Sabitlenmiş Tweet

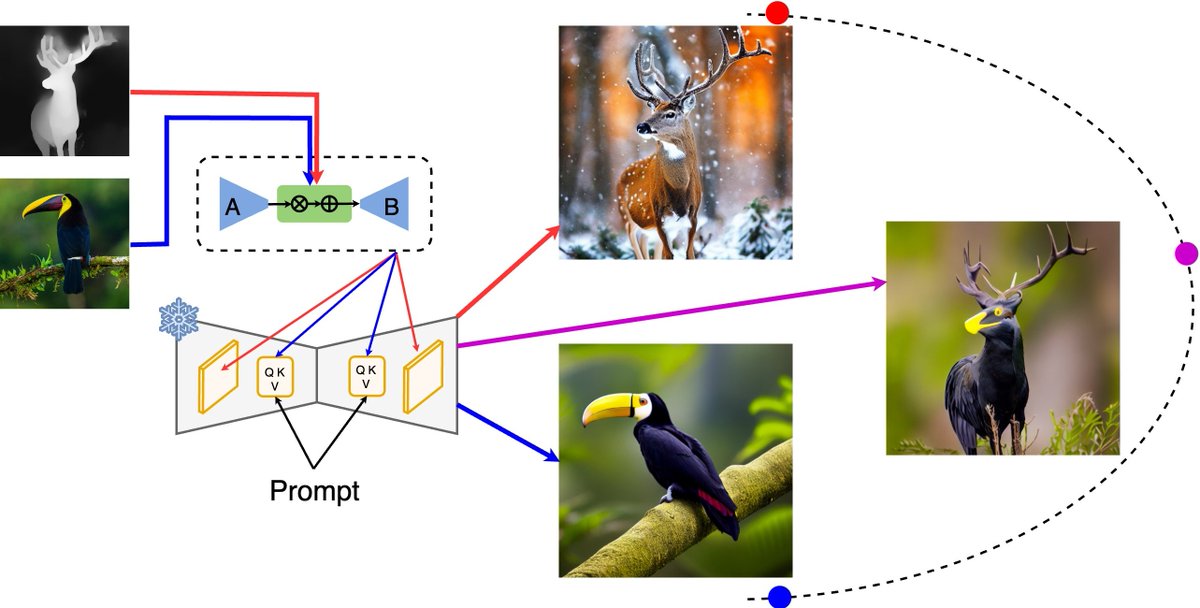
Can we condition LoRAs to use their great performance for 0-shot adaptations? 🤔
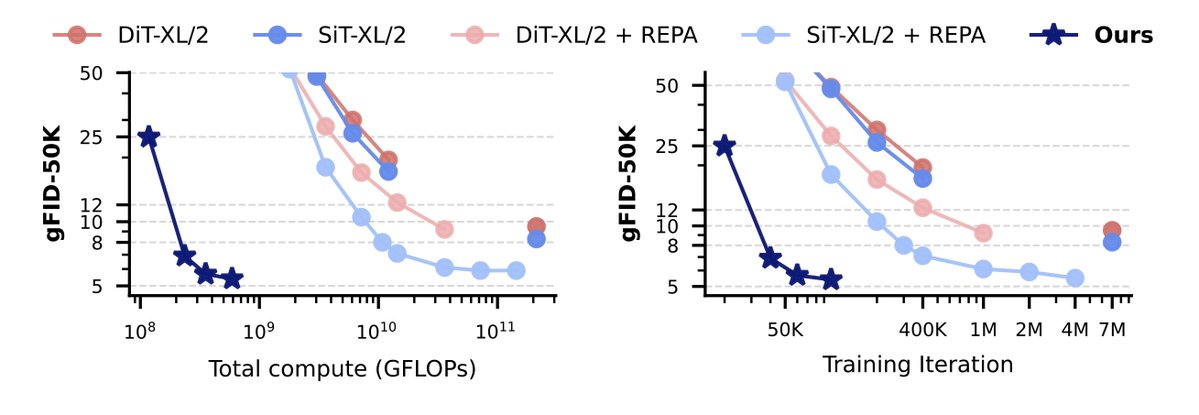
So far, LoRAs have been used extensively but their adaptions remain static after training.
We introduce LoRAdapter: efficient and flexible conditioning of LoRAs, which we validate on SD.
🧵👇

English