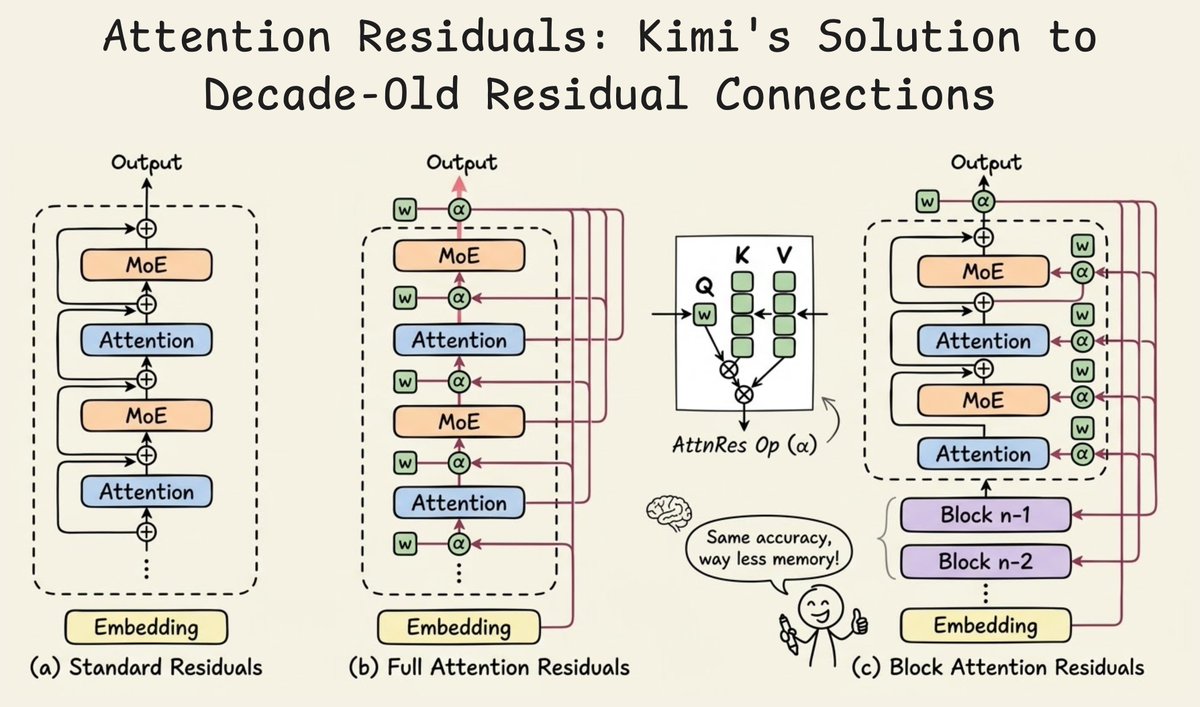
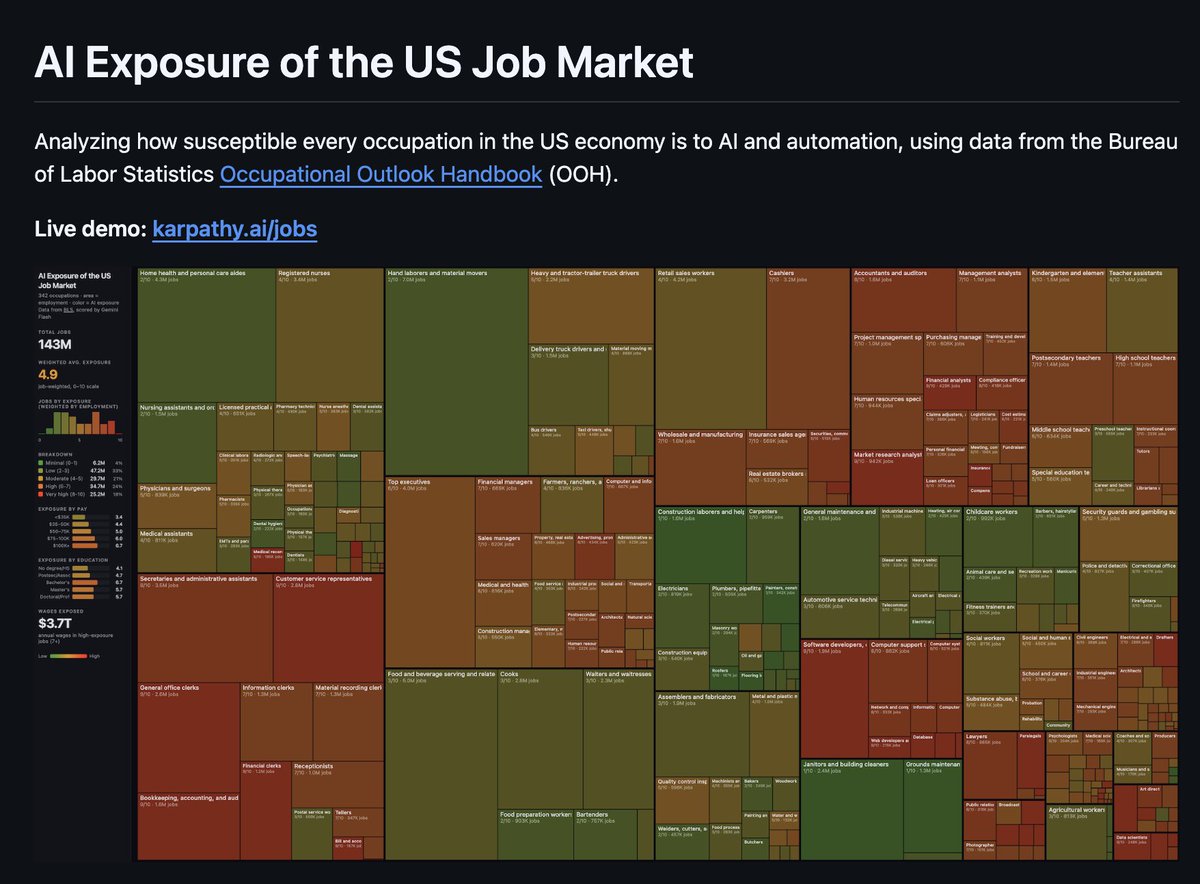
Sabitlenmiş Tweet

Find a problem (hopefully a massive one) you are uniquely capable of solving, give it your all and let compounding do its trick in the long run. And build a future you'd want to live in with your own hands.
Tom Butler-Bowdon@tombutlerbowdon
"Work on problems nobody else is working on, especially if you’re uniquely capable of solving them." @david_perell summing up worldview of @peterthiel
English