Nagesh C retweetledi

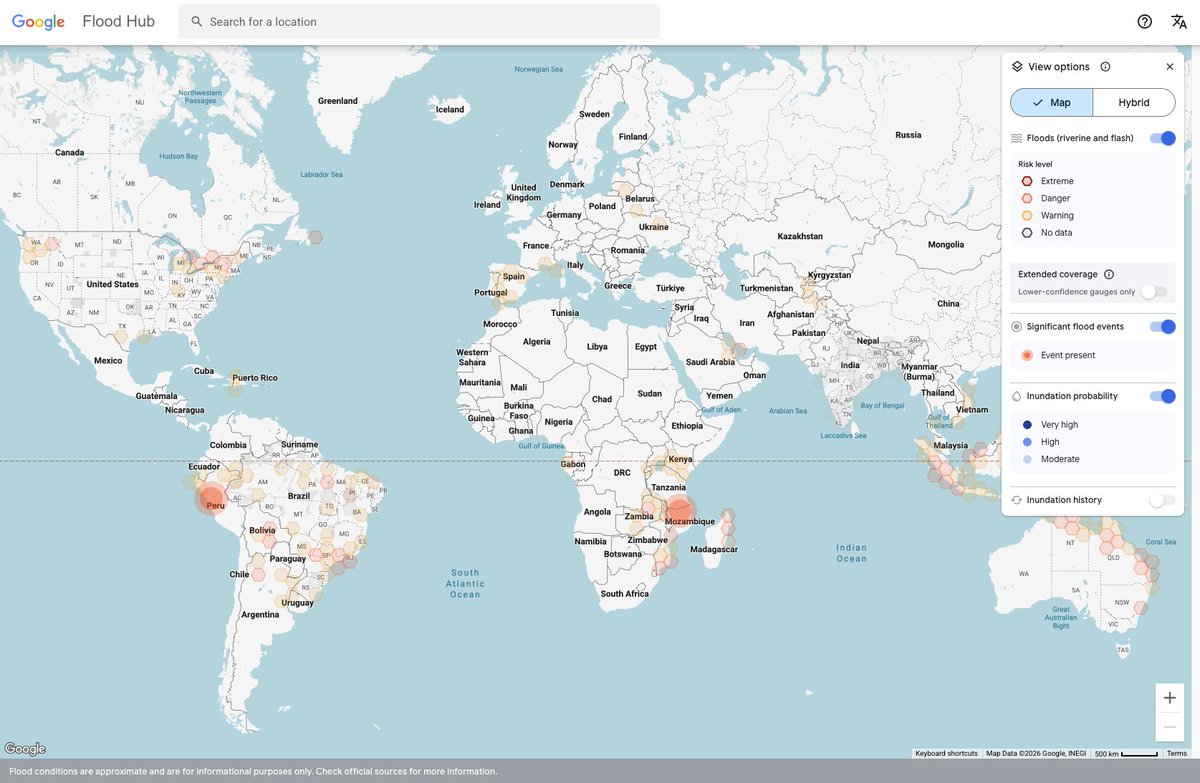
Try to remember this as you get older - advice from one of the greatest thinkers of all time
English
Nagesh C
2.2K posts

@nchintada
Work: DevOps. Product Development. System Architectures. Leadership. Management. Fun: Travel, Photography, Robotics, Arts, Sports, Music





The famous SFFA case treated Indians and East Asians as a single group. This masked significant heterogeneity: It's way harder to get in if you're Indian! In Columbia's internal admissions database (h/t @cremieuxrecueil), East Asian applicants had a 41% lower odds of admission than equally qualified White applicants, whereas South Asian applicants had 63% lower odds.

Dennis Ritchie created C in the early 1970s without Google, Stack Overflow, GitHub, or any AI ( Claude, Cursor, Codex) assistant. - No VC funding. - No viral launch. - No TED talk. - Just two engineers at Bell Labs. A terminal. And a problem to solve. He built a language that fit in kilobytes. 50 years later, it runs everything. Linux kernel. Windows. macOS. Every iPhone. Every Android. NASA’s deep space probes. The International Space Station. > Python borrowed from it. > Java borrowed from it. > JavaScript borrowed from it. If you have ever written a single line of code in any language, you did it in Dennis Ritchie’s shadow. He died in 2011. The same week as Steve Jobs. Jobs got the front pages. Ritchie got silence. This Legend deserves to be celebrated.


@poe_collector The opener from The Newsroom was relevant when it came out and even MORE relevant today sadly. 😞

