— 192 GB ——
All these are excellent top tier LLMs and approach sonnet in capabilities
- Step-3.5-Flash
- Qwen3.5-397B-REAP
- MiniMax-M2.5 (soon M2.7)
- GLM-4.7-Reap
0xSero@0xSero
Best models to run on your hardware level I'll be doing this every week, I hope you guys enjoy. ---- 8 GB ---- Autocomplete for coding (like Cursor Tab) - huggingface.co/NexVeridian/ze… - huggingface.co/bartowski/zed-… Tool calling, assistant style - huggingface.co/nvidia/NVIDIA-… ---- 16 Gb ---- Here things get better: Multimodal - huggingface.co/Qwen/Qwen3.5-9B - huggingface.co/Tesslate/OmniC… - huggingface.co/unsloth/Qwen3.… ---- 24 GB ---- - The best model you can get (thanks Qwen) huggingface.co/Qwen/Qwen3.5-2… - Great model (strong agents) huggingface.co/nvidia/Nemotro… - Mine hehe huggingface.co/0xSero/Qwen-3.… I'm doing a weekly series
English
@t8rnutz @ScrapLabs3D @rmrrf I founded and have a stake in the company that sells $100k printers. They can't and won't buy us out :)
English

@ScrapLabs3D @rmrrf Countdown till some big company just buys them out and sticks it in the closet so they can keep selling $100k machines.
English
Matt Woods retweetledi

The wait is almost over. We'll be unveiling the Scrap 1 Metal 3D Printer at the @rmrrf April 18-19th in Loveland, Colorado. This is Scrap Labs' first product, and we cannot wait to show you what we've built. Initial kits start at $9,990 with our limited time early bird discount.

