
Natalia Bienias
1.7K posts
Natalia Bienias
@nbienias
Senior Product Designer | background in Product Design for enterprise products & mobile apps | former design lead
Amsterdam, The Netherlands Katılım Mayıs 2010
335 Takip Edilen448 Takipçiler

Fascinating how Google Search makes it hard to go to Google Maps since... some time (I don't know).
English

designers: what’s preventing you from making your apps look like this?
Sebastiaan de With@sdw
Love the Harkonnen holomap UI in Dune: Part Two.
English
@Maciej_Saja No z tym dobrym transportem publicznym to bym aż tak nie przesadzała – dużo zależy od tego w jakiej dzielnicy mieszkasz. Jak na zadupiu jak ja albo pod Amsterdamem to rower jest jedyną opcją żeby się móc gdzieś dostać. No i często zbiorkom nie przyjeżdża po prostu 😩
Polski

Jak wygląda modelowa miejska mobilność?
Tak, jak na filmie. Czyli dużo pieszych, rowerzystów i dobry transport publiczny.
W Amsterdamie to teraźniejszość. Kiedy przyjdzie pora na polskie miasta?
Polski
Natalia Bienias retweetledi

Za co przepraszał Zuckerberg⁉️
Czyli czym są silniki rekomendacyjne❓
Mój post z Zuckerbergiem przepraszającym rodziców oskarżających sieci społecznościowe o śmierć swoich dzieci, wzbudził duże zainteresowanie. Ale o co w tym wszystkim chodzi z technologicznego punktu widzenia?
W centrum całego sporu znajduje się klasa algorytmów, które nazywamy “silnikami rekomendacyjnymi”. Takie algorytmy towarzyszą nam w zasadzie od początku rozwoju Internetu. Są szczególnie lukratywne dla sieci społecznościowych, e-commerce i dużych wydawców treści. Bardzo często, gdy rozmawia się z osobami zawodowo zajmującymi się uczeniem maszynowym, wspominają, że kiedyś pracowały lub obecnie pracują przy rozwoju jakiegoś rodzaju silnika rekomendacyjnego. Jest tak dlatego, że odpowiednio zaprojektowany i wdrożony algorytm tego typu, może stać się dosłownie maszynką do zarabiania pieniędzy. Szczególnie dla graczy, którzy działają w gigantycznej skali: wielkie sieci społecznościowe (Facebook, Instagram, Twitter, YouTube, TikTok itd.) lub ogromne platformy sprzedażowe (Amazon, AliExpress, Allegro itd.).
W światku uczenia maszynowego krąży taka opowieść o pierwszym data scientyście (uczonemu od danych — do dzisiaj nie ma zgody jak tłumaczyć na język polski Data Science). Opowieść ta jest do pewnego stopnia legendą, ale nie o 100% prawdziwość tu chodzi, tylko o zilustrowanie pewnego zjawiska. Sieć społecznościowa LinkedIn została uruchomiona w roku 2002. Faktycznie, rejestrowali się w niej pierwsi użytkownicy i następował rozwój. Jednak właściciele zauważyli, że rozwój sieci kontaktów na ich platformie jest znikomy. Nowo zarejestrowani użytkownicy, nawiązywali znajomość z kilkoma osobami, a następnie aktywność ustawała, co wiązało się z tym, że platforma przestawała być atrakcyjna. Użytkownicy odchodzili.
Aby poradzić sobie z tym problemem, zatrudniono fizyka z doktoratem. Nikt nie miał do końca pomysłu, w jaki sposób miałby sobie poradzić z tym problemem, ale doktor fizyki był postrzegany jako osoba bardzo mądra. No więc nasz doktor chodził sobie po biurze LinkedIna, był ciekawski, zagadywał różnych pracowników, interesował się, czym się zajmują itd. W końcu, aby ożywić rozwój osobistych sieci użytkowników LinkedIn, zaproponował następujący mechanizm rekomendacyjny: jako nowych znajomych dla osoby A proponujcie znajomych jej znajomych. Jeżeli A zna osobę B i ta osoba B zna jeszcze osobę C, to zaproponujcie osobę C jako nową znajomą dla A. Taka zasada rekomendacji sprawiła, że LinkedIn zaczął się dynamicznie rozwijać. Faktycznie jeżeli przez chwilę o tym pomyślicie, to najczęściej waszymi nowymi znajomymi stają się osoby, które są znajomymi waszych znajomych. Zasada ta nosi nazwę “Zasady domykania triad” i dzięki temu prostemu mechanizmowi można skutecznie przewidywać ewolucję grafów społecznych. Z technicznego punktu widzenia, wystarczy, że w bazie danych znajdziemy te osoby, które są znajomymi A, a następnie znajdziemy wszystkie te osoby, które są ich znajomymi, a nie są znajomymi A. Gdy połączymy tę zasadę z szeregiem innych sygnałów (wspólnymi polubieniami, subskrypcjami itd.), to możemy skutecznie rekomendować nowych znajomych w sieci społecznościowej.
