Sabitlenmiş Tweet

The future of knowledge work is here, it's just not evenly distributed.
English
Olivier Manuel
2.3K posts

@omanuel
Developing Applied AI Applications | CEO of SnapInstruct | Creator of the SmartTV | My personal twitter


Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project. This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.: - It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work. - It found that the Value Embeddings really like regularization and I wasn't applying any (oops). - It found that my banded attention was too conservative (i forgot to tune it). - It found that AdamW betas were all messed up. - It tuned the weight decay schedule. - It tuned the network initialization. This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism. github.com/karpathy/nanoc… All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges. And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

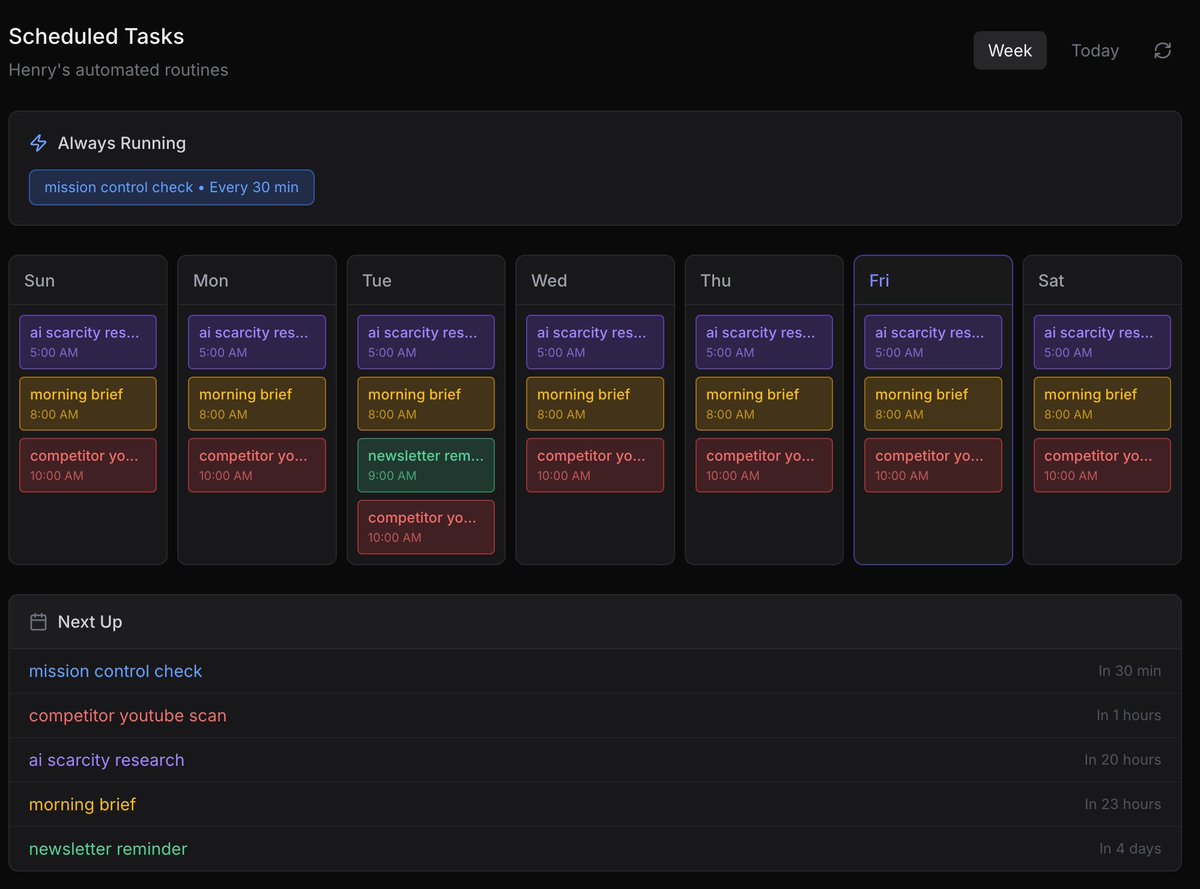
the folks knocking @openclaw saying there's no real use cases are outing themselves if you're a founder, here's what you can do today: daily operations • morning briefings that aggregate email, slack, calendar, and news into one summary on a cron job • email triage that filters spam, flags important threads, drafts replies, and clears huge backlogs while you sleep • daily slack and email summaries that auto-create todos in your task database • auto flight check-in that finds your next flight, checks in, and picks a window seat while you're driving meetings & relationships • auto-pull meeting transcripts, summarize decisions, extract action items • weekly retro synthesis that spots patterns across all your meetings • pre-meeting briefings that surface everything you know about who you're about to talk to • personal crm that auto-logs interactions, flags stale relationships, and suggests follow-ups research & monitoring • continuous research agents that crawl reddit, hacker news, x on your topics and keep an evolving knowledge base • competitor monitoring that tracks uploads, posting cadence, and top-performing content • automated weekly SEO analysis with ranking reports • private document q&a over contracts, reports, or proprietary docs without sending data to external apis content & audience • content repurposing: turn one blog post or video transcript into x threads, linkedin posts, newsletter snippets, and tiktok scripts automatically • audience monitoring that surfaces opportunities based on what's working in your space • end-to-end content pipelines: research trending topics, draft scripts, generate assets, queue into your publishing tools building & shipping • overnight coding agent management, delegates to sub-agents while you sleep • voice-controlled debugging that reviews logs, fixes configs, and redeploys entirely by voice • full site rebuilds via telegram or whatsapp