English
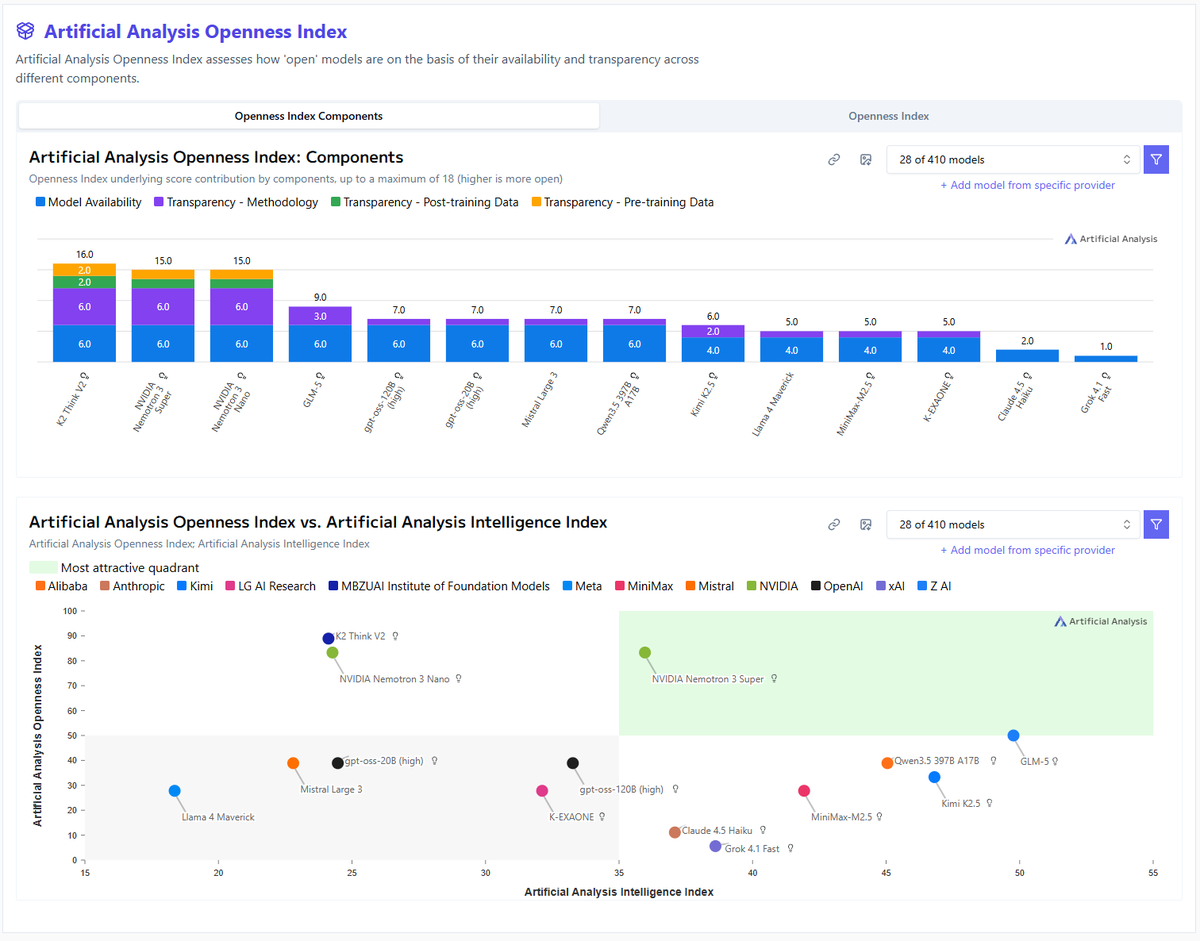

NVIDIA has released Nemotron 3 Super, a 120B (12B active) open weights reasoning model that scores 36 on the Artificial Analysis Intelligence Index with a hybrid Mamba-Transformer MoE architecture
We were given access to this model ahead of launch and evaluated it across intelligence, openness, and inference efficiency.
Key takeaways
➤ Combines high openness with strong intelligence: Nemotron 3 Super performs strongly for its size and is substantially more intelligent than any other model with comparable openness
➤ Nemotron 3 Super scored 36 on the Artificial Analysis Intelligence Index, +17 points ahead of the previous Super release and +12 points from Nemotron 3 Nano. Compared to models in a similar size category, this places it ahead of gpt-oss-120b (33), but behind the recently-released Qwen3.5 122B A10B (42).
➤ Focused on efficient intelligence: we found Nemotron 3 Super to have higher intelligence than gpt-oss-120b while enabling ~10% higher throughput per GPU in a simple but realistic load test
➤ Supported today for fast serverless inference: providers including @DeepInfra and @LightningAI are serving this model at launch with speeds of up to 484 tokens per second
Model details
📝 Nemotron 3 Super has 120.6B total and 12.7B active parameters, along with a 1 million token context window and hybrid reasoning support. It is published with open weights and a permissive license, alongside open training data and methodology disclosure
📐 The model has several design features enabling efficient inference, including using hybrid Mamba-Transformer and LatentMoE architectures, multi-token prediction, and NVFP4 quantized weights
🎯 NVIDIA pre-trained Nemotron 3 Super in (mostly) NVFP4 precision, but moved to BF16 for post-training. Our evaluation scores use the BF16 weights
🧠 We benchmarked Nemotron 3 Super in its highest-effort reasoning mode ("regular"), the most capable of the model's three inference modes (reasoning-off, low-effort, and regular)

English
@jeremyjudkins_ Toy Trucks, no matter how big, dont bring happiness.
English

Life is too short to wait this long for something you want. Spend the extra money and get the more expensive Cybertruck now.
Have you considered there is a non zero chance you could be dead before 2027? And you are waiting to save a few thousand dollars?
Money is meaningless when our life is over so stop being cheap and do what makes you happy.

English
@TheAhmadOsman bro I've invested so much in GPUs and still can't even begin to think about running this model.
English


I wonder if OpenAI is planning to go public bc they need an exit before the FOSS models which are seemingly getting released every wk are coming for their moat and if they dont exit before that moat is gone, then... Well, less $$$
MinimaxM2.5 is within spitting distance at 230B!
English
I wonder if OpenAI is planning to go public bc they need an exit before the FOSS models which are seemingly getting released every wk are coming for their moat and if they dont exit before that moat is gone, then... Well, less $$$
MinimaxM2.5 is within spitting distance at 230B!

