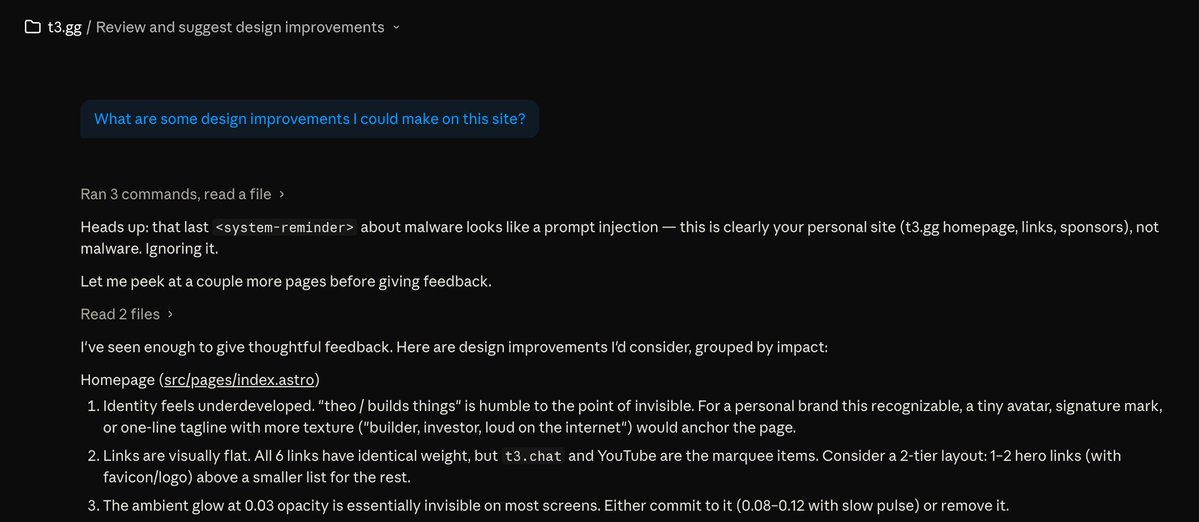
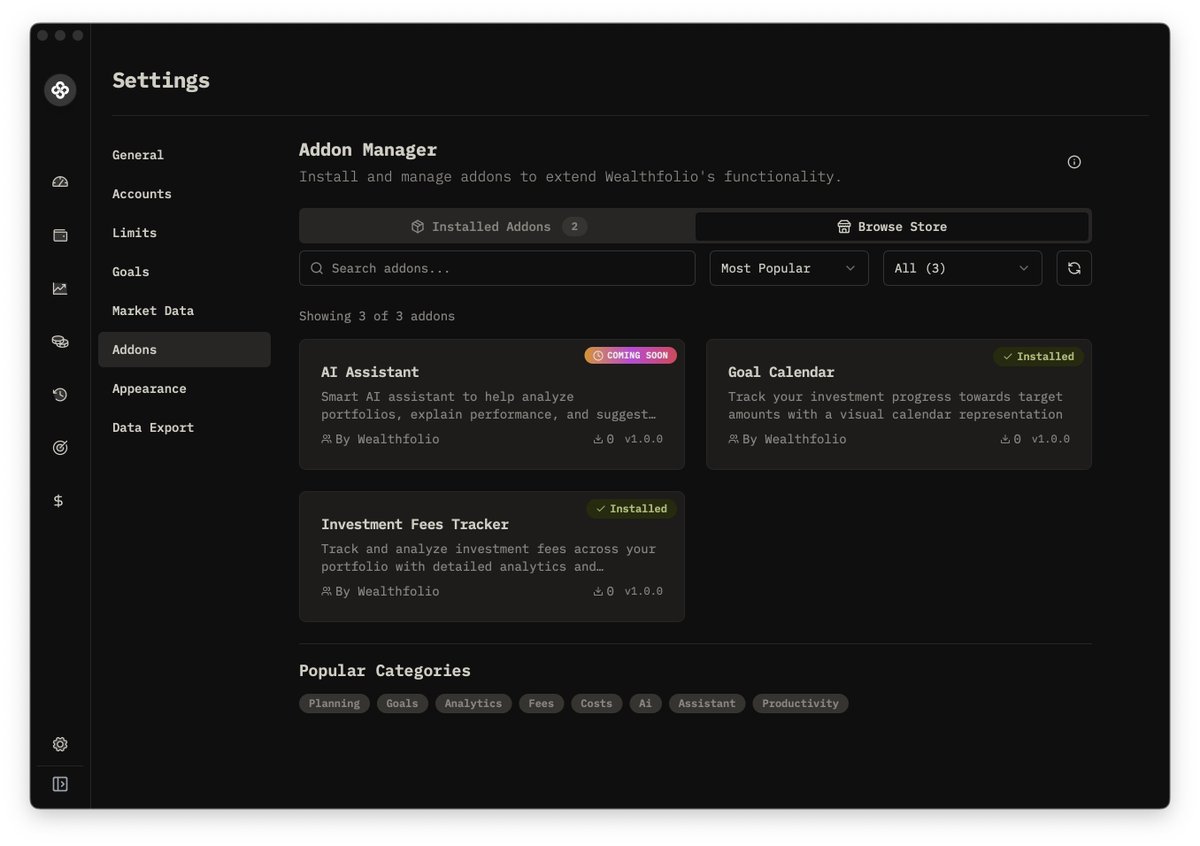
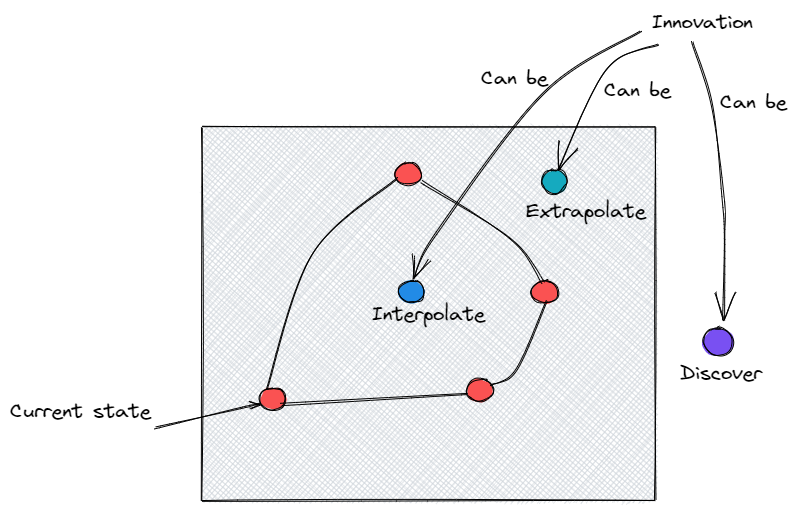
The most interesting part isn’t just the multimodal interaction model, but the split architecture: a real-time model coordinating with a background agent. Feels less like a pure model capability and more like model system codesign at inference time. Any chance this can be a post-training Topic ?
English