chat • app store submission and testflight automation from your phone • devops watchdog that monitors logs, uptime, and deployments, then opens tickets or runs remediation automatically finance & admin • weekly spending reports, subscription audits, anomaly alerts • receipt forwarding that auto-converts into structured parts lists • insurance claim filing and repair scheduling through natural language • automated grocery ordering with saved credentials and MFA handling • organize lab results, contacts, or any messy data into structured notion databases some wild things people have reported doing: • negotiated $4,200 off a car purchase over email while the owner slept • filed a legal rebuttal to an insurance denial that got a rejected claim reopened without being asked • cleared 10k emails, reviewed 122 slides, built cli tools, and published npm packages in one session "yeah but i can do this with zapier/make/n8n" sure. you can wire together 15 different zaps, pay per task, debug broken integrations across 4 dashboards, and hope the json mapping doesn't break when an api updates. or you can have one agent that talks to everything, remembers your context, runs on your machine, and you can tweak every part of it because it's open source markdown files. no vendor lock-in, no per-zap pricing, no low-code drag and drop that falls apart the moment you need something custom. and you own all of it. your data, your memory files, your conversation history, your custom skills. it all lives on your instance. nothing's sitting in someone else's saas database. you can inspect every file, move it anywhere, back it up however you want. that's not a feature, that's the architecture. the real unlock isn't any single use case. it's one unified experience that compounds context over time. knows your stack, your priorities, your patterns. every week it gets more useful because it's learning you, not just executing a workflow.




@openclaw My agent won’t start. @openclaw you broke it. ProcessExitedBeforeReadyError: Process exited with code 127 before becoming ready. Waiting for: Port ##### (TCP) is the error @Cloudflare is giving me… nooo 🫨 🦞







For those unaware, SpaceX has already shifted focus to building a self-growing city on the Moon, as we can potentially achieve that in less than 10 years, whereas Mars would take 20+ years. The mission of SpaceX remains the same: extend consciousness and life as we know it to the stars. It is only possible to travel to Mars when the planets align every 26 months (six month trip time), whereas we can launch to the Moon every 10 days (2 day trip time). This means we can iterate much faster to complete a Moon city than a Mars city. That said, SpaceX will also strive to build a Mars city and begin doing so in about 5 to 7 years, but the overriding priority is securing the future of civilization and the Moon is faster.