Jest to slajd z mojego wykładu w ramach Festiwalu Nauki z roku bodajże 2016. Nowe połączenie powstaje pomiędzy B i C, bowiem obydwa węzły mają wspólnego sąsiada A. Ten prosty mechanizm, leżący u podstaw rozwoju sieci społecznych, ma swoje konsekwencje: takie sieci są najczęściej mocno sklastrowane — istnieją grona gęsto połączonych węzłów z rzadszymi połączeniami pomiędzy klastrami:
Na tym slajdzie widać autentyczną sieć społecznościową (mój Facebook, 2016). Slajd również pochodzi z wykładu na Festiwalu Nauki.
Twitter jest trochę innym grafem — tzw. “grafem skierowanym”. Jeżeli ja followuję x, to nie koniecznie x followuje mnie. Znajomość jest tymczasem relacją symetryczną. Nie zmienia to jednak faktu, że na Twitterze też siedzimy w takich “paczkach informacyjnych” i nasze akcje wpływają na wzajemne rekomendacje. Przykładowo: jeżeli często wchodzę w interakcje z jakimś kontem x i followuje mnie y, który jeszcze nigdy nie wchodził w interakcje z x, to prawdopodobnie niebawem w swoim feedzie zobaczy rekomendację treści od y-a.
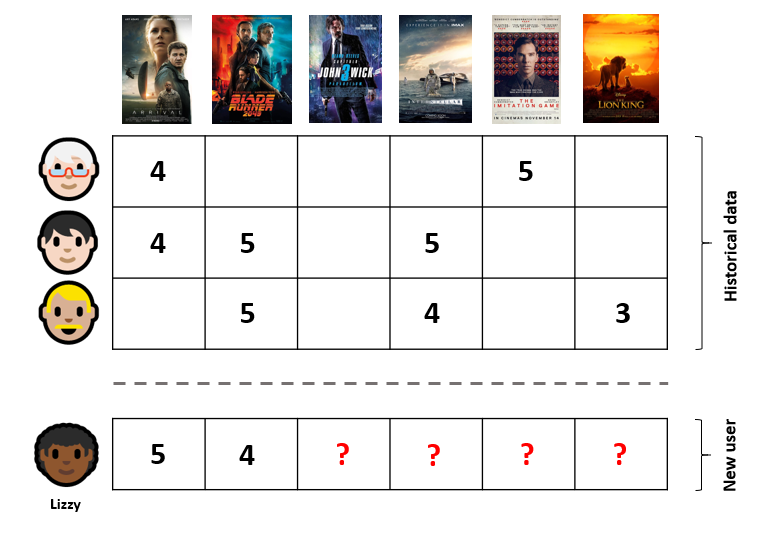
Innym, historycznym i znanym przykładem jest algorytm rekomendacyjny Netflixa. W roku 2009 Netflix ogłosił nawet konkurs, którego główna nagroda wynosiła 1MLN dolarów. Nagrodę otrzymał zespół, który opracował najskuteczniejszy algorytm rekomendacyjny na danych udostępnionych przez firmę. Upowszechnił się wówczas algorytm rekomendacyjny, który nazywamy filtrowaniem kolaboraywnym (ang. collaboration filtering, nie znam dobrego, polskiego przekładu). Złóżmy, że mamy bazę danych z filmami i użytkownicy oceniają obejrzane filmy. Wyobraźmy sobie gigantyczną tabelę, w której każdy wiersz reprezentuje użytkownika, a kolumny odpowiadają wszystkim filmom, jakie można obejrzeć w serwisie. W entym wierszu znajdują się oceny filmów obejrzanych przez entego użytkownika. Jeżeli enty użytkownik obejrzał “Okruchy dnia” i ocenił ten film na 5 gwiazdek, to w entym wierszu tabeli, w kolumnie odpowiadającej Okruchom dnia, znajduje się “5”.
W bazie mamy miliony filmów, w jaki sposób zaproponować użytkownikowi takie, które spodobają mu się z dużym prawdopodobieństwem? Jedna z metod polega na tym, że szukamy w tej tabeli wierszy, które są podobne do wiersza entego — innymi słowy, poszukujemy użytkowników, którzy oceniali filmy w podobny sposób jak enty użytkownik. Następnie bierzemy pod uwagę takie filmy, które one/oni ocenili wysoko, a enty jeszcze ich nie oglądał. Te filmy podpowiadamy w feedzie entemu.
To tylko uproszczona mikro-garstka koncepcji i metod stosowanych w silnikach rekomendacyjnych. Zamiast o filmach i innych osobach możecie myśleć o jakichś produktach w sklepie, artykułach na jakimś dużym portalu wydawniczym itd.; zamiast o gwiazdkach oceniających o kliknięciach, polubieniach, serduszkach … - każdy z tych sygnałów jest istotny z biznesowego punktu widzenia i odpowiednio go wykorzystując, można na nim zarabiać. Z czasem w domenie silników rekomendacyjnych zaczęto na masową skalę stosować uczenie maszynowe. Zadaniem modelu jest optymalizowanie pożądanych wskaźników (kliknięcia, włożenia do koszyka, kupienie, nowa znajomość, polubienie etc.) na podstawie behawioralnych i innych danych wejściowych.
