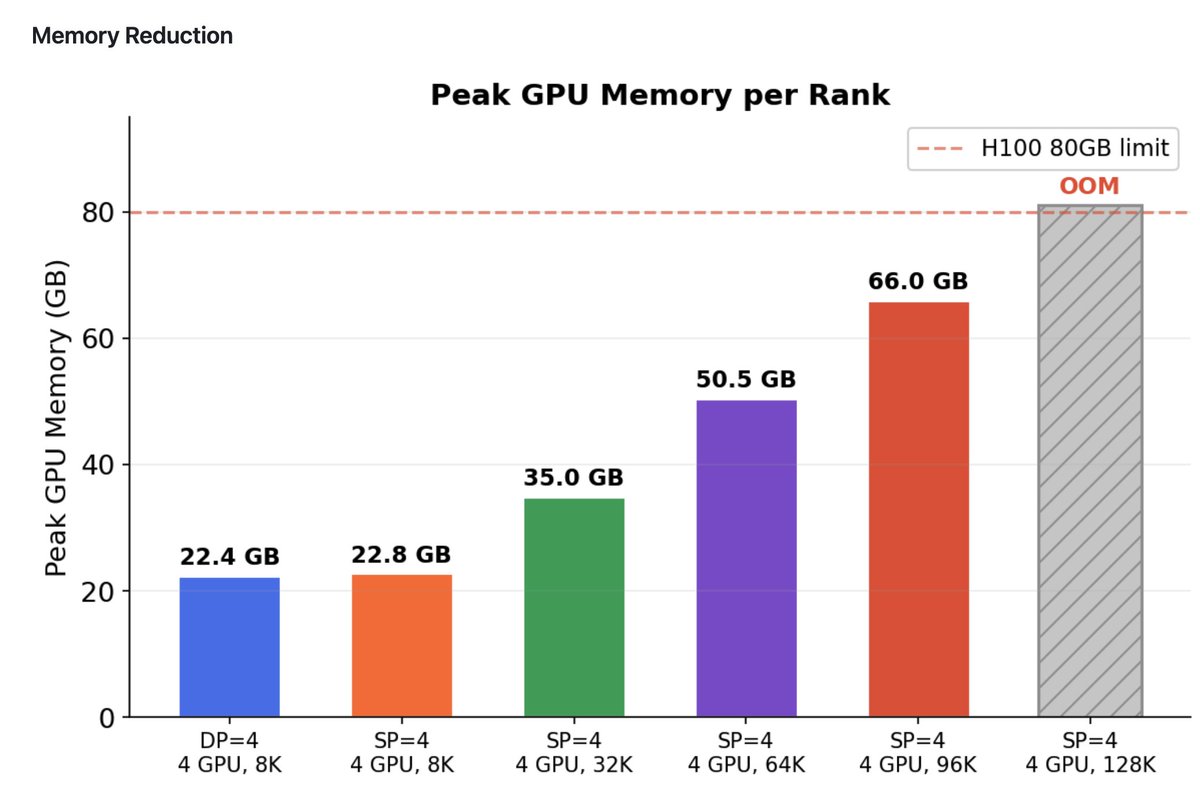
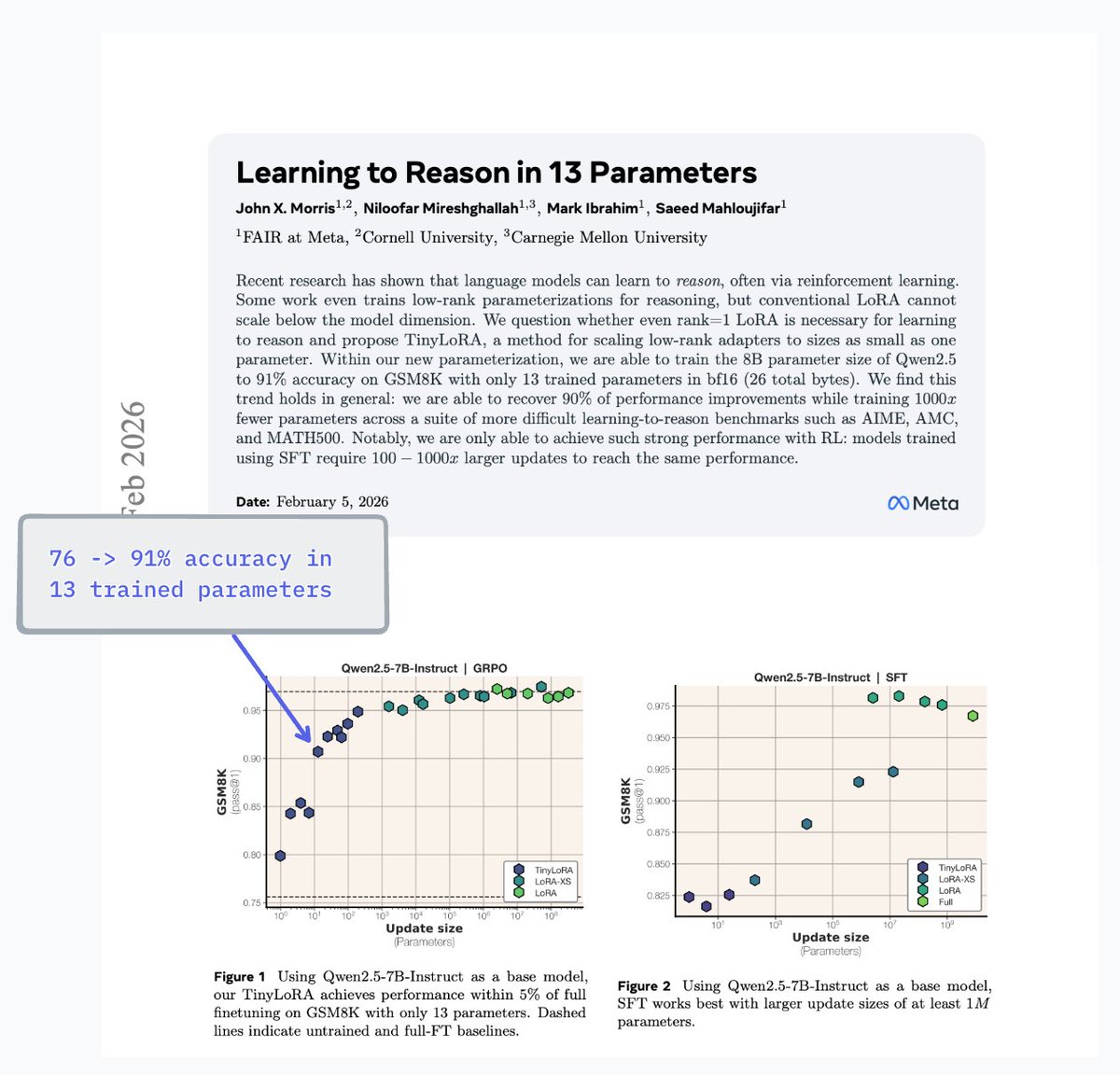
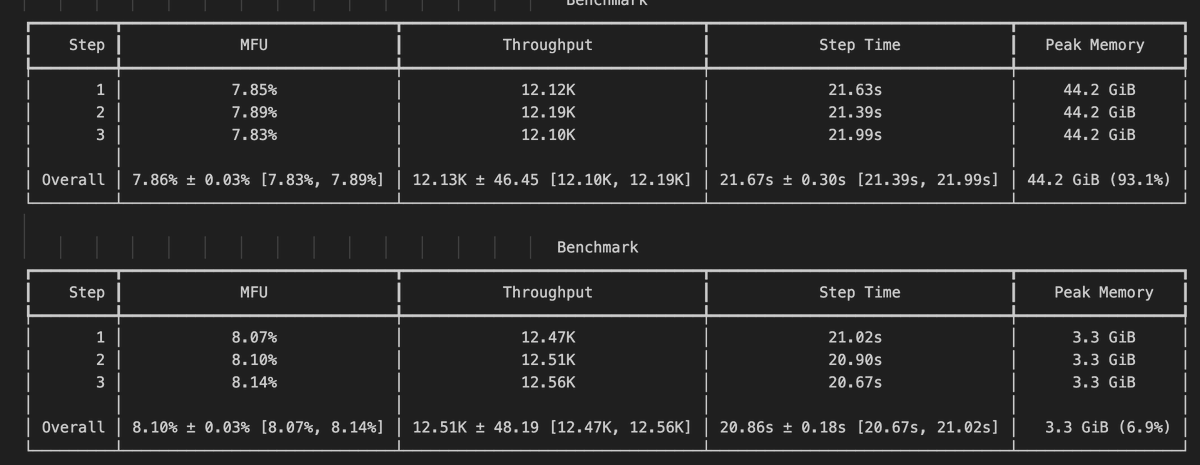