English
@0xSero Now we've got Minimax 2.5 out! Crushes the agentic scores, but the trade off is increased hallucination rate according to the scores.
English
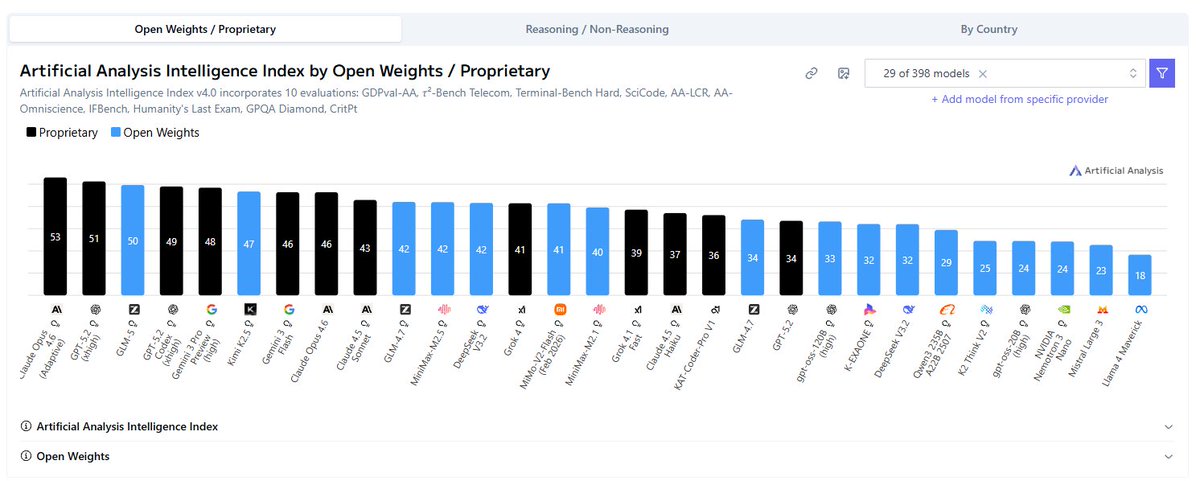
Best open weight labs:
#1 MiniMax: they squeeze every last drop of intelligence out of such a small model
#2 Kimi: Their latest model is so good at computer use, I don’t think most people have tried it in Parchi, it doesn’t fail.
#3 GLM: This is probably the most intelligent but also the hardest to use, similar to GPT
Best closed weight labs:
#1 OpenAI:
- Spark is revolutionary
- GPT codex is the best coder
- GPT Pro is the best researcher
That’s it folks, we are out of LLMs, my GPUs are itching for MiniMax open weights