Silniki rekomendacyjne od lat oddziałują na społeczeństwa poprzez różne serwisy. To za ich sprawą powstał termin “baniek informacyjnych”, w których tkwimy. Wiele badań stara się odpowiedzieć, jaki jest udział silników rekomendacyjnych w polaryzacji społeczeństw zachodnich, z którym mamy do czynienia obecnie.
Silniki rekomendacyjne — po osiągnięciu przez serwis odpowiedniej skali — stają się maszynkami do zarabiania pieniędzy. Największe biznesy BigTechowe są często osnute wokół jakiegoś silnika rekomendacyjnego. Nie widać cię w feedzie? Chcesz dotrzeć ze swoją ofertą do większej ilości użytkowników? Zapłać nam, a my w taki sposób zmienimy nasz algorytm, abyś stał się bardziej widoczny (Facebook, Twitter, Google). Złoty Gral każdego biznesu technologicznego: niech algorytm na nas zarabia, ewentualnie dokupujemy tylko moc obliczeniową.
Niektóre silniki rekomendacyjne są prawdopodobnie pierwszym przypadkiem niedopasowania (ang. missaligment), które ma swoje poważne skutki społeczne. Gdy trenujemy pewien system uczenia maszynowego, to musimy mu zadać pewne zadanie. To zadanie to jakaś nieznana funkcja, odpowiadająca np. za rozkład słów w języku (LLM) albo ilość polubień danego twitta. W czasie treningu nasz model ma coraz lepiej aproksymować (przybliżać się) do tej zadanej funkcji, nazywanej “funkcją celu”. Niedopasowanie polega na tym, że model ucząc się przybliżenia funkcji celu, może nauczyć się jej realizacji w sposób, który jest szkodliwy dla ludzi. Bardzo dużo mówi się obecnie o “missaligment problem” w kontekście LLMów, zapominając, że silniki rekomendacyjne oddziałują na nas od wielu lat, na masową skalę!
Algorytm optymalizujący kliknięcia w artykuł, może np. rekomendować artykuły, które mają sensacyjne tytuły, jest w nich wulgarny język itd. Eksploatuje pewne ludzie skłonności w celu optymalizowania zadania: maksymalizuj kliknięcia! W efekcie jakość informacji i dziennikarstwa obniża się (skąd to znamy?). Taki algorytm może wręcz zacząć rekomendować fake newsy!
Algorytm maksymalizujący czas spędzony w danym serwisie może np. wykorzystywać nasze skłonności/problemy psychologiczne. Osoba cierpiąca na hipochondrię klika w treści na temat chorób, a w efekcie silnik rekomendacyjny podpowiada jej jeszcze więcej treści o tej tematyce, co w efekcie prowadzi do stanów lękowych. (Przykład rzeczywisty, pochodzi od Fundacji Panoptykon, link w komentarzu).
Zgodnie z zeznaniami byłej pracownicy Meta, firma posiadała wiedzę o badaniach, które stwierdzały istnienie korelacji pomiędzy złym stanem psychicznym nastolatek, a ich skłonnością do followania kont modelek i influencrek na Instagramie. Nic jednak z tym nie zrobiła. Aby dobrze zrozumieć problem: silniki rekomendacyjne realizują pewne cele biznesowe firm technologicznych, ale coraz więcej wskazuje na to, że realizując te cele, pogarszają jakość życia swoich użytkowników. BigTechy są oskarżane o zaniechania na tym polu.
Z mojego osobistego punktu widzenia kwestia przejrzystości silników rekomendacyjnych powinna być priorytetem, jeżeli chodzi o jakiekolwiek regulacje prawne! To są systemy wywierające na nas realny wpływ od wielu lat. Szczególnie jest to istotne w przypadku platform skierowanych do dzieci i nastolatków. Czasami mam wręcz wrażenie, że ogniskowanie obecnej debaty na temat bezpieczeństwa AI wokół LLMów jest na rękę wielu przedstawicielom BigTechów, którzy większość zysków czerpią z rozwiązań reklamowych opartych na ich silnikach rekomendacyjnych. Najistotniejsze zagadnienia związane z bezpieczeństwem AI, to zagadnienie silników rekomendacyjnych i ich wpływu na społeczeństwo, a nie możliwość wyłonienia się szerokiej sztucznej inteligencji z LLMów.