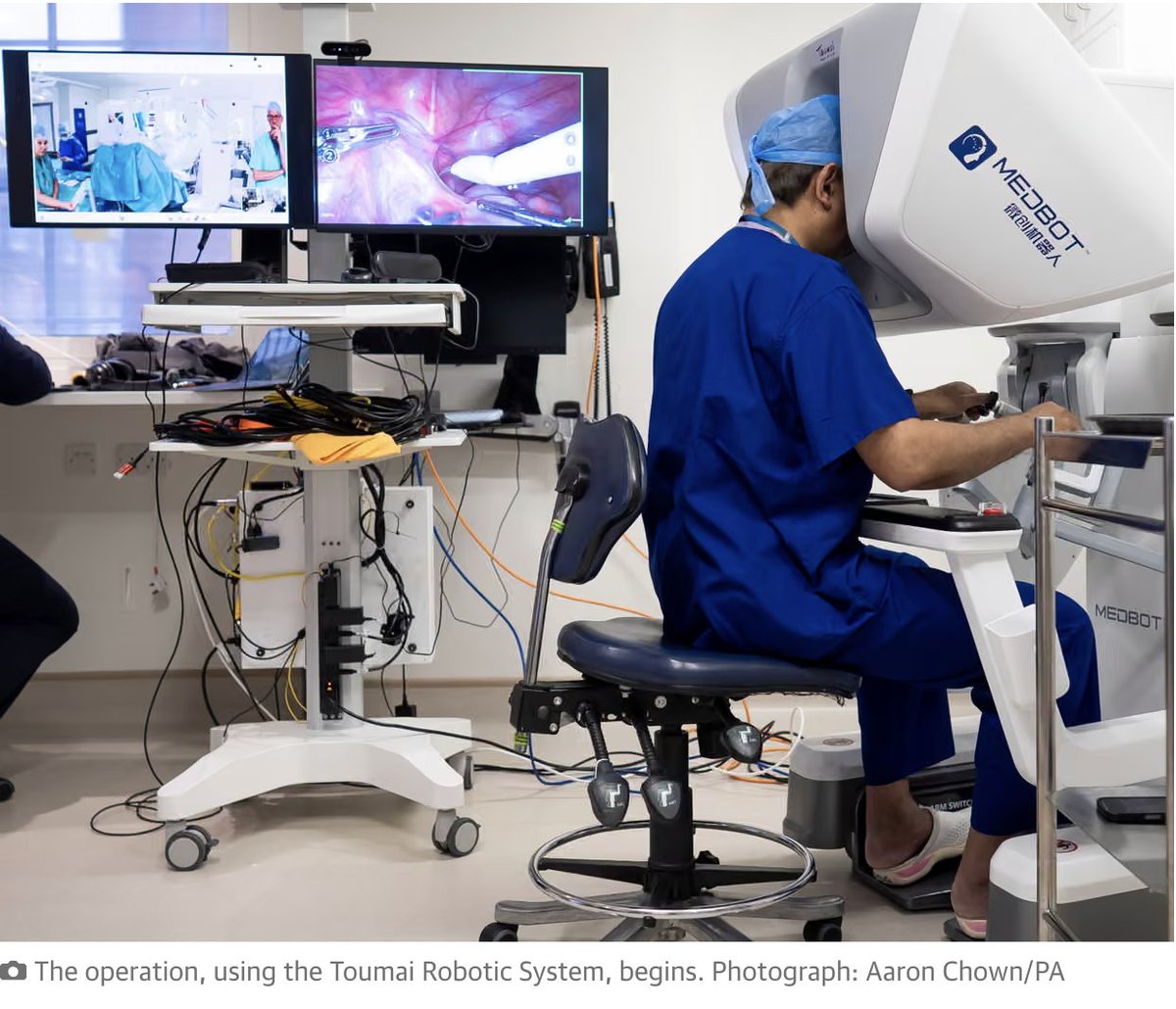


𝐀𝐬 𝐩𝐚𝐫𝐭 𝐨𝐟 𝐭𝐡𝐞 𝐨𝐧-𝐠𝐨𝐢𝐧𝐠 𝐀𝐈 𝐏𝐨𝐥𝐢𝐜𝐲 𝐖𝐡𝐢𝐭𝐞 𝐏𝐚𝐩𝐞𝐫 𝐒𝐞𝐫𝐢𝐞𝐬, 𝐭𝐡𝐞 𝐎𝐟𝐟𝐢𝐜𝐞 𝐨𝐟 𝐭𝐡𝐞 𝐏𝐫𝐢𝐧𝐜𝐢𝐩𝐚𝐥 𝐒𝐜𝐢𝐞𝐧𝐭𝐢𝐟𝐢𝐜 𝐀𝐝𝐯𝐢𝐬𝐞𝐫 𝐭𝐨 𝐭𝐡𝐞 𝐆𝐨𝐯𝐞𝐫𝐧𝐦𝐞𝐧𝐭 𝐨𝐟 𝐈𝐧𝐝𝐢𝐚 𝐫𝐞𝐥𝐞𝐚𝐬𝐞𝐬 𝐚 𝐰𝐡𝐢𝐭𝐞 𝐩𝐚𝐩𝐞𝐫 𝐨𝐧 “𝐀𝐝𝐯𝐚𝐧𝐜𝐢𝐧𝐠 𝐈𝐧𝐝𝐢𝐠𝐞𝐧𝐨𝐮𝐬 𝐅𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥𝐬. The versatility of Foundation Models makes them a critical layer of today’s AI ecosystem and a key area for innovation in India. Therefore, developing indigenous foundation models is a strategic priority. India’s objective is to harness foundation models for inclusive growth and public good, while ensuring they are governed in a manner consistent with the country’s values, legal framework, and security interests. This white paper provides an understanding of India’s approach to advancing indigenous foundation models through public–private collaboration and to governing these systems that support trust, accountability, and responsible adoption. The White Paper also provides details on India’s approach - which is centred on building indigenous capability across the foundation-model stack. Rather than relying on a single model, India is developing an ecosystem that combines (i) shared compute access, (ii) India-centric data and model repositories, and (iii) multiple model-building efforts across text, speech, multimodal, and sectoral systems. Read the White Paper here: psa.gov.in/CMS/web/sites/…



Musk admits xAI 'not built right' — weeks after Tesla invested $2 billion electrek.co/2026/03/13/elo… by @fredlambert

holy shit Meta might ditch ai efforts and go with google gemini instead Meta to delay their new AI model launch and use gemini to power Meta AI - HUGE fucking win for google: - Meta's avocado model underperformed frontier models from openai, google and anthropic (shitty reasoning, coding etc) - this comes after Meta spent $20B hiring a new AI team thats produced... no ai models. - looking at licensing google gemini (google just licensed to Apple for $1B per year) Google is fast-becoming the preferred model for the largest companies in the world. Meta has 3.6 BILLION MAUs if this happens google will single-handedly have the largest AI distribution of any company.