English
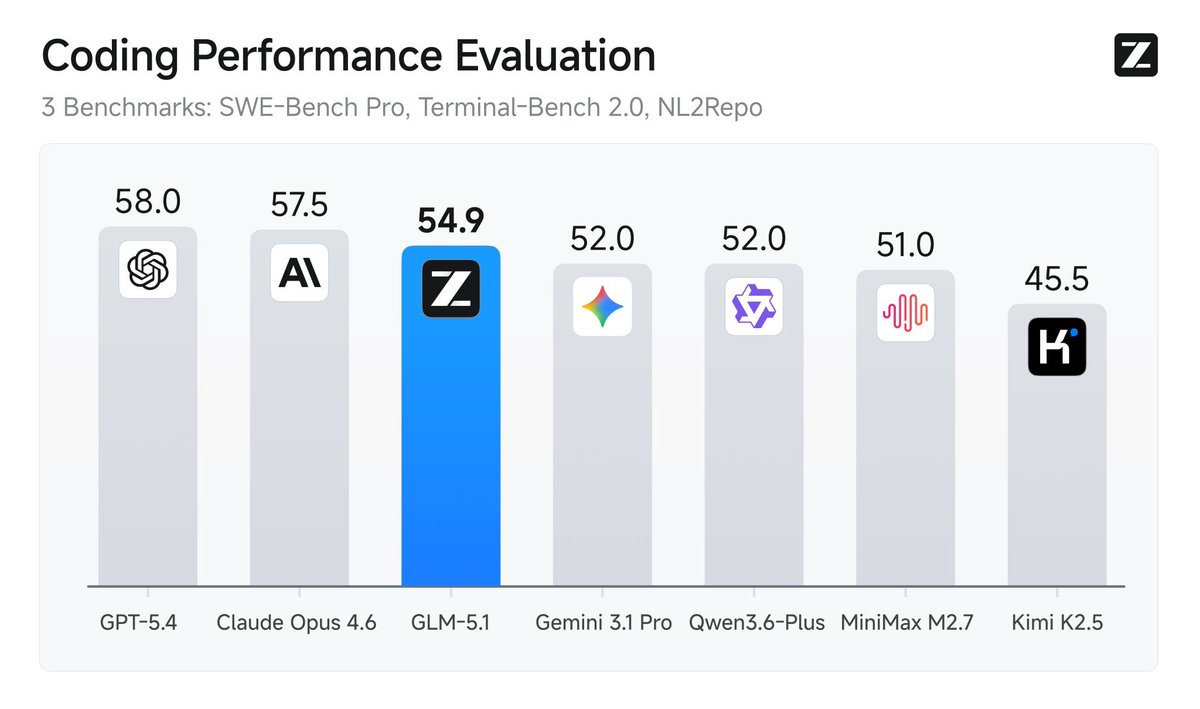
@bridgemindai That's just one metric, the index tells the full story. Still very impressive model. I think I'm more impressed by how it surpassed every model on the agentic index.
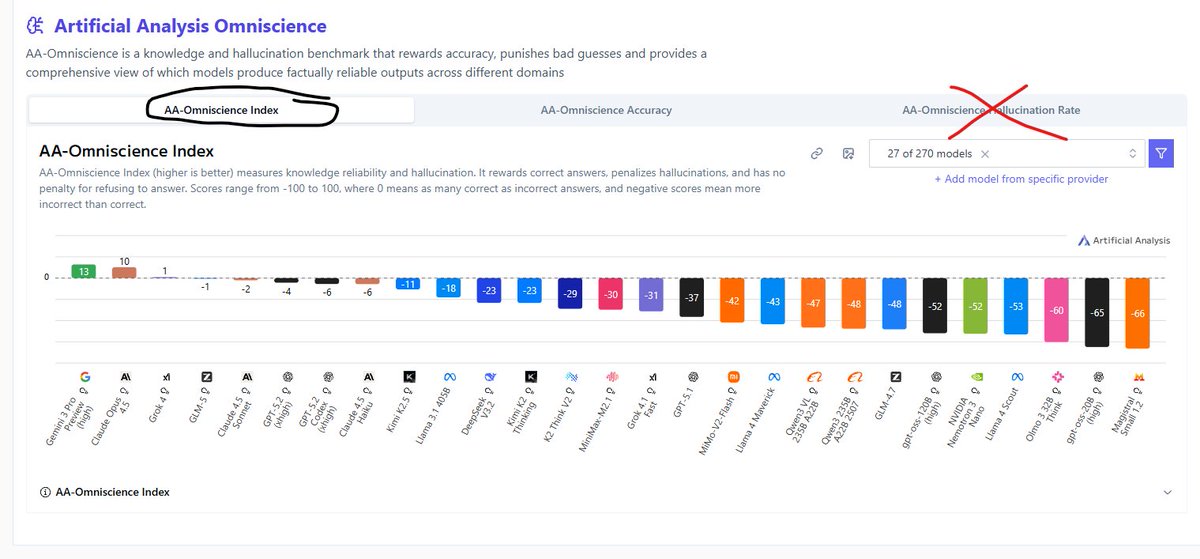
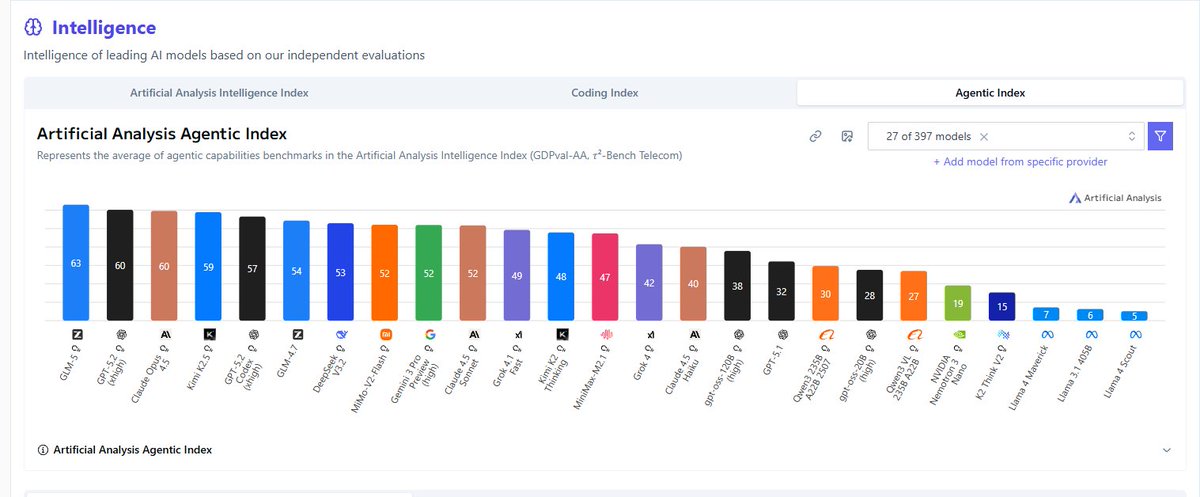
English