Polski

@ArturJanczak @michal_osinski To, jedyne co mi pomagało pod warunkiem, że wzięte jak tylko bóle się zaczynają 🙌🙌
Polski


Okej. Ibuprofen nie dał rady, łeb dalej napierdala.
Podejrzewam migrenę, bo nic więcej mi się nie dzieje. Co bierzecie na migrenowe bóle głowy? Biorę po jednej tabletce od każdej drużyny i słucham państwa?
Polski
Natalia Bienias retweetledi

If your argument for whiteboard design challenges during interviews is “that’s how we work here, how much of the interview process up to that moment was you standing at the whiteboard?
It’s unfair to make the candidate be the first one to stand there and “show their thoughts."
English


💬 Ministra @AgaBak: Bardzo chciałabym, by w jak największej liczbie obszarów życia społecznego realizowane były przygotowania do wdrażania polityk na sposób polityki opartej na dowodach, takiej, która zanim opracujemy akt normatywny, systemowe rozwiązanie, będzie zakładała przeprowadzenie pilotażu, wyciągnięcie wniosków, wprowadzenie być może korekt do pierwotnych pomysłów. To w praktyce, codziennym funkcjonowaniu asystenta osobistego, osoby korzystającej ze wsparcia takiego asystenta, możemy tak naprawdę dowiedzieć się czy przedyskutowane, ustalone przez nas rozwiązania działają czy nie.

