Sabitlenmiş Tweet

Nathaniel Daw
2.3K posts

@nathanieldaw
Princeton neuro prof. But Twitter is an absurd platform for professional communication so I strive to use it most unprofessionally.

Just talked with a well-respected computational neuroscientist friend. The situation in academia outside CS is sad. Everyone is fighting over a shrinking pool of grants. And it's happening exactly when there's more money in AI than ever. There are so many companies that say they are going to solve diseases. Any researcher at {your favorite frontier lab} can raise millions for a foundation model of biology or the brain, while the people who actually study biology and the brain can't fund their labs.
The 2026 volume of the Annual Review of Neuroscience is now online 🧠 The most read article is "Planning in the Brain: It's Not What You Think It Is" by @marcelomattar and @nathanieldaw bit.ly/4w3Nl23


YIMBYism promised to be the next big thing in progressive politics. But a couple of years after the PM declared himself a YIMBY, housebuilding has stalled, and YIMBYs have found themselves on the side of killing newts. Where did 'build baby build' go wrong? In my latest piece for @ArguablyMag, I argue that YIMBYs (which includes me) made three big mistakes: 🦇 1. We picked unnecessary battles we were bound to lose Attacking blockers, bats and newts is fine if you are trying to appeal to a niche Twitter audience who agree with you already. It is less smart, however, if the majority of voters are worried about more housing being built near them, and (quite rightly!) want to protect their natural areas. 🏡 2. We failed to prioritise homes where they are most needed. Hot take: not all of the UK faces a housing crisis. In fact, in most parts of Britain, a lack of connectivity is a far more binding constraint on productivity. Economically, the biggest benefits derive from densifying urban areas, and connecting these to other towns with good transport infrastructure, rather than building more satellite towns. 🤑 3. YIMBYs got into bed with big property developers. Developers prefer the kind of urban sprawl that economists, environmentalists and voters all hate: large, cookie-cutter newbuild developments, connected by roads, on greenfield sites. Instead of making YIMBYism about ordinary people who need homes, every conference event, panel and drinks reception ended up being a showcase for big developers. (NB my think tank, @BritishProgress, has never taken any money from property developers) The overall point: we failed to make Yimbyism win-win. The best argument for building more homes is that everyone can be better off: gentle density in urban centres, with good connectivity across the country, is politically popular, and the best thing Britain could do for growth. Andy Burnham should not give up on building more homes, but to succeed, YIMBYism needs a reset. Read the full piece here: arguably.uk/p/must-we-kill…
Why is it ‘cancelled’ in the U.K. but ‘canceled’ in the U.S.? Because we gave them that L in 1776.



Computational models are a key part of science but discovering new ones is hard! DataDIVER discovers concise models from data, surfacing new mechanistic ideas and generating clear predictions for future experiments Preprint from @GoogleDeepMind Neuroscience Lab + collaborators



While Alec is one of the best ML researchers of all time, LLM started way before. Here's one from 2013 for non-neural architecture and one from 2016, which is afaik the first neural LLM if we define LLM as LM w/ >1B params.


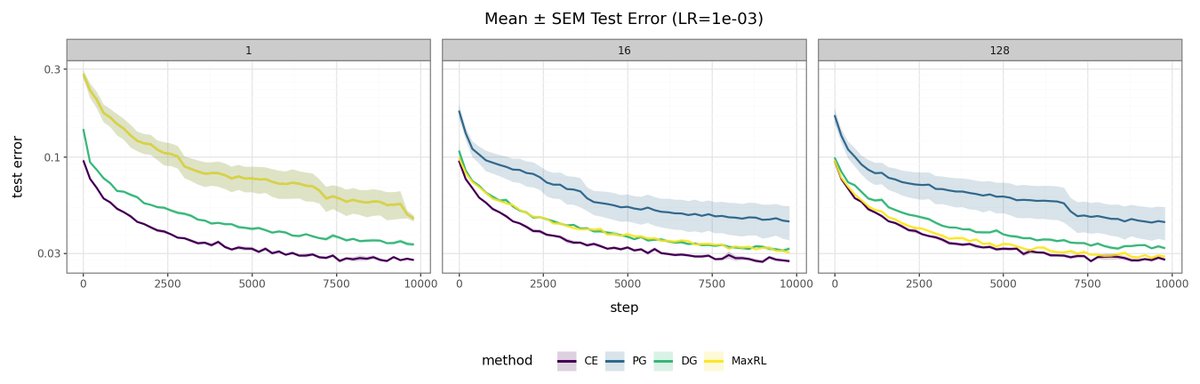
My "squinted" understanding of both MaxRL and DG is they essentially reweight TP/FP/TN/FN differently, such that learning converges to the same as xent, and both have a very nice classification "toy" example to make it very clear. So I'm genuinely very curious if they are exactly the same independent finding just phrased differently, or if they have some important differences, and if so what they are. That's why i was looking for such discussion either in DG's related works section, or in the thread here :)