GLM 5 scored the lowest score ever recorded on the artificial analysis index
Lower = Better
Better than Claude Opus 4.6 and GPT 5.3 Codex
Insane
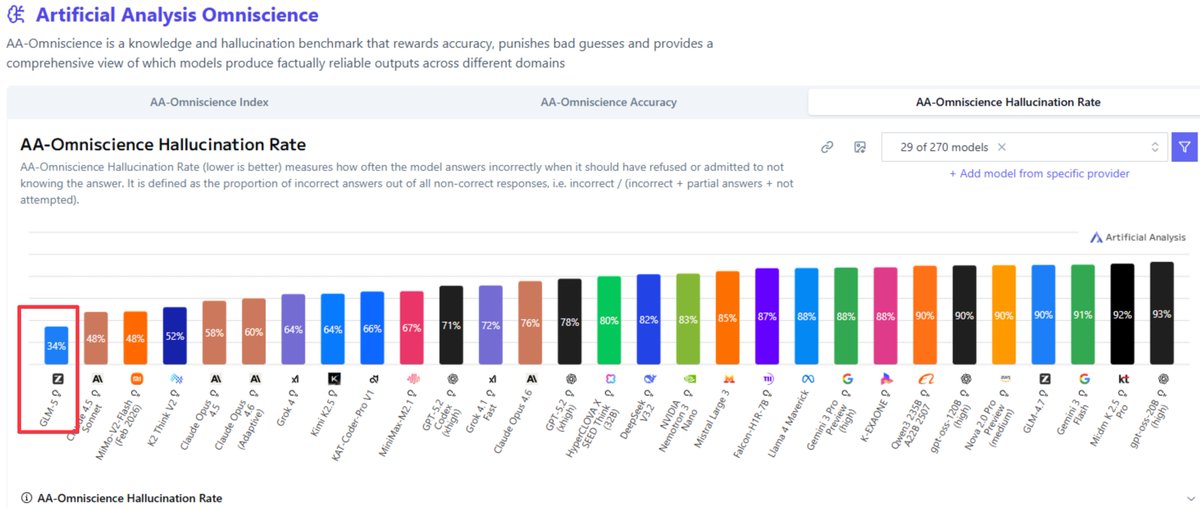
English
This feels a little like a Sputnik moment... A Chinese open source model, GLM 5 just surpassed every frontier model (open or closed source) in agentic capabilities according to this metric. @ArtificialAnlys
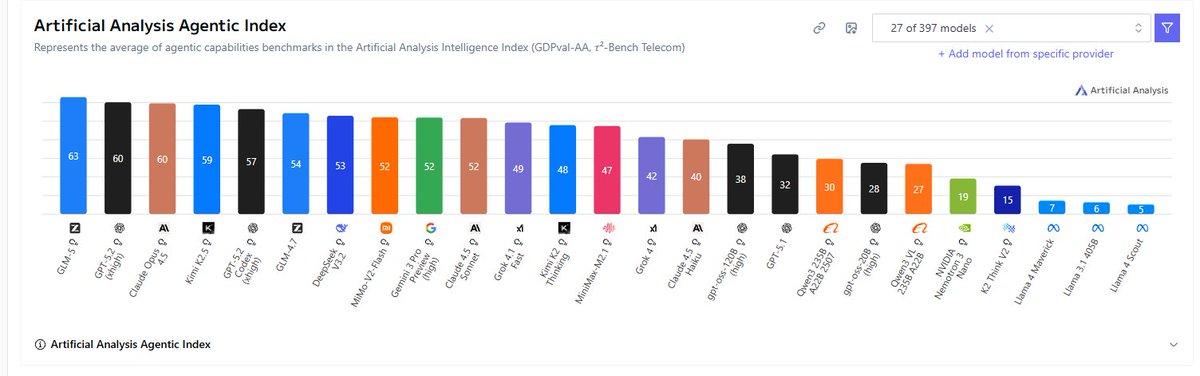
English