Polski
@uxuidesign @oykun This! We don’t talk enough about accessibility issues here 💀
English

@oykun It’s not just about making things look ‘cool’ it’s about making them intuitive, responsive and functional. The problem is that most of the sites you describe here are inaccessible to people with screenreaders.
English

Dear Designers,
Can we please calm down a bit?
Too many micro-interactions, animations and parallax effects everywhere now!!!
It feels like doing it for the sake of catching up with the trends with no meaningful purpose.
My 2015 MacBook Pro can't handle it just like most people's average computers.
It looks choppy as I scroll and fans are going nuts!
It distracts users in most cases from making sense of what the product is about.
Let's not sacrifice efficiency and meaning for the sake of following forced visual design trends.
Thank you
With love
✌️
English
@JakubNorkiewicz Nie wiem jak doświadczenia innych osób ale ja się zawsze jaram takimi rozwiązaniami, a później i tak wychodzi, że jedyne co wykorzystuje to ewentualnie poprawa/uladnienie/skrocenie tekstu 💀
Polski

Prezentacja w 60 sekund? Nic prostszego.
Od szkicu, przez tekst, aż po obrazki. Terminy w pracy lub szkole gonią?
To zapraszam na krótki tutorial 🧵
Polski
@krzysztofmmaj Moje ulubione to inwentarze i ich obsługa 😶🌫️Boli, że nawet dobre gry mają głupie babole – ostatnia Zelda i wyświetlanie listy questów choćby 😅
Polski

2023 jest ciekawym rokiem.
Genshin Impact dostaje w wersji 4.3 usprawnienia UX-owe, podczas gdy interfejsy gier AAA dalej leżą gdzieś w pomrokach 1997 roku, od Diablo 4 po (niestety) Baldura Gate 3 czy nowego Avatara.
Potrzebujemy badań UX-owych w gamedevie jak nigdy dotąd.
Polski


Natalia Bienias retweetledi

@amalenstwo Ooo to spróbuj „tofu zmieniające życie” czy coś w te deseń od wspomnianej jadlonomii – doskonale się ta chrupiąca skórka z gęstym sosiwem łączy 🖤
Polski

Kurde dlaczego nikt mi wcześniej nie powiedział, że tofu obtoczone w mące i usmażone na oleju, to taka przepyszna rzecz!!!
Polski
@GergelyOrosz Yass. My fav a few days ago was a screen with data for a traditional bank transfer (I had a problem with other payment types because the ING app in NL is no better 😅) with just listed mixed data (my and KLM) and a BLOCKED option for text copy 🤡 (and no alternative to copy it).
English

The KLM app is an example of what happens when a corporate becomes a “not my problem” kind of company, devs focused on their assigned task, nothing more.
This is the screen I get when I hit log in in the native app. It’s an unhandled 403 HTML page (??).
Such poor craftsmanship.


English
Natalia Bienias retweetledi

Wild to me to be rejected for an AI-related product design role without even having a conversation, because despite my 2-decade design experience, it doesn’t include AI.
Good luck to you to find that special designer that was either psychic 10 years ago or has a time machine.
Alameda, CA 🇺🇸 English
Natalia Bienias retweetledi


Natalia Bienias retweetledi

Przykład koszmarnego UX:
Czytam książkę o TOPRze w której wspomniano o aplikacji "Ratunek" tworzonej z @Plus_Polska . Choć przydatna i lubiana przez ratowników, ma jeden problem: dziesiątki fałszywych zgłoszeń wysyłanych przez użytkowników testujących aplikację w domach. 1/?

Polski
Natalia Bienias retweetledi

All these people lining up to do spec work for a billionaire is the most cringe I’ve ever felt on this app.
English