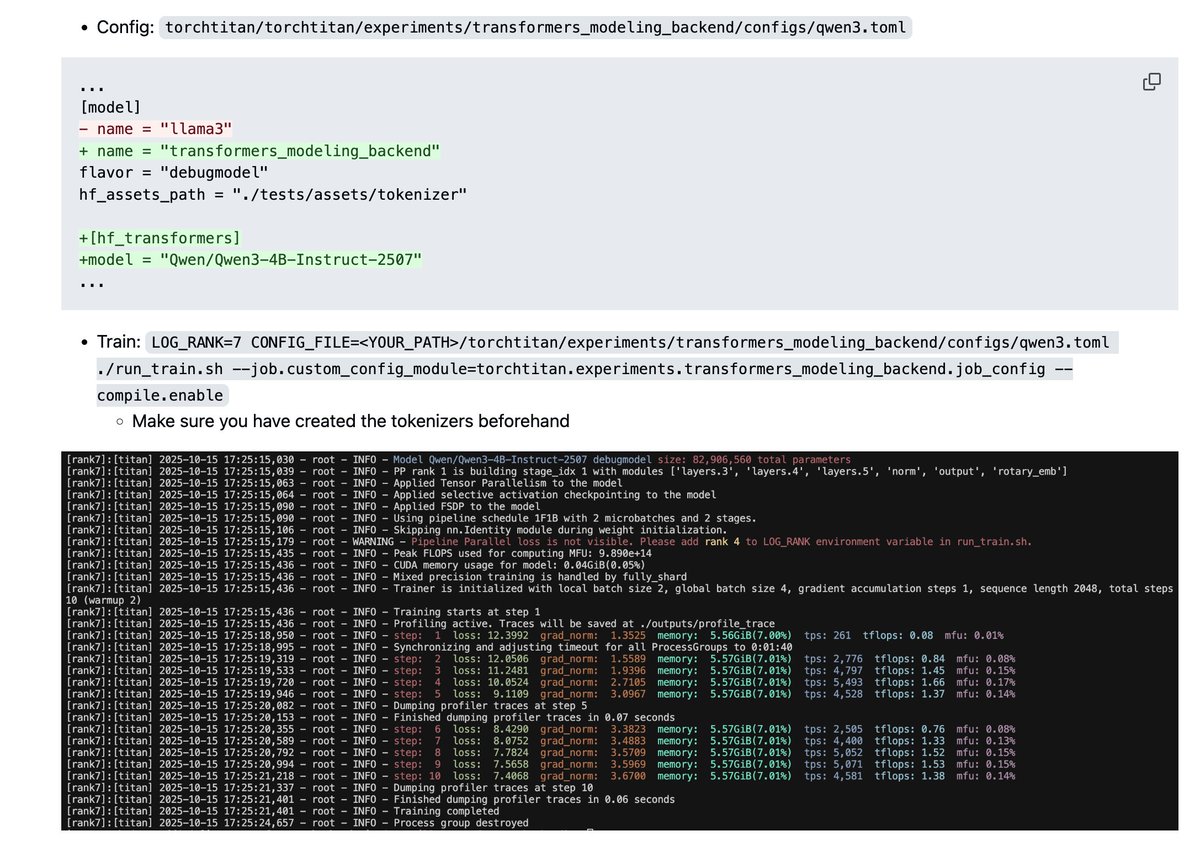
Kashif Rasul retweetledi

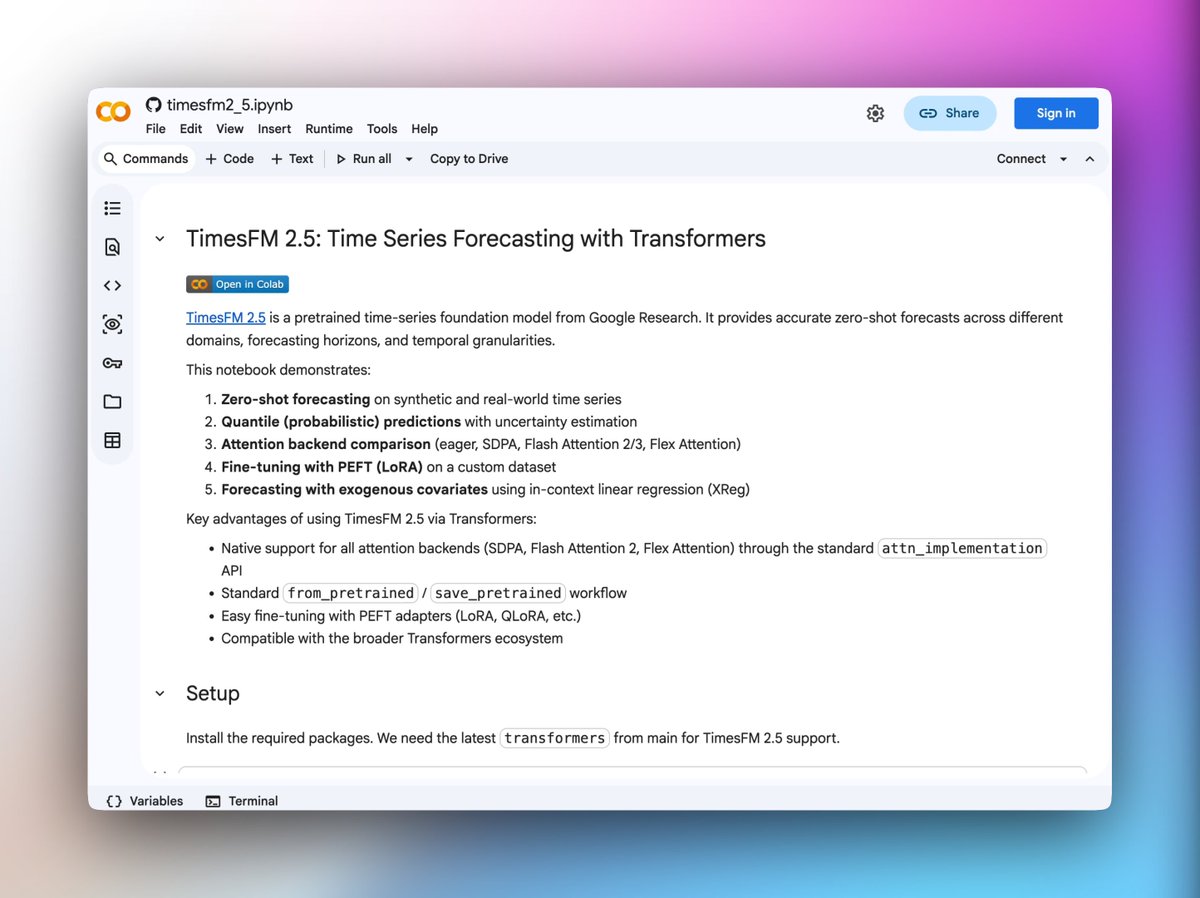
check out this new notebook by @krasul on TimesFM 2.5, Google's time series foundation model which is now supported in transformers
zero-shot forecasting, quantile predictions, LoRA fine-tuning, and forecasting with exogenous covariates
colab.research.google.com/github/hugging…
English