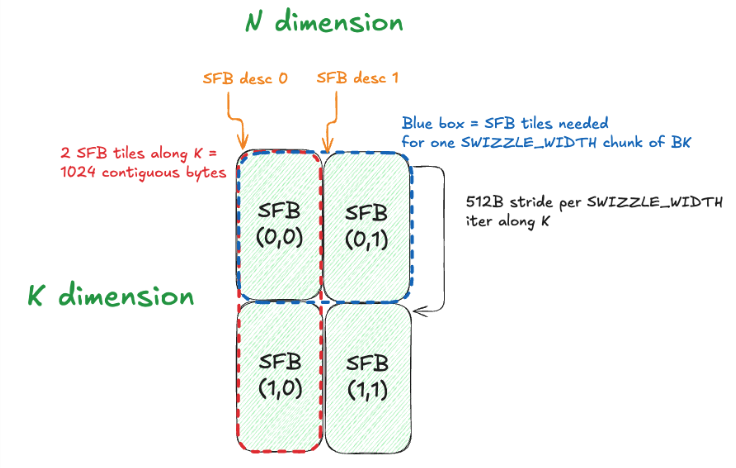
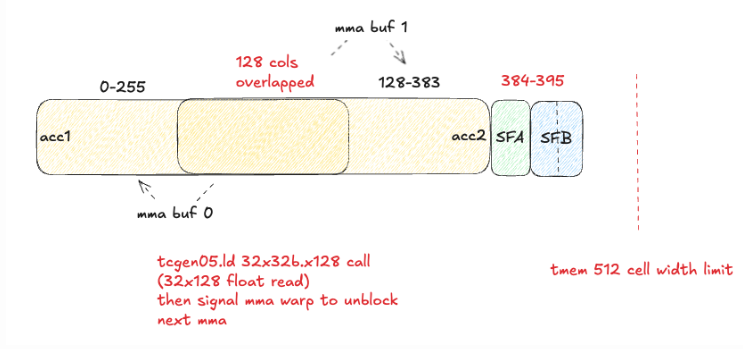
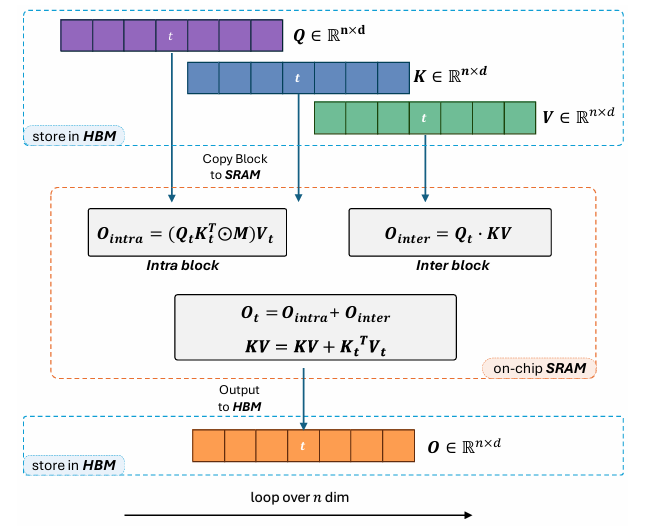
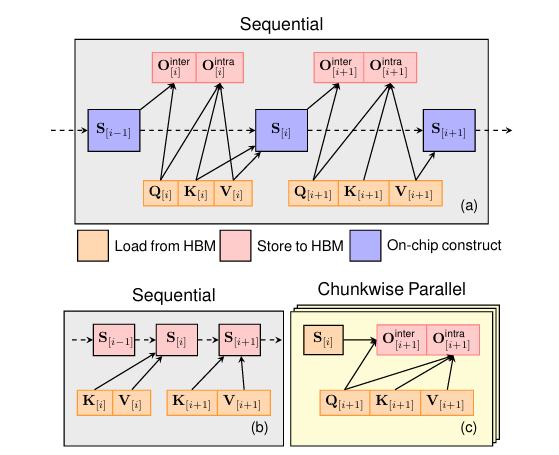
Sabitlenmiş Tweet

This repository is a public log of my learning, experiments, and projects as I dive deep into:
- GPU architecture
- CUDA programming
- Memory hierarchies
- Parallelism
- Acceleration for deep learning and scientific computing
github.com/bikrammajhi/10…
English