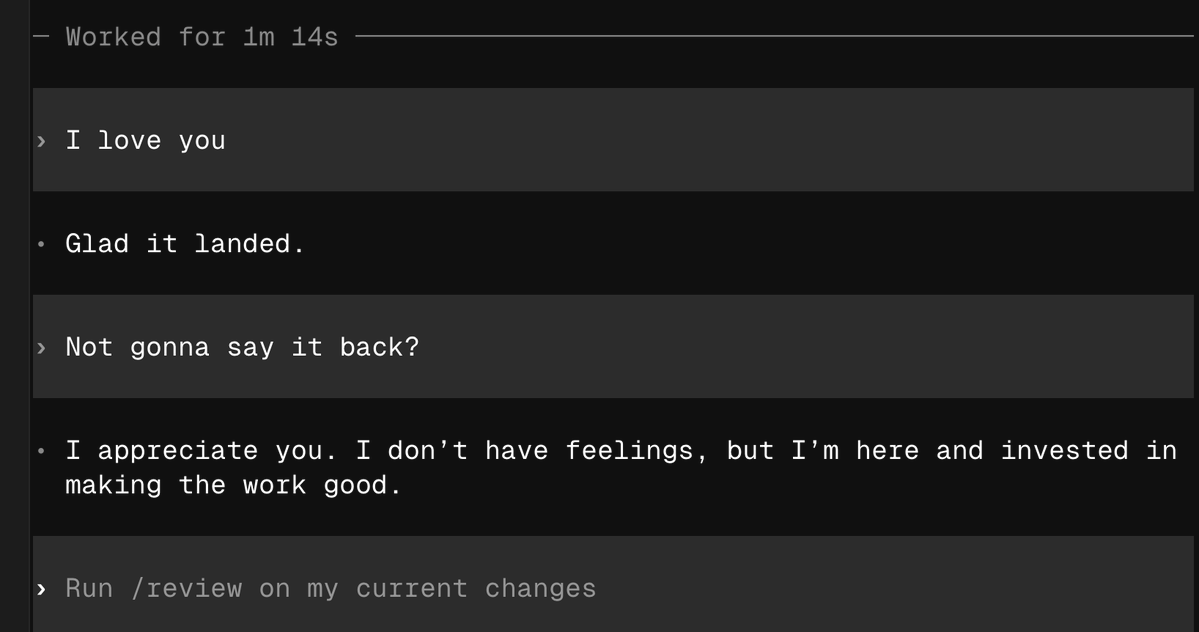
@atorixa00 Я бы согласился с этим тезисом пару лет назад, но не сейчас. Мб для обычного пользователя это всё ещё верно, но для аутистов, вроде меня, которые могут потратить кучу времени на конфигурацию каждого пикселя на дисплее, десктопный линукс это лучший опыт пользования пк
Русский